-
如何优♂雅地学习GDB调试
 🤣 爆笑教程 👉 《看表情包学Linux》👈 猛戳订阅 🔥
🤣 爆笑教程 👉 《看表情包学Linux》👈 猛戳订阅 🔥
 * * 不 在 家 ,一 个 人 寂 寞 ?打开牛客网,来一场题库厮杀!快乐算法,给你从未拥有的体验!从基础到大厂面试题应有尽有,更有攒劲的题解等你来看!猛戳跳转 👉 激 情 牛 客 刷 题 网
* * 不 在 家 ,一 个 人 寂 寞 ?打开牛客网,来一场题库厮杀!快乐算法,给你从未拥有的体验!从基础到大厂面试题应有尽有,更有攒劲的题解等你来看!猛戳跳转 👉 激 情 牛 客 刷 题 网 
💭 写在前面
本章我们将带着大家高雅的学一学令众多习惯图形化页面的朋友难受的 gdb 调试,这部分知识可以选择性学习学习,以后倘若遇到一些问题时能在 Linux 内简单调试,还是很香的。然后在讲讲 gcc 和 g++,系统讲解程序运行时的各个过程。
Ⅰ. GDB 调试
0x00 调试前的准备
我们先来创建一个用来演示 GCD 调试功能的目录:

既然要调试,我们就必须要有个代码,我们这里写一个数字累加的代码:

🚩 运行结果:

结果是5050,没有问题。如果我们代码出现了一些问题需要我们调试,我们就可以使用 gdb。
如果此时你出现了报错,说什么不支持 for 循环里面定义变量,你可以输入:
$ gcc hello.c -o hello -std=c990x01 Linux 默认集成环境
在你当前的代码目录下直接执行 gcb + 形成的可执行程序:
$ gdb [可执行程序]此时就进入了 gdb 的调试命令行中:

(如果想退出,直接按 quit 就可以退出了)
gcb 读取我们的 hello 程序时出现了 "没有调试符号被发现" 的警告:

这是什么意思呢?
我们的 gdb 中有一条命令叫做 list(简写成 l),但是我们输入后出现以下提示:

因为 —— 默认形成的可执行程序无法调试!!!
相信大家都知道,C语言的发布方式有两种,一种是 debug 一种是 release。
我们在 VS 里面可以直接调的原因是,VS2019 的默认集成环境是 debug。
而在我们的 Linux 中的默认集成环境是 release,换言之,
在我们 Linux 中如果你想发布一个程序,可以直接发布,无需加任何选项。
但是如果你想调试,以 debug 形式发布,那么你就需要在编译时在后面添加一个 -g 选项:
$ gcc hello.c -o hello.g _g
🔺 总结:Linux 默认形成的可执行程序是动态链接且是 release 方式发布。
- 如果想静态链接,加 -static
- 如果想动态链接,加 -g
0x02 readelf 读取 ELF 文件信息
release 和 debug 的区别:你的可执行程序里本来就有调试信息, 只是 debug 中才有。
首先,这两个版本也都是可以运行的:

并且我要告诉你的是:debug 版本比 release 版本多几千个字节,这是什么?
毫无疑问,这些就是一个可执行程序的调试信息,它在 debug 版本中有所显现。
📚 如果你想看调试信息,你可以输入:
$ readelf -S [可执行程序] # 以段的形式读取可执行程序,用于显示读取ELF文件中信息💭 我们先看看 release 版的:

💭 我们再来读一读 debug 版的:

因为 debug 版本是能给你的可执行程序添加调试信息的,所以体积自然比 release 版本要大些。
所以我们调试的得是 debug 版本的可执行程序,预备工作全部做好,下面我们来正式学习 gdb。
0x03 显示代码 gcb(list)
现在我们是 debug 版本了,我们也顺理成章地能够使用前面我们说的 list 了。
- (gdb) list [n] # 显示代码,可带行号
- (gdb) list [function] # 显示带某函数的代码块
- (gdb) list [begin, end] # 显示区间内的代码
- ...
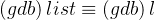
💭 操作演示:

一般在 VS 下调试的时候,除了让你看到代码,还会让你看到进行到了哪里,这里也是一样的。
你按下回车后,gdb 会自动记录你的上一条指令,直接按回车就是上一条命令:

(这么做就能把代码从第一行开始,将所有代码块逐个显示出来了)
0x04 断点
💭 假设我们想在下面代码的第15行处打个断点:

这要是放在 VS 下我们直接滑鼠选中对应行然后无脑按 F11 就行了。
 而在 gdb 下打断点的方式是用 breakpoint:
而在 gdb 下打断点的方式是用 breakpoint:(gdb) breakpoint [n] # 在第n行处打一个断点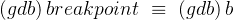
💭 操作演示:我们在代码第15行打个断点看看:

此时如果你想查看断点,可以使用 info 查看你打的断点:
(gdb) info b # 查看断点💭 操作演示:查看断点信息

我们再在第17行新增一个断点,此时我们就能看到两个断点了:

如果想要删除断点,在 VS 下我们直接再点以下小红点就搞定了:
 (图形化界面无疑是成功的)
(图形化界面无疑是成功的)但是在 gdb 中,我们需要知道要删除的断点的编号:
(gdb) d [Num] # 删除Num号断点💭 操作演示:删除1号断点(记不得要删除的断点的编号可以 info b)

此时 1 号断点已被成功删除,再次删除则会显示已经没有这个断点:

0x05 调试
准备开始调试,记得把刚才删除的断点再打回去,调试的指令如下:
(gdb) run # 开始调试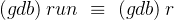
💭 操作演示:输入完 r 按回车开始调试:
 (此时就悬停在了第15行)
(此时就悬停在了第15行)如果我们把场上断点全部干掉了,此时按 r 调试程序就会直接跑完:
 (这和 VS 也是一样的)
(这和 VS 也是一样的)如果你想查看变量的内容,我们可以使用 print 命令:
(gdb) print [val]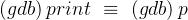
💭 操作演示:查看变量内容

💭 操作演示:逐语句
如果想逐语句执行(逐语句即一步一步往后走),逐语句指令如下:
(gdb) step # 逐语句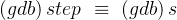

我们 s 两次后,此时走到了函数的调用处。此时如果你不想进入该函数,就不要再按 s 逐语句了。
此时我们应该逐过程执行,我们可以使用 next 命令:
(gdb) next # 逐过程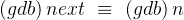
💭 操作演示:逐过程

0x06 监视
我们在 VS 中调试代码的时候,有时候要 细 ♂ 细 ♂ 观 ♂ 察 某个变量时,我们会打开监视窗口:

在 gdb 下我们就可以使用 display 常显示来监视:
- $ display [val] # 监视一个变量,每次停下来都显示它的值
- $ display [v1, v2, v3...] # 同时添加多个变量,用括号隔开
💭 操作演示:常显示 i 变量
当然,我们也可以同时监视多个值:
 (同时常显示三个变量)
(同时常显示三个变量)直接输入 display 可以查看监视列表:
$ display # 查看当前监视列表💭 操作演示:查看监视列表

如果想把某个变量从监视窗口移除,我们可以使用 undisplay:
$ undisplay [n] # 删除n号变量💭 操作演示:删除3号变量

0x07 跳转(until & c & finish)
我们调试的时候在文本特别大的时候我们有时候会跳转,VS 里我们可以直接拖动箭头跳转。
gdb 调试下我们可以使用 until 指令跳转到指定行:
$ until [n] # 跳转到指定行💭 操作演示:跳转到20行

如果想从一个断点跳转至另一个断点,我们可以使用 c:
$ c # 直接跳转到另一个断点有时候难免手贱不小心进了不想进入了函数,就比如不小心逐语句进了 printf 函数。
这个在 VS 下逐语句是不会进去的,但是在 Linux 下会进入,此时如果你反悔了象出来,
就可以输入 finish,它可以做到直接执行完成一个函数就停下来。
$ finish # 执行到当前函数返回,然后停下来等待命令0x08 对于 gdb 的态度
掌握上面单独介绍的 b、d、l、s、n、display、until、r、c、finish 其实就差不多了。
还有一些 gdb 的指令我们上面没有介绍,这里做一个整合:
- list/l 行号:显示binFile源代码,接着上次的位置往下列,每次列10行。
- list/l 函数名:列出某个函数的源代码。
- r 或 run:运行程序。
- n 或 next:单条执行。
- s或step:进入函数调用。
- break(b) 行号:在某一行设置断点。
- break 函数名:在某个函数开头设置断点。
- info break :查看断点信息。
- finish:执行到当前函数返回,然后挺下来等待命令。
- print(p):打印表达式的值,通过表达式可以修改变量的值或者调用函数。
- p 变量:打印变量值。
- set var:修改变量的值。
- continue(或c):从当前位置开始连续而非单步执行程序。
- run(或r):从开始连续而非单步执行程序。
- delete breakpoints:删除所有断点。
- delete breakpoints n:删除序号为n的断点。
- disable breakpoints:禁用断点。
- enable breakpoints:启用断点。
- info(或i) breakpoints:参看当前设置了哪些断点。
- display 变量名:跟踪查看一个变量,每次停下来都显示它的值。
- undisplay:取消对先前设置的那些变量的跟踪。
- until X行号:跳至X行。
- breaktrace(或bt):查看各级函数调用及参数。
- info(i) locals:查看当前栈帧局部变量的值。
- quit:退出gdb。
Ⅱ. gcc 和 g++
0x00 引入:在 Linux 中如何编写 C/C++ 程式?
💭 以下是 C 和 C++ 的 Hello,World 示例程序编译的方式:

- $ gcc [文件名] # 编译C
- $ g++ [文件名] # 编译C++
此外,如果你输入"g++ test.cpp" 时显示并没有这样的指令,可以安装一下:
sudo yum install -y gcc-c++我们知道,gcc 是不能用来编译 C++ 代码的,它只能用来编译 C 语言的代码:
- $ gcc test.cpp ❌
- $ gcc test.c ✅
 (尝试用 gcc 编译 C++ 代码)
(尝试用 gcc 编译 C++ 代码)但是, g++ 是可以用来编译 C 语言的,这个相信大家是可以理解的,因为 C++ 是 C 的超集:
- $ g++ test.c ✅
- $ g++ test.cpp ✅
0x01 程序的翻译过程
程序(文本)要转换成机器语言(二进制),翻译有以下四个步骤:
- ① 预处理
- ② 编译
- ③ 汇编
- ④ 链接
这个我们在前面已经讲过了,我们本节主要讲解预处理部分,并且对链接部分进行补充。
对于编译和汇编部分,本节我们只对他们做一个简单的讲解(当然并不是说它们不重要)
❓ 思考:我们知道文本要翻译成二进制的原因是计算机只认识二进制,那你有没有想过:
 为什么计算机只认识二进制?
为什么计算机只认识二进制?其实并不是计算机只认识二进制,而是计算机当中的各种硬件只认识二进制。
在计算机刚被设计的时候都是存储两派信息,常见的比如触发器这样的硬件设备,
实际上只能存储电信号的 "有无" 或者 "正负" 这样的概念,至于为什么选择二进制。
我再做一个补充,其实从计算机发明到现在,历史上也出现过其它进制的计算机。

比如苏联的三进制计算机,只不过二进制计算机更简单,最后称为主流了。
所以,我们的计算机只认识二进制,因为它的各种硬件都是二进制的。
💡 答案:组成计算机的各种组件,只认识二进制。
0x01 预处理过程
📚 预处理:a. 宏替换 b. 头文件展开 c. 去注释 d. 条件编译
Linux 的 gcc 是如何进行上面的过程的呢?我们先看预处理的过程。
💬 我们来修改一下 test.c 源文件,让它有头文件、宏、注释和条件编译:
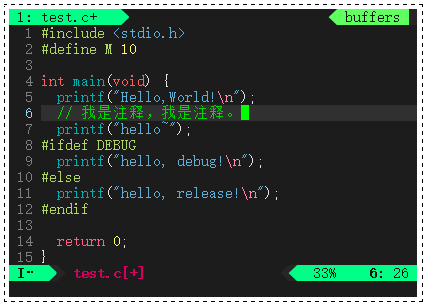
此时我们直接用 gcc 编译一下代码,"gcc + 要编译的文件" 默认生成的可执行程序叫 a.out。
顺便一提,如果你不想让生成的可执行程序为叫 a.out,你想指定名称,可以加上 -o 选项:

这样是直接一步到位地获得了可执行程序,可是我们现在想观察预处理,
也就是说我们只想让 gcc 完成预处理的操作,我们可以加上 "杠大易" 的选项。
- gcc -E test.c -o test.i
- # -E: 从现在开始给我进行程序的翻译,当预处理完成就停下来
- # -o test.i:将最后的结果写到 test.i 中

然后我们 gcc 打开 test.c,冒号进入底行模式后输入 vs test.i,就可以分屏观察:

给人最明显的感受就是 —— test.i 明显要比 test.c 大很多。
但实际上观察后发现代码反而比 test.i 要少很多,并且我们翻到开头可以发现有大量的引入:

我们写代码写的 .h 文件 .c 文件,当你编译的时候实际上是把你的 .h 代码全部拷贝到 .c 中的。
为了防止重复包含头文件,我们在《树锯结构》专栏还提到了用 #pragma once 防止重复包含。
观察 test.o 前面部分后我们发现 Linux 中 C语言标准头文件在 /usr/include 下,我们这就去看看:
$ ls /usr/include
一般都会安装在 usr/include 目录下,当然!不排除以后会出现安装在其他目录下的可能性。
现在你只需要记住:以前我们编写C语言代码时 #include
时,其实并不是说 #include 就一定能成功,前提是你平台必须得装了你引入的头文件,不然也没东西在你的源文件中展开。 当然,我们最熟悉的头文件莫过于 stdio.h:

📌 注意:编译器内部都必须通过一定的方式,知道你所包含的头文件所在的路径。
现在在回头想一想,为什么一个新的语法老的编译器不支持的问题。其根本原因是因为老的编译器配套的头文件和库,压根就没有这一套东西。我们在装 VS 编译器的时所谓的环境安装勾选 C/C++ 后,实际上就是在给你装 C语言 C++ 的头文件和库。
🔍 观察:我们再来比对一下它们的代码部分有什么差别:

此时,就完成了预处理的工作。
我们刚才的条件编译只保留了 release,现在我们如果 #define 出一个 DEBUG,
再重新编译打开比对,保留的就不是 "hello,release!" 而是 "hello, debug!" 了,这里就不演示了。
❓ 思考:程序进行完预处理操作后,还是C语言吗?💡 答案:仍然是C语言!你看这些代码你还认不认识,它当然还是C语言了。
换言之,这个预处理工作仅仅是为了让程序翻译的更顺畅,帮助我们做了一些文本替换处理操作而已。比如宏替换(当然,例子里面我不小心忘记了在代码中用到宏,所以自然前后也没有替换)、去掉给人读的注释(机器才懒得读你写的注释呢,跟它也没有半毛钱关系)、根据条件编译的结果把不要的选项去掉……最后它还是C语言,只不过时一份干净的C语言。你可以理解为 "文章的润色" 。
📚 命令格式:
gcc [选项] 要编译的文件 [选项] [目标文件]预处理(进行宏替换):
- 预处理功能主要包括宏定义、文件包含、条件编译、去注释等。
- 预处理指令以 # 号开头的代码行。
- 实例:gcc -E hello.c -o hello.i
- 选项:"-E" 该选项的作用是让 gcc 在预处理结束过后停止编译过程。
- 选项:“-o" 是指目标文件, "i" 文件为已经过预处理的C初始程序。
0x03 编译过程
 编译的核心工作就是将C语言翻译成汇编语言!
编译的核心工作就是将C语言翻译成汇编语言!如果看不懂也没有关系,你只要知道 —— 这一步会让你的C语言代码大变样!
- $ gcc -S test.i -o test.s
- # -S: 从现在开始进行程序的编译,当我们编译完成之后,就停下来!
这次我们从 test.i 开始走,当然也可以是 test.c,那会重新走一遍预处理的过程然后再编译。
(汇编语言的后缀一般都叫 .s,所以我们这里取名为 .s,我们前面章节也说过 Linux 的类型和文件后缀没有关系,这里你用 .lbwnb 都没有人拦你,只是叫 .s 更符合常理)
输入完上面命令后就形成了 test.s 的文件:

 之后用 vim 打开 test.s 之后会让人很头大:
之后用 vim 打开 test.s 之后会让人很头大:
这是 x86 环境下的汇编指令,其中有一些汇编的助记符,即使看不明白也没有关系。
但是你可以发现代码的数量 从刚才 test.i 的八百多行,变成了现在短短的 45 行!
0x04 汇编过程(简单了解)
该过程是将汇编语言翻译翻译成二进制文件。
准确来说应该是 "可重定位二进制文件",它一般以 .o 结尾,VS 下是 .obj 结尾的:

值得一提的是,这里的 "重定位" 和我们前面说的 "重定向" 是完全没有任何关系的,就像雷锋和雷峰塔、Java 和 Javascript 一样完全没有任何关系。
- $ gcc -c test.s -o test.o
- # -c:从现在开始进行程序的编译,当我们汇编结束之后,就停下来!

此时就已经是二进制了,gcc 打开后会是很大的一坨乱码。
我们可以用一些二进制查看工具去查看,但是我相信已经没有地球人可以看懂了。
刚才的汇编语言确实有人可以看懂,但这里我直接说没有人能直接看懂应该不过分吧:

$ ./test.o虽然现在代码已经是二进制的了,但是仍然是不能运行的:

其原因也很简单,因为这里面有些符号目前还没有和系统关联起来。
0x05 链接过程

所有的包含头文件的操作,本质是因为想使用头文件所声明的方法!
$gcc test.o -o mytest
而这最后一步,隐含的就是链接我们自己的程序和库,形成可执行程序!
当然了,直接到程序的翻译过程:
$ gcc test.c -o mytest.c一步就可以到位了,我们之前是为了研究一步步的过程,所以又是 -E 又是 -S 又是 -c 的。
0x06 巧记程序的翻译过程
我们先来回故前三个翻译过程,按顺序分别为预处理、编译和汇编。
- $ gcc -E test.c -o test.i # 预处理
- $ gcc -S test.i -o test.s # 编译
- $ gcc -e test.s -o test.o # 汇编
 这里有个记忆方法:预处理 (E) → 编译 (S)→ 汇编 (c) ,三个过程就是
这里有个记忆方法:预处理 (E) → 编译 (S)→ 汇编 (c) ,三个过程就是 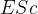 。
。如果你记不得,可以看看你键盘的左上角就行了(当然前提你要记住程序翻译过程的顺序)。
另外它们形成的临时文件为 test.i、test.s、test.o,也同样有个记忆的方法:
 (国际标准化组织:ISO)
(国际标准化组织:ISO)当然,iso 也是镜像文件的后缀,如果你比较熟悉也可以拿这个记。
ISO(Isolation)文件一般以iso为扩展名,是复制光盘上全部信息而形成的镜像文件
Ⅲ. 函数库(Function library)
0x00 引入:你早就与库有着千丝万缕的联系
我们的C程序中,并没有定义 printf 的函数实现,且在预编译中包含的 stdio.h 中也只有该函数的声明,而没有定义函数的实现。那么是在哪里实 printf 函数的呢?
系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径 /usr/lib 下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数 printf 了,而这也就是链接的作用。
 从我们敲下第一行代码,打印 Hello,World 时就已经和库有着千丝万缕的联系了。
从我们敲下第一行代码,打印 Hello,World 时就已经和库有着千丝万缕的联系了。看上去像是我们在写代码打印这个语句,实际上是调用了大佬写的 prinf 打印函数。
"其实我们无形中就已经站在了巨人的肩膀上"
你自己用的C语言头文件,从库中取的所有的函数,全部都需要在头文件当中声明,在库文件当中实现,然后在编译的时候再把你的可执行程序和库文件关联起来,此时关联之后,才能形成可执行程序。否则一切都是扯淡!
如果今天我们是在写 C++ 代码,C++ 对应的库也必须在安装 gcc 的时候都必须具备好,我们所说的装环境,实际上不仅仅在装环境。比如我们在装 VS2022 的时候我们不仅仅在装 VS2022,你也在装头文件也在装环境中所支持的语言。
0x01 头文件与库文件(Header file and Library file)
头文件:给我们提供了可以使用的方法,所有的开发环境,具有语法提示,本质是通过头文件帮我们搜索的。
库文件:给我们提供了可以使用的方法的实现,以供链接,形成我们自己的可执行程序。
0x02 动态库与静态库(Dynamic library and static library)
我们必须承认一个事实,计算机存在两类库:一类库叫动态库,一类库叫静态库。
静态库:Linux (.so),Windows (.dll) —— 动态链接
静态库:Linux (.a),Windows (,lib) —— 静态链接
静态链接:将库中的相关代码,直接拷贝到自己的可执行程序中。
动态链接:
- 优点:大家共享一个库,可以节省资源。
- 缺点:一旦库丢失,会导致几乎所有的程序失效!
那 gcc 中如何体现呢?
形成的可执行程序体积一定是不一样的,静态链接体积大,动态链接体积小。
那么我们在 Linux 中用 gcc 编译程序
默认情况下形成的的可执行程序就是动态链接的:

如果你想进行静态链接,你需要在编译代码时在后面加上 -static 选项:
$ gcc test.c -o mytest2 -static # 静态链接0x03 静态库的安装
此时如果出现了像下面这样找不到的情况:

那么你就需要安装一下静态库,记得切换到 root 下去安装。
🔧 安装 C 的静态库:
# sudo yum install -y glibc-static
🔧 安装 C++ 静态库:
# sudo yum install -y libstdc++-static0x04 动态链接和静态链接推荐使用哪个?
默认是动态链接,我们也更推荐动态链接,
因为生成体积小,无论是编译时间还是占资源的成本,一般都比静态链接要好。
但这并不是绝对的!如果你要发布一款软件是动态链接的,程序短小精悍但库相对显得累赘,
如果此时你发布这款软件就不想带库了,你把它静态链接就是完全合适的。


- 📌 [ 笔者 ] 王亦优
- 📃 [ 更新 ] 2022.3.
- ❌ [ 勘误 ] /* 暂无 */
- 📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
- 本人也很想知道这些错误,恳望读者批评指正!
📜 参考资料
C++reference[EB/OL]. []. http://www.cplusplus.com/reference/.
Microsoft. MSDN(Microsoft Developer Network)[EB/OL]. []. .
百度百科[EB/OL]. []. https://baike.baidu.com/.
比特科技. Linux[EB/OL]. 2021[2021.8.31 xi
- 📌 [ 笔者 ] 王亦优
- 📃 [ 更新 ] 2022.3.
- ❌ [ 勘误 ] /* 暂无 */
- 📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
- 本人也很想知道这些错误,恳望读者批评指正!
📜 参考资料
C++reference[EB/OL]. []. http://www.cplusplus.com/reference/.
Microsoft. MSDN(Microsoft Developer Network)[EB/OL]. []. .
百度百科[EB/OL]. []. https://baike.baidu.com/.
比特科技. Linux[EB/OL]. 2021[2021.8.31 xi
-
相关阅读:
[力扣] 剑指 Offer 第四天 - 数组中重复的数字
使用Selenium的Python脚本实现自动登录
C++lambda表达式
“ 我是一名阿里在职9年软件测试工程师,我的经历也许能帮到处于迷茫期的你 ”
地塞米松/多柔比星/胡桃醌/丹皮酚-PLGA聚乳酸-羟基乙酸纳米粒
C++ 和 JAVA 位运算符
python 获取下载文件的后缀
回归预测 | MATLAB实现CNN-SVM卷积支持向量机多输入单输出回归预测
14:00面试,14:06就出来了,问的问题有点变态。。。
springboot入门
- 原文地址:https://blog.csdn.net/weixin_50502862/article/details/125986674