-
数据库例题精选
大的国
如果一个国家满足下述两个条件之一,则认为该国是 大国 :
面积至少为 300 万平方公里(即,3000000 km2),或者
人口至少为 2500 万(即 25000000)
编写一个 SQL 查询以报告 大国 的国家名称、人口和面积。按 任意顺序 返回结果表。
查询结果格式如下例所示。
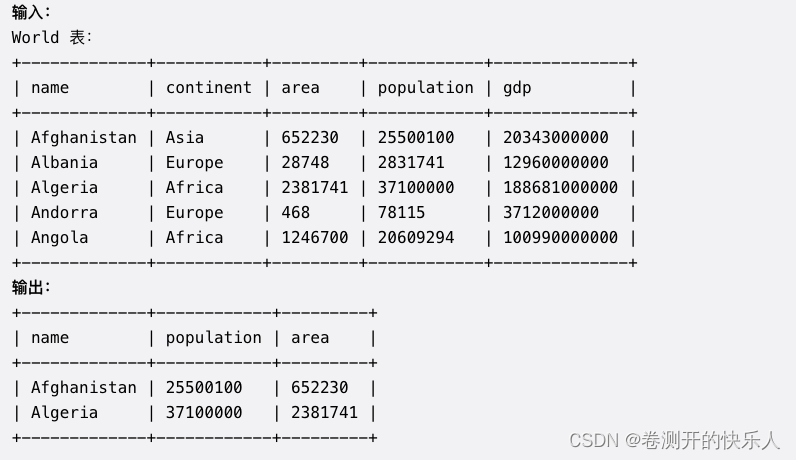
select name, population, area from world while area >=3000000 or population >25000000- 1
- 2
- 3
给定表 customer ,里面保存了所有客户信息和他们的推荐人。
±-----±-----±----------+
| id | name | referee_id|
±-----±-----±----------+
| 1 | Will | NULL |
| 2 | Jane | NULL |
| 3 | Alex | 2 |
| 4 | Bill | NULL |
| 5 | Zack | 1 |
| 6 | Mark | 2 |
±-----±-----±----------+
写一个查询语句,返回一个客户列表,列表中客户的推荐人的编号都 不是 2。对于上面的示例数据,结果为:
±-----+
| name |
±-----+
| Will |
| Jane |
| Bill |
| Zack |
±-----+select name from custome where referee_id !=2 or referee_id is null;- 1
- 2
- 3
在sql中 is (not) null可以判断是否为空 ,!=只能判断值
某网站包含两个表,Customers 表和 Orders 表。编写一个 SQL 查询,找出所有从不订购任何东西的客户。
Customers 表:
±—±------+
| Id | Name |
±—±------+
| 1 | Joe |
| 2 | Henry |
| 3 | Sam |
| 4 | Max |
±—±------+
Orders 表:±—±-----------+
| Id | CustomerId |
±—±-----------+
| 1 | 3 |
| 2 | 1 |
±—±-----------+
例如给定上述表格,你的查询应返回:±----------+
| Customers |
±----------+
| Henry |
| Max |
±----------+
情况一:
选择 Orders表和Customers中名字不相同的select name Customers from Customers c where not exists (select * from Orders o where o.CustomerId=c.Id)- 1
- 2
- 3
select 1和select * 都是一样的道理
name Customers 表示 Customers可以代替name在接下来的数据库中情况二:
not in 不在select Name Customers from Customers c where c.Id not in ( select CustomerId from Orders )- 1
- 2
- 3
- 4
- 5
情况三:
左链接
select Name Customers
from Customers c
left join Orders o
on c.Id=0.Customerid
where o.id is null我们要知道
内链接 是两个链接的交集select a.name,b.class from A a inner join B b on a.id=b.A_id 所以只能显示相连相等的行及A表id为1和B表A_id为一的 name class 张三 一年一班- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
左链接 是交集然后加上全部的左边,
select a.name,b.class from A a left join B b on a.id-b.A_i`在这里插入代码片`d 左表只有三条就显示三条 和右表没有相等字段补bull name class 张三 一年一班 李四 null 王五 null- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
右链接交集加上全部的右边,
select a.name,b.class from A a right join B b on a.id=b.A_id 右表只有两条就显示两条 和左表没有相等字段补null name class 张三 一年一班 null 一年二班- 1
- 2
- 3
- 4
- 5
- 6
- 7
全链接是并集。
select a.name,b.class from A a full join B b on a.id=b.A_id 全部显示 name class 张三 一年一班 null 一年二班 李四 null 王五 null- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输入:
Salary 表:
±—±-----±----±-------+
| id | name | sex | salary |
±—±-----±----±-------+
| 1 | A | m | 2500 |
| 2 | B | f | 1500 |
| 3 | C | m | 5500 |
| 4 | D | f | 500 |
±—±-----±----±-------+
输出:
±—±-----±----±-------+
| id | name | sex | salary |
±—±-----±----±-------+
| 1 | A | f | 2500 |
| 2 | B | m | 1500 |
| 3 | C | f | 5500 |
| 4 | D | m | 500 |
±—±-----±----±-------+
解释:
(1, A) 和 (3, C) 从 ‘m’ 变为 ‘f’ 。
(2, B) 和 (4, D) 从 ‘f’ 变为 ‘m’ 。如果只能用update该咋写呢
update salary set sex = if(sex='m','f','m')- 1
如果不用if的话
select id, name,if(sex='m','f','m'),salary from salary- 1
- 2
删除重复的邮箱
输入:
Person 表:
±—±-----------------+
| id | email |
±—±-----------------+
| 1 | john@example.com |
| 2 | bob@example.com |
| 3 | john@example.com |
±—±-----------------+
输出:
±—±-----------------+
| id | email |
±—±-----------------+
| 1 | john@example.com |
| 2 | bob@example.com |
±—±-----------------+
解释: john@example.com重复两次。我们保留最小的Id = 1。delete u from person u ,person v where v.id < u.id and u.email = v.email- 1
- 2
- 3
数据库中字符串处理
输入:
Users table:
±--------±------+
| user_id | name |
±--------±------+
| 1 | aLice |
| 2 | bOB |
±--------±------+
输出:
±--------±------+
| user_id | name |
±--------±------+
| 1 | Alice |
| 2 | Bob |
±--------±------+这里需要用到的函数 concat()将多个字符串连接成一个,upper()大写字符串,lower()小写字符串,left()左边第几个,substr()从左边第几个到完
select user_id, concat(upper(left(name,1)),lower(substr(name,2))) name
from
Users
order by
user_id输入:
Activities 表:
±-----------±------------+
| sell_date | product |
±-----------±------------+
| 2020-05-30 | Headphone |
| 2020-06-01 | Pencil |
| 2020-06-02 | Mask |
| 2020-05-30 | Basketball |
| 2020-06-01 | Bible |
| 2020-06-02 | Mask |
| 2020-05-30 | T-Shirt |
±-----------±------------+
输出:
±-----------±---------±-----------------------------+
| sell_date | num_sold | products |
±-----------±---------±-----------------------------+
| 2020-05-30 | 3 | Basketball,Headphone,T-shirt |
| 2020-06-01 | 2 | Bible,Pencil |
| 2020-06-02 | 1 | Mask |
±-----------±---------±-----------------------------+
解释:
对于2020-05-30,出售的物品是 (Headphone, Basketball, T-shirt),按词典序排列,并用逗号 ‘,’ 分隔。
对于2020-06-01,出售的物品是 (Pencil, Bible),按词典序排列,并用逗号分隔。
对于2020-06-02,出售的物品是 (Mask),只需返回该物品名。思路分析:1.按照日期排序分组
order by 和 group by
2.统计 每组的数量 count()聚合函数
3.products 用,分割group_concat(distinct product order by product separator ‘,’) products
select sell_date , count( distinct product) num_sold , group_concat(distinct product order by product separator ',') products from activities group by sell_date order by sell_date- 1
- 2
- 3
- 4
模糊匹配
输入:
Patients表:
±-----------±-------------±-------------+
| patient_id | patient_name | conditions |
±-----------±-------------±-------------+
| 1 | Daniel | YFEV COUGH |
| 2 | Alice | |
| 3 | Bob | DIAB100 MYOP |
| 4 | George | ACNE DIAB100 |
| 5 | Alain | DIAB201 |
±-----------±-------------±-------------+
输出:
±-----------±-------------±-------------+
| patient_id | patient_name | conditions |
±-----------±-------------±-------------+
| 3 | Bob | DIAB100 MYOP |
| 4 | George | ACNE DIAB100 |
±-----------±-------------±-------------+
解释:Bob 和 George 都患有代码以 DIAB1 开头的疾病。select * from patients where conditions like 'diab1%' or conditions like '% diab1%'- 1
- 2
- 3
- 4
-
相关阅读:
php中使用Imagick转换PDF第一页为PNG图片并且识别出二维码
Selenium 4.11 正式发布--再也不用手动更新chrome driver 了
优秀的项目管理办公室(PMO)的5条规则
Idea之常用插件
使用.NET简单实现一个Redis的高性能克隆版(六)
UIC 564-2 座椅耐火测试
53. 最大子数组和
Analysis of Xiaomi Kernel(Updating)
[附源码]Python计算机毕业设计Django人体健康管理app
隐函数求导例题及解析
- 原文地址:https://blog.csdn.net/m0_57315623/article/details/126097391