-
统计学习方法学习笔记-07-支持向量机03
包含对三种支持向量机的介绍,包括线性可分支持向量机,线性支持向量机和非线性支持向量机,包含核函数和一种快速学习算法-序列最小最优化算法SMO。
非线性支持向量机与核函数
核技巧
非线性分类问题
给定一个训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T = \{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\} T={(x1,y1),(x2,y2),⋯,(xN,yN)},其中 x i x_i xi属于输入空间, x i ∈ X = R n , y i ∈ Y = { − 1 , + 1 } , i = 1 , 2 , ⋯ , N x_i \in \mathcal{X} = R^n,y_i \in \mathcal{Y} = \{-1,+1\},i = 1,2,\cdots,N xi∈X=Rn,yi∈Y={−1,+1},i=1,2,⋯,N,如果可以用 R n R^n Rn中的一个超曲面将正负例正确分开,则称这个问题为非线性可分问题
用线性分类方法求解非线性问题分为两步,首先使用一个变换将原空间的数据映射到新空间,然后在新空间里用线性分类方法从训练数据中学习分类模型,基本想法就是通过一个非线性变换将输入空间对应于一个特征空间核函数的定义
设 X \mathcal{X} X是输入空间(欧式空间 R n R^n Rn的子集或离散集合),又设 H \mathcal{H} H为特征空间(希尔伯特空间),如果存在一个从 X \mathcal{X} X到 H \mathcal{H} H的映射:
ϕ ( x ) : X → H \phi(x):\mathcal{X} \rightarrow \mathcal{H} ϕ(x):X→H
使得对所有 x , z ∈ X x,z \in \mathcal{X} x,z∈X,函数 K ( x , z ) K(x,z) K(x,z)满足条件:
K ( x , z ) = ϕ ( x ) ⋅ ϕ ( z ) K(x,z) = \phi(x) \cdot \phi(z) K(x,z)=ϕ(x)⋅ϕ(z)
则称 K ( x , z ) K(x,z) K(x,z)为核函数, ϕ ( x ) \phi(x) ϕ(x)为隐射函数,式中 ϕ ( x ) ⋅ ϕ ( z ) \phi(x) \cdot \phi(z) ϕ(x)⋅ϕ(z)是两者的内积,核技巧的想法是,在学习与预测中只定义核函数 K ( x , z ) K(x,z) K(x,z),而不显示地定义隐射函数 ϕ \phi ϕ,可以看到,对于给定的核 K ( x , z ) K(x,z) K(x,z),特征空间 H \mathcal{H} H和隐射函数 ϕ \phi ϕ的取法并不唯一,可以取不同的特征空间,即便是在同一特征空间里也可以取不同的映射核技巧在支持向量机中的应用
在线性支持向量机的对偶问题中,无论是目标函数还是决策函数都只涉及输入实例与实例之间的内积
1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i \frac{1}{2}\sum_{i = 1}^N\sum_{j = 1}^N\alpha_i\alpha_jy_iy_j(x_i \cdot x_j) - \sum_{i = 1}^N\alpha_i 21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαi
在对偶问题的目标函数中的内积 x i ⋅ x j x_i \cdot x_j xi⋅xj可以用核函数 K ( x , z ) = ϕ ( x ) ⋅ ϕ ( z ) K(x,z) = \phi(x) \cdot \phi(z) K(x,z)=ϕ(x)⋅ϕ(z)来代替,此时对偶问题的目标函数为:
W ( α ) = 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i W(\alpha) = \frac{1}{2}\sum_{i = 1}^N\sum_{j = 1}^N\alpha_i\alpha_jy_iy_jK(x_i,x_j) - \sum_{i = 1}^N\alpha_i W(α)=21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαi
同样,分类决策中的内积也可以用核函数代替:
f ( x ) = s i g n ( ∑ i = 1 N s α i ∗ y i K ( x i , x ) + b ∗ ) f(x) = sign\left(\sum_{i = 1}^{N_s}\alpha_i^*y_iK(x_i , x) + b^*\right) f(x)=sign(i=1∑Nsαi∗yiK(xi,x)+b∗)
这等价于经过映射函数 ϕ \phi ϕ将原来的输入空间变换到一个新的特征空间,将输入空间的内积 x i ⋅ x j x_i \cdot x_j xi⋅xj变换为特征空间中的内积 ϕ ( x i ) ⋅ ϕ ( x j ) \phi(x_i) \cdot \phi(x_j) ϕ(xi)⋅ϕ(xj)正定核
目的:函数 K ( x , z ) K(x,z) K(x,z)成为核函数的条件
正定核的充要条件
设 K : X × X → R K:\mathcal{X} \times \mathcal{X} \rightarrow R K:X×X→R是对称函数,则 K ( x , z ) K(x,z) K(x,z)为正定核的充要条件是对任意 x i ∈ X , i = 1 , 2 , ⋯ , m , K ( x , z ) x_i \in \mathcal{X},i = 1,2,\cdots,m,K(x,z) xi∈X,i=1,2,⋯,m,K(x,z)对应的Gram矩阵:
K = [ K ( x i , x j ) ] m × m K = [K(x_i,x_j)]_{m \times m} K=[K(xi,xj)]m×m
是半正定矩阵正定核的等价定义
设 X ⊂ R n , K ( x , z ) \mathcal{X} \subset R^n,K(x,z) X⊂Rn,K(x,z)是定义在 X × X \mathcal{X} \times \mathcal{X} X×X上的对称函数,如果对任意的 x 1 , x 2 , ⋯ , x m ∈ X , K ( x , z ) x_1,x_2,\cdots,x_m \in \mathcal{X},K(x,z) x1,x2,⋯,xm∈X,K(x,z)关于 x 1 , x 2 , ⋯ , x m x_1,x_2,\cdots,x_m x1,x2,⋯,xm的Gram矩阵 K = [ K ( x i , x j ) ] m × m K = [K(x_i,x_j)]_{m \times m} K=[K(xi,xj)]m×m是半正定矩阵,则称 K ( x , z ) K(x,z) K(x,z)是正定核。
常用核函数
多项式核函数polynomial kernel function
此时对应的支持向量机是一个 p p p次多项式分类器
K ( x , z ) = ( x ⋅ z + 1 ) p K(x,z) = (x \cdot z + 1)^p K(x,z)=(x⋅z+1)p高斯核函数gaussain kernel function
此时对应的支持向量机是高斯径向基函数分类器
K ( x , z ) = e x p ( − ∣ ∣ x − z ∣ ∣ 2 2 σ 2 ) K(x,z) = exp\left(-\frac{||x - z||^2}{2\sigma^2}\right) K(x,z)=exp(−2σ2∣∣x−z∣∣2)非线性支持向量分类机
非线性支持向量机学习算法
输入:训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T = \{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\} T={(x1,y1),(x2,y2),⋯,(xN,yN)},其中 x i ∈ X = R n , y i ∈ Y = { + 1 , − 1 } , i = 1 , 2 , ⋯ , N x_i \in \mathcal{X} = R^n,y_i \in \mathcal{Y} = \{+1,-1\},i = 1,2,\cdots,N xi∈X=Rn,yi∈Y={+1,−1},i=1,2,⋯,N
输出:分类决策函数- 选择适当的核函数
K
(
x
,
z
)
K(x,z)
K(x,z)和惩罚参数
C
>
0
C \gt 0
C>0,构造并求解约束最优化问题求得最优解
α
∗
=
(
α
1
∗
,
α
2
∗
,
⋯
,
α
N
∗
)
T
\alpha^* = (\alpha^*_1,\alpha^*_2,\cdots,\alpha_N^*)^T
α∗=(α1∗,α2∗,⋯,αN∗)T
m i n α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i s . t . ∑ i = 1 N α i y i = 0 0 ≤ α i ≤ C , i = 1 , 2 , ⋯ , Nαmin s.t. 21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαii=1∑Nαiyi=00≤αi≤C,i=1,2,⋯,Nm i n α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i s . t . ∑ i = 1 N α i y i = 0 0 ≤ α i ≤ C , i = 1 , 2 , ⋯ , N - 选择
α
∗
\alpha^*
α∗的一个分量
0
<
α
j
∗
<
C
0 \lt \alpha_j^* \lt C
0<αj∗<C,计算:
b ∗ = y j − ∑ i = 1 N α i ∗ y i K ( x i , x j ) b^* = y_j - \sum_{i = 1}^N\alpha_i^*y_iK(x_i, x_j) b∗=yj−i=1∑Nαi∗yiK(xi,xj) - 求得决策函数:
f ( x ) = s i g n ( ∑ i = 1 N α i ∗ y i K ( x , x i ) + b ∗ ) f(x) = sign\left(\sum_{i = 1}^N\alpha_i^*y_iK(x, x_i) + b^*\right) f(x)=sign(i=1∑Nαi∗yiK(x,xi)+b∗)
序列最小最优化算法(SMO算法)
sequential minimal optimization
目的:当训练样本容量很大的时候,快速实现支持向量机学习
SMO算法要解的问题如下:
m i n α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i s . t . ∑ i = 1 N α i y i = 0 0 ≤ α i ≤ C , i = 1 , 2 , ⋯ , Nαmin s.t. 21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαii=1∑Nαiyi=00≤αi≤C,i=1,2,⋯,Nm i n α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i s . t . ∑ i = 1 N α i y i = 0 0 ≤ α i ≤ C , i = 1 , 2 , ⋯ , N
变量是 α i \alpha_i αi,算法是一种启发式算法,
基本思路如下,如果所有变量的解都满足此最优化问题的KKT条件,那么此时最优化问题的解就得到了,因为KKT条件是最优化问题的充分必要条件,否则选择两个变量,固定其他变量,针对这两个变量构建一个二次规划问题,这个二次规划问题关于这两个变量的解应该更加接近原始二次规划问题的解,因为这会使原始二次规划问题的目标函数值变小,
重要的是,这时子问题可以通过解析方法求解,这样就可以大大提高整个算法的计算速度,
子问题有两个变量,一个是违反KKT条件最严重的那一个,另一个由约束条件自动确定,假设 α 1 , α 2 \alpha_1,\alpha_2 α1,α2为两个变量, α 3 , α 4 , ⋯ , α N \alpha_3,\alpha_4,\cdots,\alpha_N α3,α4,⋯,αN固定,那么由约束不等式 ∑ i = 1 N α i y i = 0 \sum_{i = 1}^N\alpha_iy_i = 0 ∑i=1Nαiyi=0和 y 1 2 = 1 y_1^2 = 1 y12=1可知:
α 1 = − y 1 ∑ i = 2 N α i y i \alpha_1 = -y_1\sum_{i = 2}^N\alpha_iy_i α1=−y1i=2∑Nαiyi
整个SMO算法包含两个部分:求解两个变量二次规划的解析方法和选择变量的启发式方法两个变量二次规划的求解方法
不失一般性,假设 α 1 , α 2 \alpha_1,\alpha_2 α1,α2为两个变量, α 3 , α 4 , ⋯ , α N \alpha_3,\alpha_4,\cdots,\alpha_N α3,α4,⋯,αN固定,省略不含 α 1 , α 2 \alpha_1,\alpha_2 α1,α2的常数项,于是最优化问题可以写为:
m i n α 1 , α 2 W ( α 1 , α 2 ) = 1 2 K 11 α 1 2 + 1 2 K 22 α 2 2 + y 1 y 2 K 12 α 1 α 2 − ( α 1 + α 2 ) + y 1 α 1 ∑ i = 3 N y i α i K i 1 + y 2 α 2 ∑ i = 3 N y i α i K i 2 s . t . α 1 y 1 + α 2 y 2 = − ∑ i = 3 N y i α i = ζ 0 ≤ α i ≤ C , i = 1 , 2α1,α2min s.t. W(α1,α2)=21K11α12+21K22α22+y1y2K12α1α2−(α1+α2)+y1α1i=3∑NyiαiKi1+y2α2i=3∑NyiαiKi2α1y1+α2y2=−i=3∑Nyiαi=ζ0≤αi≤C,i=1,2m i n α 1 , α 2 W ( α 1 , α 2 ) = 1 2 K 11 α 1 2 + 1 2 K 22 α 2 2 + y 1 y 2 K 12 α 1 α 2 − ( α 1 + α 2 ) + y 1 α 1 ∑ i = 3 N y i α i K i 1 + y 2 α 2 ∑ i = 3 N y i α i K i 2 s . t . α 1 y 1 + α 2 y 2 = − ∑ i = 3 N y i α i = ζ 0 ≤ α i ≤ C , i = 1 , 2
约束可以用二维空间中的图形表示:
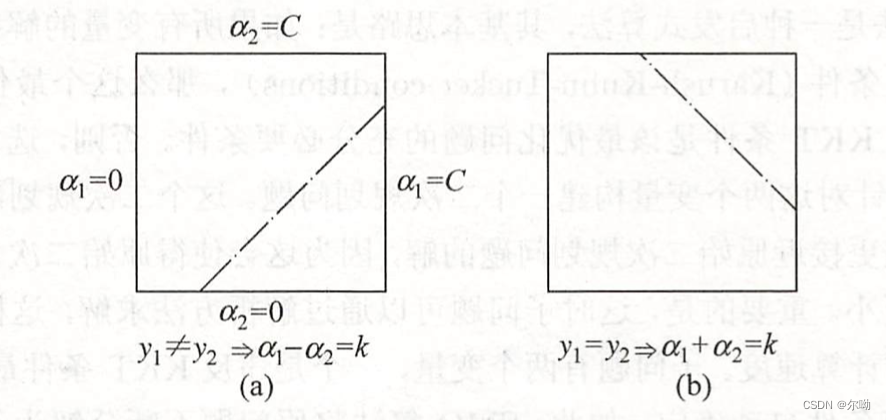
不等式约束使得 ( α 1 , α 2 ) (\alpha_1,\alpha_2) (α1,α2)在盒子 [ 0 , C ] × [ 0 , C ] [0,C] \times [0,C] [0,C]×[0,C]中,等式约束使得 ( α 1 , α 2 ) (\alpha_1,\alpha_2) (α1,α2)在平行于盒子对角线的直线上,因此要求的是目标函数在一条平行于对角线的线段上的最优值,这使得两个变量的最优化问题成为实质上的单变量的最优化问题,此时考虑 α 2 \alpha_2 α2的最优化问题
最优值 α 2 n e w \alpha_2^{new} α2new的取值范围需要满足条件:
L ≤ α 2 n e w ≤ H L \leq \alpha_2^{new} \leq H L≤α2new≤H
其中 L , H L,H L,H是 α 2 n e w \alpha_2^{new} α2new所在的对角线段端点的界:-
y
1
≠
y
2
y_1 \neq y_2
y1=y2
L = m a x ( 0 , α 2 o l d − α 1 o l d ) , H = m i n ( C , C + α 2 o l d − α 1 o l d ) L = max(0,\alpha_2^{old} - \alpha_1^{old}),H = min(C,C + \alpha_2^{old} - \alpha_1^{old}) L=max(0,α2old−α1old),H=min(C,C+α2old−α1old) -
y
1
=
y
2
y_1 = y_2
y1=y2
L = m a x ( 0 , α 2 o l d + α 1 o l d − C ) , H = m i n ( C , α 2 o l d + α 1 o l d ) L = max(0, \alpha_2^{old} + \alpha_1^{old} - C),H = min(C,\alpha_2^{old} + \alpha_1^{old}) L=max(0,α2old+α1old−C),H=min(C,α2old+α1old)
假设问题的初始可行解为 α 1 o l d , α 2 o l d \alpha_1^{old},\alpha_2^{old} α1old,α2old,最优解为 α 1 n e w , α 2 n e w \alpha_1^{new},\alpha_2^{new} α1new,α2new,并且假设沿着约束方向未经剪辑时 α 2 \alpha_2 α2的最优解为 α 2 n e w , u n c \alpha_2^{new,unc} α2new,unc
先记:
g ( x ) = ∑ i = 1 N α i y i K ( x i , x ) + b E i = g ( x i ) − y i = ( ∑ i = 1 N α i y i K ( x i , x ) + b ) − y i g(x) = \sum_{i = 1}^N\alpha_iy_iK(x_i,x) + b \\ E_i = g(x_i) - y_i = \left(\sum_{i = 1}^N\alpha_iy_iK(x_i,x) + b\right) - y_i g(x)=i=1∑NαiyiK(xi,x)+bEi=g(xi)−yi=(i=1∑NαiyiK(xi,x)+b)−yi
最优化问题沿着约束方向未经剪辑时的解为:
α 2 n e w , u n c = α 2 o l d + y 2 ( E 1 − E 2 ) η \alpha_2^{new,unc} = \alpha_2^{old} + \frac{y_2(E_1 - E_2)}{\eta} α2new,unc=α2old+ηy2(E1−E2)
其中:
η = K 11 + K 22 − 2 K 12 = ∣ ∣ Φ ( x 1 ) − Φ ( x 2 ) ∣ ∣ 2 \eta = K_{11} + K_{22} - 2K_{12} = ||\Phi(x_1) - \Phi(x_2)||^2 η=K11+K22−2K12=∣∣Φ(x1)−Φ(x2)∣∣2
经剪辑后 α 2 \alpha_2 α2的解是:
α 2 n e w = { H , α 2 n e w , u n c > H α 2 n e w , u n c , L ≤ α 2 n e w , u n c ≤ H L , α 2 n e w , u n c < L \alpha_2^{new} =α2new=⎩ ⎨ ⎧H,α2new,unc,L,α2new,unc>HL≤α2new,unc≤Hα2new,unc<L{ H , α 2 n e w , u n c > H α 2 n e w , u n c , L ≤ α 2 n e w , u n c ≤ H L , α 2 n e w , u n c < L
由 α 2 n e w \alpha_2^{new} α2new求得 α 1 n e w \alpha_1^{new} α1new是:
α 1 n e w = α 1 o l d + y 1 y 2 ( α 2 o l d − α 2 n e w ) \alpha_1^{new} = \alpha_1^{old} + y_1y_2(\alpha_2^{old} - \alpha_2^{new}) α1new=α1old+y1y2(α2old−α2new)变量的选择方法
SMO算法在每个子问题中选择两个变量优化,其中至少一个变量是违反KKT条件。
- 第1个变量的选择
选择第一个变量的过程为外层循环,在训练样本中选取违反KKT条件最严重的点,检查样本点 ( x i , y i ) (x_i,y_i) (xi,yi)满足KKT条件的方法:
α i = 0 ⇔ y i g ( x i ) ≥ 1 0 < α i < C ⇔ y i g ( x i ) = 1 α i = C ⇔ y i g ( x i ) ≤ 1αi=00<αi<Cαi=C⇔yig(xi)≥1⇔yig(xi)=1⇔yig(xi)≤1α i = 0 ⇔ y i g ( x i ) ≥ 1 0 < α i < C ⇔ y i g ( x i ) = 1 α i = C ⇔ y i g ( x i ) ≤ 1
其中 g ( x i ) = ∑ j = 1 N α j y j K ( x i , x j ) + b g(x_i) = \sum_{j = 1}^N\alpha_jy_jK(x_i,x_j) + b g(xi)=∑j=1NαjyjK(xi,xj)+b,在检验过程中,首先遍历所有满足条件 0 < α i < C 0 \lt \alpha_i \lt C 0<αi<C的样本点,即在间隔边界上的支持向量点,检查是否满足KKT条件,然后检查整个训练数据集 - 第2个变量的选择
在找到第一个变量 α 1 \alpha_1 α1的基础上寻找 α 2 \alpha_2 α2,已知 α 2 n e w \alpha_2^{new} α2new依赖于 ∣ E 1 − E 2 ∣ |E_1 - E_2| ∣E1−E2∣,而且 α 1 \alpha_1 α1确定,所以 E 1 E_1 E1确定,如果 E 1 E_1 E1是正的,选择最小的 E i E_i Ei作为 E 2 E_2 E2,否则选择最大的 E i E_i Ei作为 E 2 E_2 E2,如果选择的 α 2 \alpha_2 α2不能使目标函数有足够的下降,那么采用启发式规则继续选择 α 2 \alpha_2 α2试用,如果还是找不到合适的 α 2 \alpha_2 α2,就重新找另外的 α 1 \alpha_1 α1 - 计算阈值 b b b和差值 E i E_i Ei
SMO算法
输入:训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T = \{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\} T={(x1,y1),(x2,y2),⋯,(xN,yN)},其中 x i ∈ X = R n , y i ∈ Y = { + 1 , − 1 } , i = 1 , 2 , ⋯ , N x_i \in \mathcal{X} = R^n,y_i \in \mathcal{Y} = \{+1,-1\},i = 1,2,\cdots,N xi∈X=Rn,yi∈Y={+1,−1},i=1,2,⋯,N,精度 ε \varepsilon ε
输出:近似解 α ^ \hat{\alpha} α^- 取初值 α ( 0 ) = 0 , k = 0 \alpha^{(0)} = 0,k = 0 α(0)=0,k=0;
- 选取优化变量 α 1 ( k ) , α 2 ( k ) \alpha_1^{(k)},\alpha_2^{(k)} α1(k),α2(k),解析求解两个变量的最优化问题,过程见上上小结,求解得到最优解 α 1 ( k + 1 ) , α 2 ( k + 1 ) \alpha_1^{(k + 1)},\alpha_2^{(k + 1)} α1(k+1),α2(k+1),更新 α \alpha α为 α ( k + 1 ) \alpha^{(k + 1)} α(k+1);
- 若在精度
ε
\varepsilon
ε范围内满足停机条件
∑ i = 1 N α i y i = 0 , 0 ≤ α i ≤ C , i = 1 , 2 , ⋯ , N y i ⋅ g ( x i ) { ≥ 1 , { x i ∣ α i = 0 } = 1 , { x i ∣ 0 < α i < C } ≤ 1 , { x i ∣ α i = C } \sum_{i = 1}^N\alpha_iy_i = 0,0 \leq \alpha_i \leq C,i = 1,2,\cdots,N \\ y_i \cdot g(x_i)i=1∑Nαiyi=0,0≤αi≤C,i=1,2,⋯,Nyi⋅g(xi)⎩ ⎨ ⎧≥1,=1,≤1,{xi∣αi=0}{xi∣0<αi<C}{xi∣αi=C}{ ≥ 1 , { x i | α i = 0 } = 1 , { x i | 0 < α i < C } ≤ 1 , { x i | α i = C }
其中 g ( x i ) = ∑ j = 1 N α j y j K ( x i , x j ) + b g(x_i) = \sum_{j = 1}^N\alpha_jy_jK(x_i,x_j) + b g(xi)=∑j=1NαjyjK(xi,xj)+b
则转第四步,否则令 k = k + 1 k = k + 1 k=k+1,转到第二步 - 取 α ^ = α ( k + 1 ) \hat{\alpha} = \alpha^{(k + 1)} α^=α(k+1)
- 选择适当的核函数
K
(
x
,
z
)
K(x,z)
K(x,z)和惩罚参数
C
>
0
C \gt 0
C>0,构造并求解约束最优化问题求得最优解
α
∗
=
(
α
1
∗
,
α
2
∗
,
⋯
,
α
N
∗
)
T
\alpha^* = (\alpha^*_1,\alpha^*_2,\cdots,\alpha_N^*)^T
α∗=(α1∗,α2∗,⋯,αN∗)T
-
相关阅读:
flutter 使用getx 框架系统日历 showDatePicker && selectTimeWidget 多语言切换终极解决方案
Django练习
7-9 HashSet 重写相应方法
springboot+vue项目基础开发(16)主页面布局
保险业SAP转型:奠定坚实的基础
压力传感器、液位传感器在消防中的使用
计算机毕业设计(附源码)python志愿者服务平台
基于JAVA-在线考试系统-计算机毕业设计源码+系统+数据库+lw文档+部署
九、计算机视觉-形态学基础概念
韦东山linux驱动开发学习【常更】
- 原文地址:https://blog.csdn.net/weixin_44994838/article/details/126921633