-
风控(策略)岗中的模型知识须知
后疫情时代加速了金融机构的数字化转型的进程,汽车金融、消费金融、互联网金融企业纷纷加强数字化建设。同时外部环境的不确定性也在不断增加,欺诈风险及信用风险持续升级。可以说,数字化转型势在必行,在这个趋势下每个岗位与之匹配的数字化能力也应该随之提升。
比如在与策略相关的岗位,这一部分的童鞋在番茄风控社区中占比较高,我们建议无论是贷前/贷中/贷后策略的同学除了会对具体的数据需求提供埋点与部署的相应方案,能够解读相关的接口文档,能进行不同环节点中的调优数据,做好各自环节的监控报表外,另外还有必要学一下相关的模型技能。风控中的模型技能,似乎现在随手一看各大招聘岗位,感觉都像是通用必备技能了
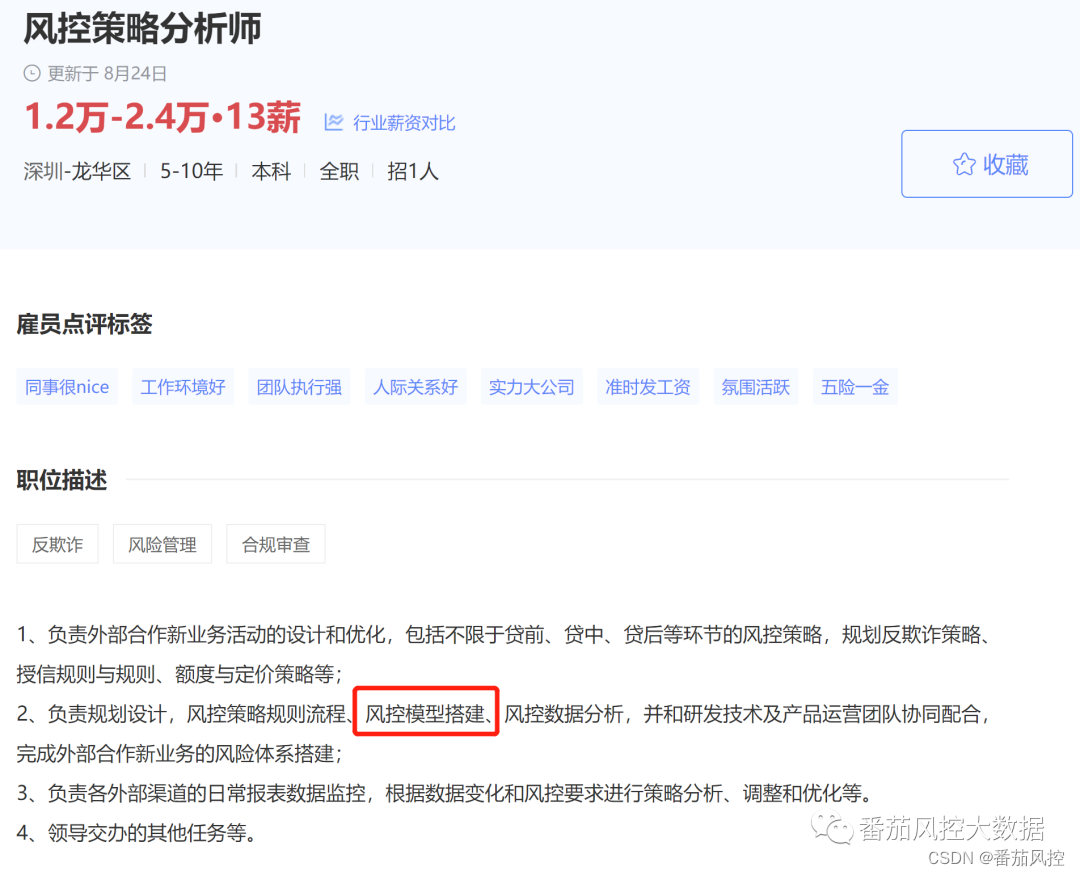
图:某招聘网策略分析岗- 1
通用的模型技能,并不是说需要我们从头到尾地去编写一套完整的模型代码,不是说需要将这套模型的KS、auc等指标做得多么高,当然如果你有优秀的代码能力是能加分的。通用的模型能力,更多的是需要我们懂指标、能用好指标,清楚这些指标的逻辑,并且如果可以,还能自己开发一套简易的评分卡。
综上所述,关于模型的通用技能,有以下的这些知识点给读者进行了梳理了,以下都是在整个风控上最重要且必备的模型知识:①建模的概念
建模就是构造一个数学公式,能将我们手上有的数据输入进去,通过计算得到一些预测出来的结果。 比如大家初中/高中学习的线性回归,就是最简单的建模过程。 风控模型最原始的思路就是输入一个用户的信息,得到这个人是 “会还钱” 还是 “不会还钱”。这就是个二分类问 题。 而评分卡模型其实就是希望能将一系列的个人信息输入模型,然后得到一个用户的还款概率。概率越大,评分越 高,越容易还钱。概率越小,评分越低,越容易跑路。典型例子就是芝麻信用分。 那为什么一定要应射成某种分数呢?②常规上评分卡分类A Card
“Application scorecard 申请评分卡,对授信阶段提交的资料赋值的模型结果规则”
B Card
“Behavior scorecard 行为评分卡,对贷后可以收集到的用户信息进行评分的规则”C Card
“Collection Scorecard 催收评分卡,对已逾期用户未来出催能力做判断的评分规则”F Card
“Fraud Scorecard,反欺诈评分卡,常针对申请阶段进行反欺诈用户识别”③模型里有分数刻度的好处
我们可以随时根据业务需求调整通过率 更容易向用户解释他的信用评级 更容易向领导解释一个用户被拒绝的原因 更容易监控一个模型的效果④Benchmark"基准。每个版本的新模型都要与一个线上的基准模型或规则集做效果比对"
⑤模型开发后的各大效果指标解读
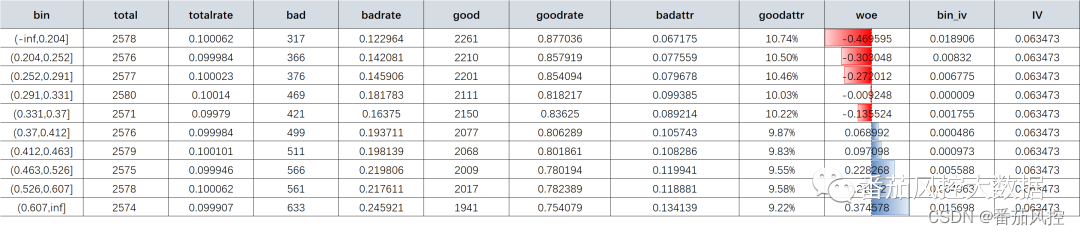
5.1.IV:“information value 信息值。一般取值区间(0,1)。该值用来表示某个变量的预测能力,越大越好。通常IV值0.3以上的,预测能力较高。
IV=SUM((B_P-G_P)*LN(B_P/G_P))”
5.2.K-S:“klmogrov-smirnov,这是一个区分度指标。所谓区分度,是指模型对于好坏客户的辨识能力,区分力越强,模型准确度越高,误判的几率越低。K-S值越大越好,一般0.6以上用户解释能力很高。
KS=Max(RETAIN_BAD_P-RETAIN_GOOD_P)”
5.3.PSI
"population stability index,稳定度指标,越低越稳定。用于比较当前客群与模型开发样本客群差异程度,评价模型的效果是否符合预期。
5.4.Training Sample
“建模样本,用来训练模型的一组有表现的用户数据。配合该样本还有Validation sample(验证样本),两个样本都取同样的用户维度,通常要使用建模样本训练出的模型在验证样本上进行验证。”
5.5.WOE
“weight of ecidence,证据权数,取值区间(-1,1)。违约件占比高于正常件,WOE为负数。绝对值越高,表明该组因子区分好坏客户的能力越强
WOE=LN(B_P/G_P)”
5.6.Bad Capture Rate
“坏用户捕获率。这是评价模型效果的一个指标,比率越高越好。”
5.7.Lift
模型提升度,表示使用模型比未使用的区分效果提升能力
5.8.CORR
“相关系数。Corr的绝对值越接近1,则线性相关程度越高,越接近0,则相关程度越低。”
5.9.AUC
“Area Under Curve,定义为ROC曲线下面积,通常大于0.5小于1。体现模型预测精准度指标之一”
5.10.GINI同KS指标一样,都是体现模型区分能力的指标以上知识内容优先建议如策略岗位,入门或转型风控等同学可阅读了解。
关于风控岗中更多的模型技能要求,可回顾:
-《风控策略中的模型须知》

课程预览:
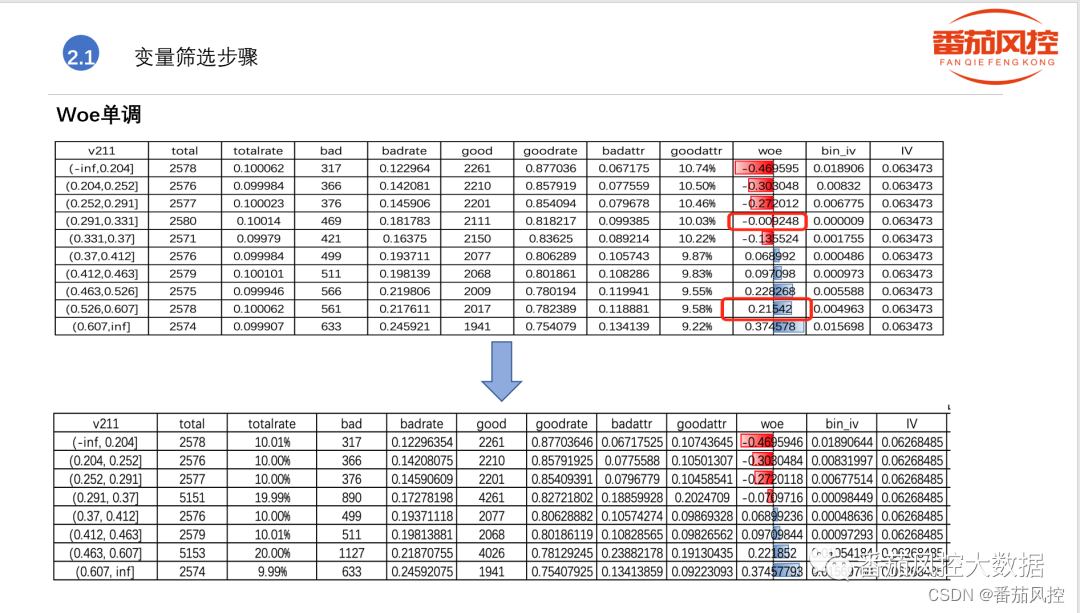
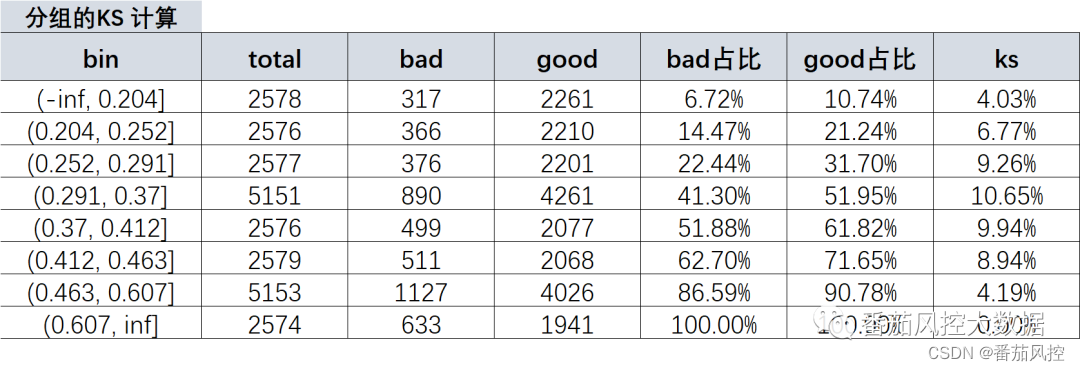
①分组KS计算
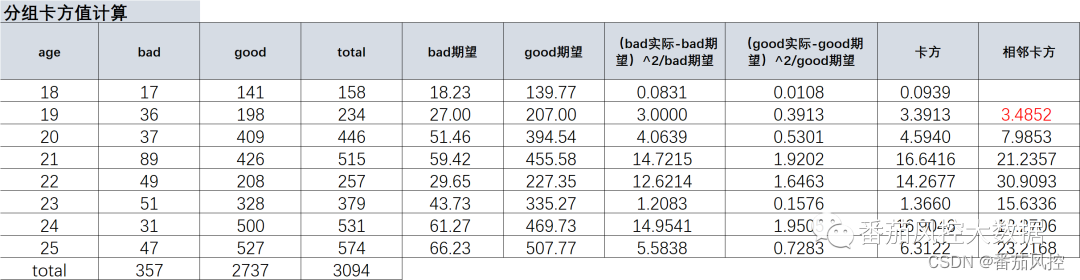
②分组的卡方计算
③如何做cut-off切分
…
~原创文章
-
相关阅读:
建造者模式和模板设计模式应该怎么使用
java中BigDecimal除法运算指定小数点保留位数和取舍规则
SpringSecurity原理解析以及CSRF跨站请求伪造攻击
【培训课程专用】ShareMemory的建立代码导读
Mysql-SQL优化
ORB-SLAM3在保存地图时高频率崩溃问题
ES2020-23简单易懂又实用的精选特性讲解 ✨✨日常开发必备干货!✨✨
2023年阿里云双11优惠活动,省钱攻略来了!
Java入门——this()/super()
虚拟化+Docker基本管理
- 原文地址:https://blog.csdn.net/weixin_45545159/article/details/126923730