-
混合策略改进的麻雀搜索算法-附代码
混合策略改进的麻雀搜索算法
摘要:针对麻雀搜索算法存在的迭代过程中种群多样性减少、、容易陷入局部最优以及收敛速度慢等问题,提出混合策略改进的麻雀搜索算法(MSSSA)。首先,利用Circle映射初始化麻雀个体位置,增加初始种群的多样性;其次、结合蝴蝶优化算法(BOA)中蝴蝶飞行方式改进发现者的位置更新策略,增强算法全局探索能力;然后,采用逐维变异方法对个体位置进行扰动,提升算法跳出局部最优的能力;1.麻雀优化算法
基础麻雀算法的具体原理参考,我的博客:https://blog.csdn.net/u011835903/article/details/108830958
2. 改进麻雀算法
2.1 Circle 混沌初始化策略
麻雀搜索算法对种群进行初始化时, 采用的是随机生 成的方式, 这种方式会使得麻雀种群分布不均匀, 影响后 期的迭代寻优。而混沌映射具有随机性、遍历性和规律性 等特点 [ 8 ] { }^{[8]} [8], 可以利用混沌序列对麻雀个体的位置进行初始 化。目前常用来初始化种群的混沌映射有 Logistic 映射、 Tent 映射、Circle 映射等, 其分布直方图如图 1、2、3 所 示。然而杨迪雄 [ 9 ] { }^{[9]} [9] 等学者指出 Logistic 映射在 [ 0 , 1 ] [0,1] [0,1] 范围内 呈切比春夫型分布, 即在 [ 0 , 0.1 ] [0,0.1] [0,0.1] 和 [ 0.9 , 1 ] [0.9,1] [0.9,1] 范围内取值概率 较高, 在 [ 0.1 , 0.9 ] [0.1,0.9] [0.1,0.9] 范围内取值概率较低, 这种不均匀侏对 明 Tent 映射的分布更加均匀, 但存在小周期和不稳定周 期, 容易陷入不动点; 而 Circle 映射更加稳定且具有与 Tent 映射相似的均匀性 [ 11 ] { }^{[11]} [11], 因此本文采用 Circle 混沌映射 对麻雀种群进行初始化, 其表达式如下式:
x i + 1 = m o d ( x i + 0.2 − ( 0.5 2 π ) sin ( 2 π ∗ x i ) , 1 ) (4) x_{i+1}=\bmod \left(x_i+0.2-\left(\frac{0.5}{2 \pi}\right) \sin \left(2 \pi * x_i\right), 1\right)\tag{4} xi+1=mod(xi+0.2−(2π0.5)sin(2π∗xi),1)(4)
其中 i i i 表示维度。2.2 蝴蝶优化策略
B O A \mathrm{BOA} BOA 是受到蝴蝶在受食和求偶过程中, 通过嗅觉来 辨别方向的启发所提出的群智能算法。在迭代时, 当蝴蝶 可以闻到来自其他蝴蝶的气味时, 它将朝着气味最浓的方 向移动, 该阶段被称为全局搜索阶段; 当蝴蝶不能从周围 嗅到味道是, 它将随机移动, 该阶段被称为局部搜索阶段。 其两阶段的位置更新方式如公式 (5) 和公式 (6) 所示:
X i t + 1 = X i t + ( r 2 ∗ X gbest − X i t ) ∗ f i (5) X_i^{t+1}=X_i^t+\left(r^2 * X_{\text {gbest }}-X_i^t\right) * f_i\tag{5} Xit+1=Xit+(r2∗Xgbest −Xit)∗fi(5)
X i t + 1 = X i t + ( r 2 ∗ X j t − X k t ) ∗ f i (6) X_i^{t+1}=X_i^t+\left(r^2 * X_j^t-X_k^t\right) * f_i\tag{6} Xit+1=Xit+(r2∗Xjt−Xkt)∗fi(6)
其中, X i t X_i^t Xit 是第 t t t 次迭代过程中第 i i i 只蝴蝶的位置, X gbest X_{\text {gbest }} Xgbest 是 当前迭代的全局最优解, f i f_i fi 表示第 i i i 只蝴蝶的发出的气味, 其取值大小取决于适应度的大小, r ∈ [ 0 , 1 ] r \in[0,1] r∈[0,1] 为随机数。
根据 S S A \mathrm{SSA} SSA 算法发现者位置更新公式可知, 当 R 2 < S T R_2R2<ST时, 发现者的每一维都在变小并收敛于 0 , 当 R 2 ≥ S T R_2 \geq S T R2≥ST 时,发现者会按照正态分布随机移动到当前位置。这样一来算 法在迭代初就会出现收敛于 0 点以及向全局最优解靠近 的趋势, 容易导致算法出现早熟收敛, 陷入局部最优。因 此, 本文引入 BOA 的全局搜索阶段位置更新策略改进 SSA 中发现者的位置更新公式, 改进后的位置更新方式如 公式 (7) 所示:
X i , j t + 1 = { X i j t + ( r 2 ∗ X best t − X i j t ) ∗ f i , R 2 < S T X i , j t + Q ⋅ L , R 2 ≥ S T (7) X_{i, j}^{t+1}=\left\{\right. \tag{7} Xi,jt+1={Xijt+(r2∗Xbest t−Xijt)∗fi,R2<STXi,jt+Q⋅L,R2≥ST(7)X i j t + ( r 2 ∗ X best t − X i j t ) ∗ f i , R 2 < S T X i , j t + Q ⋅ L , R 2 ≥ S T
改进后的位置更新公式中, 一方面, 在每一次迭代时麻雀 个体都会与最优个体进行信息交流, 以便充分利用当前最 优解的信息, 改善了原算法中缺乏个体间信息交流的缺陷; 另一方面, BOA 的引入在一定程度上扩大了搜索空间, 改进前后发现者的更新策略如图 4、5 所示。然而, 一味 的扩大搜索空间并不能保证提升算法的全局寻优能力, 还 需要对搜索空间的扩展幅度进行一定的控制。本文受到文 献[12]中随机缩小搜索空间策略的启发, 提出一种自适应 缩小搜索空间的策略; 通过控制搜索空间的上下限, 将搜 索空间限制在一定范围内, 加快种群收敛速度。其具体方 式如下:
X j , l b = max ( X j , min , X best , j t − r t ∗ ( X j , max − X j , min ) ) ( 8 ) X j , u b = min ( X j , max , X best , j t + r t ∗ ( X j , max − X j , min ) ) ( 9 ) r t = t / iter max ( 10 )Xj,lb=max(Xj,min,Xbest ,jt−rt∗(Xj,max−Xj,min))(8)Xj,ub=min(Xj,max,Xbest ,jt+rt∗(Xj,max−Xj,min))(9)rt=t/ iter max(10)X j , l b = max ( X j , min , X best , j t − r t ∗ ( X j , max − X j , min ) ) ( 8 ) X j , u b = min ( X j , max , X best , j t + r t ∗ ( X j , max − X j , min ) ) ( 9 ) r t = t / iter max ( 10 )
其中, X j , l b 、 X j , u b X_{j, l b} 、 X_{j, u b} Xj,lb、Xj,ub 分别为第 j j j 维的搜索下限、上限, X j , m i n X_{j, m i n} Xj,min 、 X j , m a x X_{j, m a x} Xj,max 分别为目前第 j j j 维的最小值、最大值, X b e s t , j t X_{b e s t, j}^t Xbest,jt 代表当 前全局最优个体在第 j j j 维的位置, r t r_t rt 为空间缩小系数。在迭 代过程中随着空间缩小系数的增大, 搜索空间在全局最优 个体的指引下不断缩小; 这不仅控制了搜索空间的扩展幅 度, 也提高了算法的收敛速度。2.3 逐维变异策略
在基本麻雀搜索算法中, 发现者、加入者和侦察者的 位置更新方式分别如公式(1)(2)(3)所示, 发现者在 R 2 < S T R_2
R2<ST时的位置更新方式存在逐维减小并最终收敛于 0 的问题; 加入者在 i ≤ N / 2 i \leq N / 2 i≤N/2 时会随机更新到当前最优位置的附近, 且每一维距最优位置的方差不断减小; 侦察者在 f i ≠ f g f_i \neq f_g fi=fg 时 会逃离到当前位置与最优位置附近, 其值收敛于最优解。 因此, 如果当前最优位置为局部最优, 那么麻雀种群会集 中在局部最优位置进行搜索, 降低种群多样性, 且难以跳 出局部最优。针对这一问题, 一般采用变异操作对个体进 行干扰以增加种群多样性, 跳出局部最优。最常用的手段 是通过高斯变异算子、柯西变异算子等对所有维度进行同 时变异, 但是对于高维函数来说会存在维间干扰问题 [ 13 ] { }^{[13]} [13], 即某些维度变异效果较差, 且覆盖了变异效果较好的维度, 最终导致变异效果不佳, 进而影响算法的收敛速度和精度。 采用逐维变异策略则可以有效避免维间干扰问题 [ 14 ] { }^{[14]} [14], 从而 提高变异解的质量。
本文采用自适应 t \mathrm{t} t 分布变异算子对最优个体进行变异, 主要是由于 t \mathrm{t} t 分布综合了柯西分布和高斯分布的特点, 根 据参数自由度 n n n 的大小, 其分布曲线表现出不同的形态。 t ( n → ∞ ) → N ( 0 , 1 ) t(n \rightarrow \infty) \rightarrow N(0,1) t(n→∞)→N(0,1), 一般 n ≥ 30 n \geq 30 n≥30 两者偏离可以忽略不记, t ( n = 1 ) = C ( 0 , 1 ) t(n=1)=C(0,1) t(n=1)=C(0,1), 其中 N ( 0 , 1 ) N(0,1) N(0,1) 为高斯分布, C ( 0 , 1 ) C(0,1) C(0,1) 为柯 西分布。换言之标准高斯分布和柯西分布是 t \mathrm{t} t 分布的两个 边界特例分布 [ 15 ] { }^{[15]} [15] 。
变异操作的结果具有不确定性, 若对所有个体均进行 逐维变异操作必然会增加计算量且降低算法的搜索效率, 因此本文仅对最优个体进行变异, 一方面充分利用最优个 体的信息, 另一方面增加种群多样性, 扩大搜索范围。
逐维变异策略的具体实现方式为: 设搜索空间具为 d \mathrm{d} d 维, 当前全局最优解为 X best = X best 1 , X best 2 , ⋯ X best d X_{\text {best }}=X_{\text {best }}^1, X_{\text {best }}^2, \cdots X_{\text {best }}^d Xbest =Xbest 1,Xbest 2,⋯Xbest d, 逐维变异后得到的新解为 X n e w = X new 1 X new 2 ⋯ X new d X_{n e w}=X_{\text {new }}^1 X_{\text {new }}^2 \cdots X_{\text {new }}^d Xnew=Xnew 1Xnew 2⋯Xnew d, 计算方 式如下:
X new d = X best d + X best d ⋅ t ( iter ) ( 11 ) X_{\text {new }}^d=X_{\text {best }}^d+X_{\text {best }}^d \cdot t(\text { iter })(11) Xnew d=Xbest d+Xbest d⋅t( iter )(11)
其中, iter为当前迭代次数, t t t (iter) 是自由度参数为 t t t 的 t分布。所提更新公式在 X best d X_{\text {best }}^d Xbest d 的基础上, 增加了随机干扰项 X best d ⋅ t ( X_{\text {best }}^d \cdot t( Xbest d⋅t( iter ), 既充分利用了当前位置信息, 又增加了随 机干扰信息, 有利于算法跳出局部最优; 而且随着迭代次 数iter增加, t 分布逐渐向高斯分布靠拢, 有利于增强算法的收敛速度; 同时, 克服了高维问题下的维间干扰问题。MSSSA 的具体执行步骤如下:
Step1 利用 Circle 混沌映射初始化种群并设置各个参 数;
Step2 计算麻雀个体的适应度值并排序, 找出最优适 和最差适应度值及其对应的位置;
Step3 从位置较优的麻雀种选出部分作为发现者, 按 照公式 (7) 进行位置更新, 并以公式 (8)、(9)、(10) 对其搜索空间进行限制;
Step4 剩下的麻雀作为加入者, 并按照公式 (2) 进行 位置更新;
Step5 随机从整个种群中选出部分麻雀作为侦察者, 并按照公式(3)进行位置更新;
Step6 计算更新后的整个麻雀种群的适应度, 并找到 全局最优麻雀, 对其进行逐维变异;
Step7 判断是否达到结束条件, 若是, 则进行下一步, 否则跳转䙵 Step2;
Step8 程序结束, 输出最优解。3.实验结果
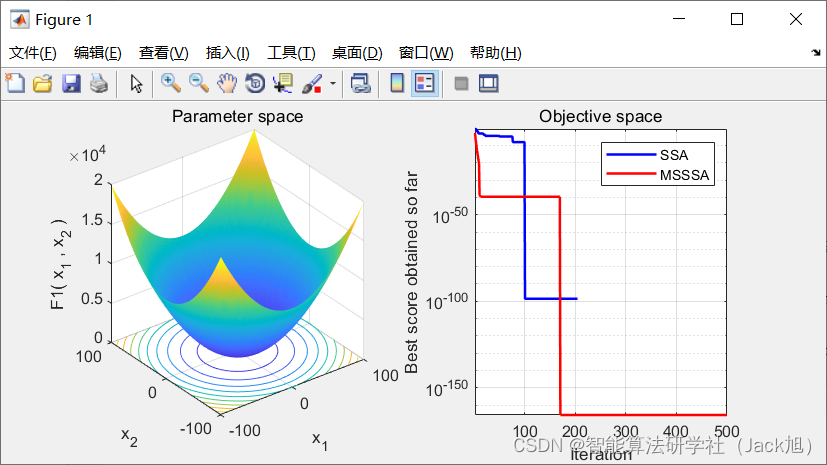
4.参考文献
[1]张伟康,刘升,任春慧.混合策略改进的麻雀搜索算法[J/OL].计算机工程与应用:1-12[2021-08-05].http://kns.cnki.net/kcms/detail/11.2127.TP.20210721.0848.002.html.
5.Matlab代码
6.Python代码
-
相关阅读:
分享金媒v10.3开源系统中CRM线下客户管理系统使用指南和小程序上架细分流程
280049flash guide中文
C++征途 --- 内建函数对象
sql开发学习(1)之group by,left join
STM32CubeMX和STM32F4
校招程序员无项目经验如何破局
su root提示认证失败,无法sudo,锁屏后提示密码不对
LeetCode 周赛上分之旅 #43 计算机科学本质上是数学吗?
操作系统:虚拟内存
Android自定义控件
- 原文地址:https://blog.csdn.net/u011835903/article/details/126926241