-
【Hadoop---03】Hadoop环境配置「安装虚拟机、安装CentOS操作系统 | 虚拟机的网络配置 | 远程登陆 | 分布式集群」
文章目录
1. Hadoop三种工作模式
Hadoop有三种工作模式:
- 本地模式(Local Mode):单台服务器,数据存储在Linux本地。生产环境几乎不会采用该模式,一般用于测试。
- 伪分布式模式(Pseudo-Distributed Mode):单台服务器,数据存储在HDFS上。有较少的小型公司采用该模式。
- 完全分布式模式(Fully-Distributed Mode):多台服务器组成集群,数据存储在HDFS上,多台服务器工作。在企业中大量使用。
下面只介绍完全分布式模式的环境配置,至于其他有机会再补上。
2. Hadoop分布式集群环境配置
第一步: 安装VMware 与 CentOS的虚拟机
第二步:虚拟机网络配置
第三步:主机远程登入虚拟机
第四步: 配置一台模板虚拟机
将hadoop100做为一台模板虚拟机。
-
安装 epel-release:
[root@hadoop100 ~]# yum install -y epel-release- 1
-
关闭防火墙,关闭防火墙开机自启:
[root@hadoop100 ~]# systemctl stop firewalld [root@hadoop100 ~]# systemctl disable firewalld.service- 1
- 2
注意:在实际开发中,服务器的防火墙也是关闭的,只有连接公网的那台服务器才开启防火墙。

-
为hao 用户添加 root 权限,方便后期加 sudo 执行 root 权限的命令:
[root@hadoop100 ~]# vim /etc/sudoers- 1
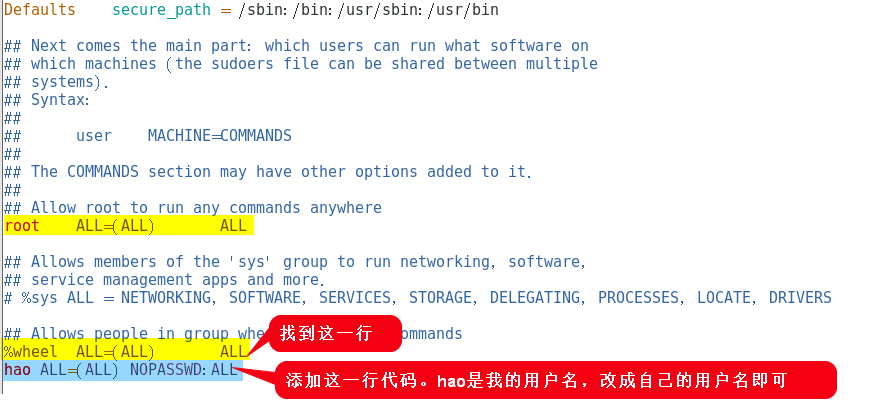
hao ALL=(ALL) NOPASSWD:ALL -
在/opt 目录下创建文件夹,并修改所属主和所属组
[root@hadoop100 ~]# mkdir /opt/module [root@hadoop100 ~]# mkdir /opt/software [root@hadoop100 ~]# chown hao:hao /opt/module [root@hadoop100 ~]# chown hao:hao /opt/software- 1
- 2
- 3
- 4
-
卸载虚拟机自带的 JDK
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps- 1

第五步: 克隆三台主机
- 关机模板虚拟机
- 克隆三台虚拟机,并命名为:Hadoop102、Hadoop103、Hadoop104

- 修改克隆机的主机名和静态IP
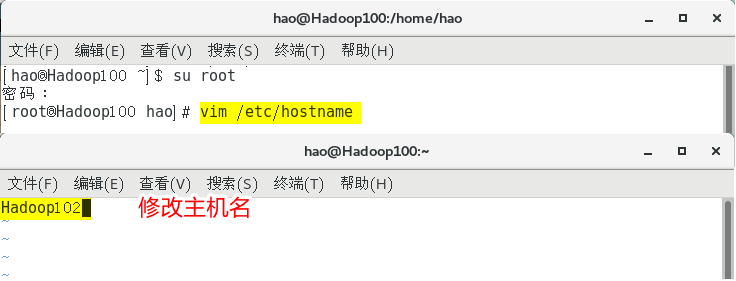

- 重启主机
第六步:安装JDK和Hadoop
将Hadoop102做为配置机。 即:先给配置机Hadoop102装JDK和Hadoop。后面再直接将Hadoop102虚拟机的JDK和Hadoop复制给克隆机Hadoop103、Hadoop104。
(1) 首先给配置机安装JDK
-
将windows主机下的jdk1.8 压缩包通过Xftp拖拽上传到之前在Hadoop102中创建的
/opt/software文件夹中。 -
将 jdk 解压到之前创建的
/opt/module/文件夹中tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module/- 1
-
为JDK配置环境变量:
/etc/profile.d文件夹中的.sh后缀的文件都会被加载到为环境变量。所以:
① 在/etc/profile.d下创建my_env.sh,并编写该文件:[root@Hadoop102 profile.d]# cd /etc/profile.d [root@Hadoop102 profile.d]# sudo vim my_env.sh- 1
- 2
② 编写
my_env.sh文件,写入:# JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin- 1
- 2
- 3
③ 重新加载环境变量的配置文件
source /etc/profile- 1
④ 在终端输入java,能够显示java相关文字,则说明JDK安装成功!

(2) 再给配置机安装Hadoop
-
将windows主机下的Hadoop 3.x压缩包通过Xftp拖拽上传到之前在Hadoop102中创建的
/opt/software文件夹中。 -
将Hadoop 3.x解压到之前创建的
/opt/module/文件夹中tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/- 1
-
为Hadoop配置环境变量:
① 安装JDK时创建了my_env.sh,此时再次打开此文件,并添加:[root@Hadoop102 profile.d]# cd /etc/profile.d [root@Hadoop102 profile.d]# vim my_env.sh- 1
- 2
② 编写
my_env.sh文件,写入:# HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin- 1
- 2
- 3
- 4
③ 重新加载环境变量的配置文件
source /etc/profile- 1
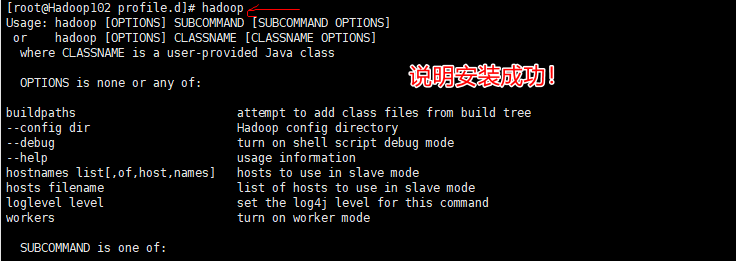
④ 在终端输入hadoop,能够显示hadoop相关文字,则说明hadoop安装成功!
(3) 将配置机的JDK和Hadoop复制给其他克隆机
scp 可以实现服务器与服务器之间的数据拷贝。语法:

# 给hadoop103装JDK、Hadoop scp -r /opt/module/jdk1.8.0_212/ hao@hadoop103:/opt/module/ scp -r /opt/module/hadoop-3.1.3/ hao@hadoop103:/opt/module/ # 给hadoop104装JDK、Hadoop scp -r /opt/module/jdk1.8.0_212/ hao@hadoop104:/opt/module/ scp -r /opt/module/hadoop-3.1.3/ hao@hadoop104:/opt/module/ # 也可以在hadoop103上使用scp从hadoop102上拉取,比如: # scp -r hao@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Hadoop103、Hadoop104安装JDK、Hadoop是否成功,同上面。
第七步:在配置机中编写同步脚本并同步至其他克隆机
(1) 设置服务器间免密登入
为了后续的方便,设置Hadoop102、Hadoop103、Hadoop104间的免密登入。【免密登陆详情】
(2) 编写脚本
scp命令:复制所有文件。rsync命令:只复制名称或内容不相同的文件。
所以,使用rsync指令去编写同步脚本。
-
创建
xsync文件

-
编写
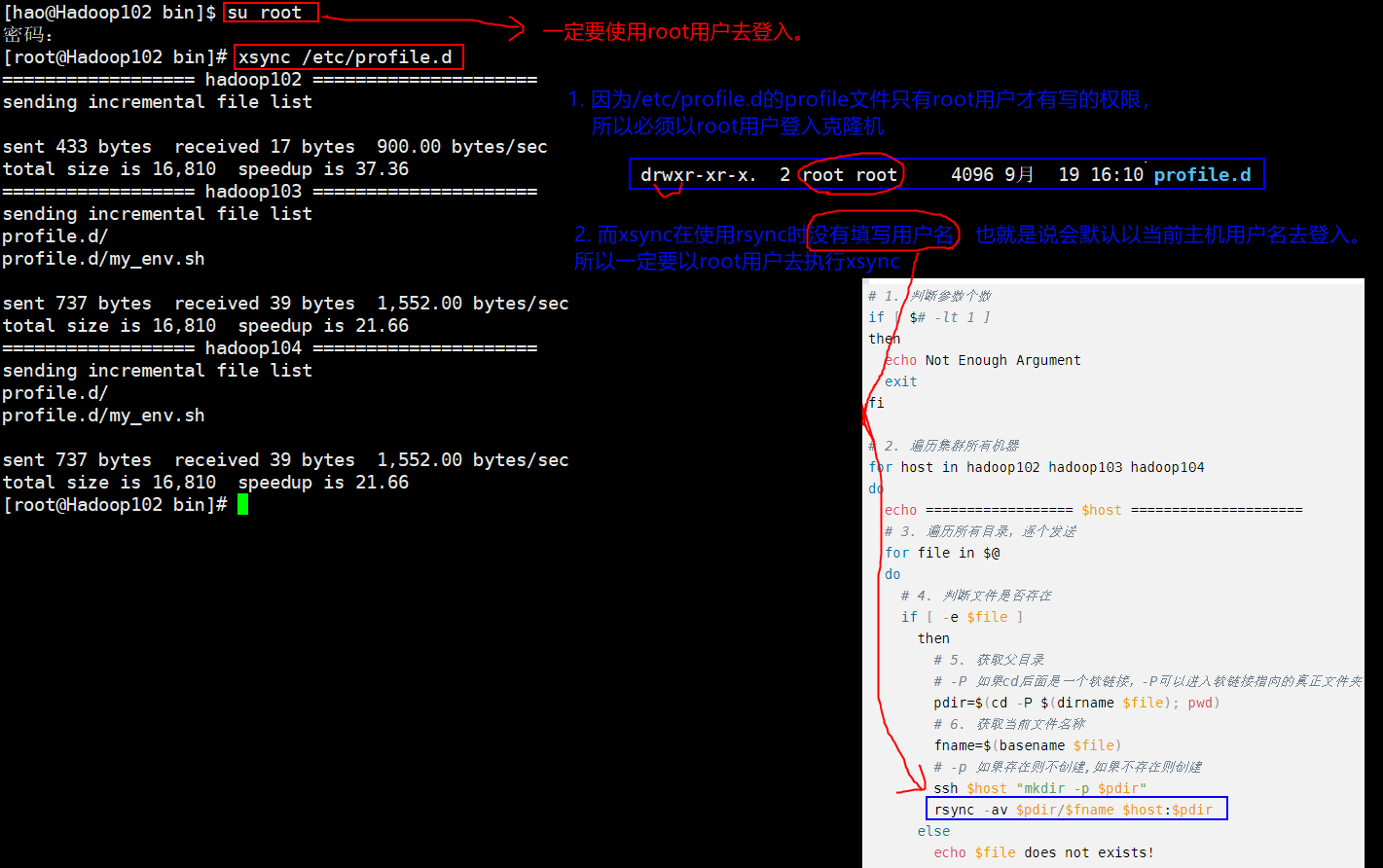
xsync文件,内容如下:#!/bin/bash # 1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Argument exit fi # 2. 遍历集群所有机器 for host in hadoop102 hadoop103 hadoop104 do echo ================== $host ===================== # 3. 遍历所有目录,逐个发送 for file in $@ do # 4. 判断文件是否存在 if [ -e $file ] then # 5. 获取父目录 # -P 如果cd后面是一个软链接,-P可以进入软链接指向的真正文件夹 pdir=$(cd -P $(dirname $file); pwd) # 6. 获取当前文件名称 fname=$(basename $file) # -p 如果存在则不创建,如果不存在则创建 ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
注意:此脚本只能用于文件同步。并不能删除。比如配置机没有data文件,其他克隆机有data文件,使用xsync后,并不能将其他克隆机的data文件删除。
-
将
/home/hao/bin添加到环境变量:
① 安装JDK时创建了my_env.sh,此时再次打开此文件,并添加:[root@Hadoop102 profile.d]# cd /etc/profile.d [root@Hadoop102 profile.d]# vim my_env.sh- 1
- 2
② 编写
my_env.sh文件,写入:# HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin- 1
- 2
- 3
- 4
③ 重新加载环境变量的配置文件
source /etc/profile- 1
(2) 为编写脚本配置可执行权限

此时自定义的xsync命令用法:
- 同步当个文件夹或文件:
xsync 当前主机要同步给其他主机的绝对或相对路径 - 同步多个文件夹或文件:
xsync 路径1 路径2
(3) 使用编写的xsync脚本将配置机的环境变量同步给其他克隆机
从逻辑上说,环境变量是root才可以修改的,所以要使用root用户去同步
第八步:集群配置
(1) 服务器规划
-
Yarn集群和HDFS集群:逻辑上分离、物理上在一起。
① 逻辑上,Yarn集群的启动和HDFS集群的启动并没有直接的依赖关系。
② 物理上,Yarn集群、HDFS集群,都是在同一个安装了Hadoop的集群内。 -
MapReduce是计算框架,是代码层面的组件,没有集群之说。
故,
Hadoop集群 = HDFS集群 + Yarn集群。又因为NameNode、SecondaryNameNode、ResourceManager都比较占内存,所以最好分别安装在不同的服务器上。最终服务器规划如下:配置项 Hadoop102 Hadoop102 Hadoop103 Hadoop104 HDFS NameNode、DataNode DataNode SecondaryNameNode、DataNode YARN NodeManager ResourceMananger、NodeManager NodeMananger 历史服务器 JobHistoryServer (2) 配置文件配置
- 配置文件的分类:
-
默认配置文件: 一般不做修改。位于
$HADOOP_HOME/share/hadoop,即/opt/module/hadoop-3.1.3/share/hadoop下默认的四大配置文件 存放位置 core-default.xml ① hadoop-common-3.1.3.jar ② 使用jar指令解压后可见core-default.xml文件 hdfs-default.xml ① hadoop-hdfs-3.1.3.jar ② 使用jar指令解压后可见hdfs-default.xml文件 yarn-default.xml ① hadoop-yarn-common-3.1.3.jar ② 使用jar指令解压后可见yarn-default.xml文件 mapred-default.xml ① hadoop-mapreduce-client-core-3.1.3.jar ② 使用jar指令解压后可见mapred-default.xml文件 -
自定义配置文件: 一般修改自定义文件。位于
$HADOOP_HOME/etc/hadoop,即/opt/module/hadoop-3.1.3/etc/hadoop/下自定义的四大配置文件 存放位置 core-site.xml 该目录下直接可见 hdfs-site.xml 该目录下直接可见 yarn-site.xml 该目录下直接可见 mapred-site.xml 该目录下直接可见
-
- 修改Hadoop102的自定义配置文件
-
编辑
core-site.xml文件:
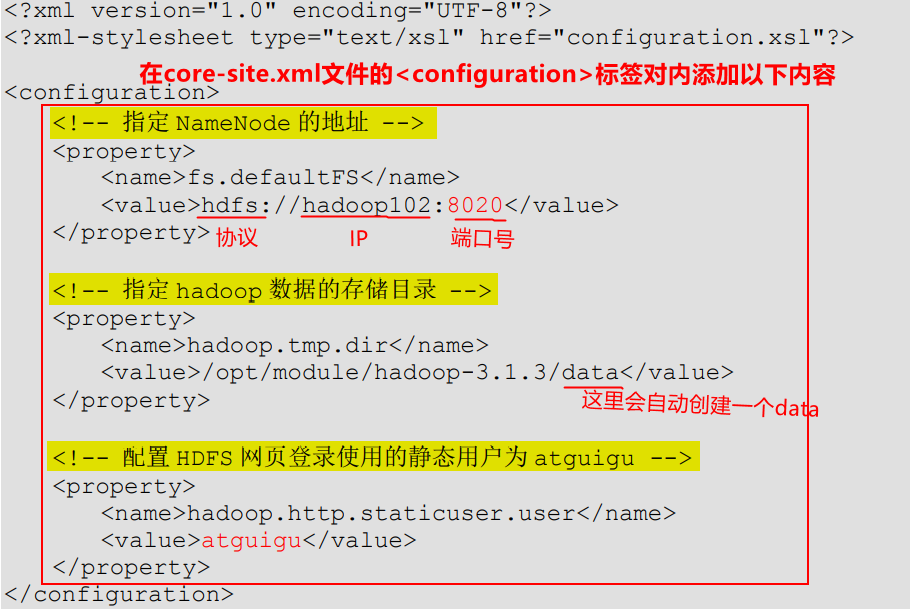
"1.0" encoding="UTF-8"?> type="text/xsl" href="configuration.xsl"?><!-- 指定NameNode的地址 --> fs.defaultFS</name> hdfs://hadoop102:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <!-- 我们指定的data文件夹如果不存在,hadoop会自动进行创建 --> hadoop.tmp.dir</name> /opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为hao(即hdfs中的用户) --> <!-- 如果不配置,那么在浏览器中默认的是Mr.who,该用户删除hdfs文件时,会提示无权限。--> hadoop.http.staticuser.user</name> hao</value> </property> </configuration> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
-
编写
hdfs-site.xml文件:配置NameData、SecondinaryNameData访问外网信息
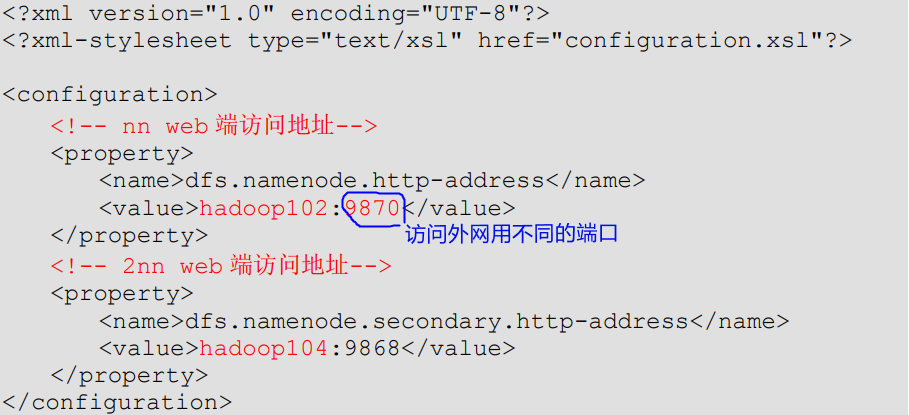
"1.0" encoding="UTF-8"?> type="text/xsl" href="configuration.xsl"?><!-- NameNode对外暴露的Web端访问地址 --> dfs.namenode.http-address</name> hadoop102:9870</value> </property> <!-- 2NN 对外暴露的Web端访问地址(2NN安装在hadoop104上) --> dfs.namenode.secondary.http-address</name> hadoop104:9868</value> </property> </configuration> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-
配置
yarn-site.xml文件:"1.0"?><!-- 指定MR走shuffle --> <!-- 在yarn-default.xml中该项默认值为空,但是官方推荐使用mapreduce_shuffle --> yarn.nodemanager.aux-services</name> mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址(ResourceManager安装在hadoop103) --> yarn.resourcemanager.hostname</name> hadoop103</value> </property> <!-- 环境变量的继承 --> yarn.nodemanager.env-whitelist</name> JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- 配置日志聚集功能,yarn-default.xml中该项默认为false --> yarn.log-aggregation-enable</name> true</value> </property> <!-- 设置日志聚集服务器地址,设置聚集到历史日志服务器上,方便查看 --> yarn.log.server.url</name> http://hadoop102:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间:7天 --> yarn.log-aggregation.retain-seconds</name> 604800</value> </property> <!-- 结点大小限制 --> yarn.nodemanager.resource.memory-mb</name> 22528</value> 每个节点可用内存,单位MB</discription> </property> yarn.scheduler.minimum-allocation-mb</name> 1500</value> 单个任务可申请最少内存,默认1024MB</discription> </property> yarn.scheduler.maximum-allocation-mb</name> 16384</value> 单个任务可申请最大内存,默认8192MB</discription> </property> </configuration> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
-
配置
mapred-site.xml文件:"1.0"?> type="text/xsl" href="configuration.xsl"?><!-- 指定MapReduce程序运行在Yarn上 --> <!-- mapred-default.xml中该项默认值是local,即在本地运行 --> mapreduce.framework.name</name> yarn</value> </property> <!-- 配置历史服务器的内部服务端地址 --> mapreduce.jobhistory.address</name> hadoop102:10020</value> </property> <!-- 配置历史服务器暴露的web地址 --> mapreduce.jobhistory.webapp.address</name> hadoop102:19888</value> </property> <!-- map、reduce结点的限制 --> mapreduce.map.memory.mb</name> 1500</value> 每个Map任务的物理内存限制</description> </property> mapreduce.reduce.memory.mb</name> 3000</value> 每个Reduce任务的物理内存限制</description> </property> mapreduce.map.java.opts</name> -Xmx1200m</value> </property> mapreduce.reduce.java.opts</name> -Xmx2600m</value> </property> mapreduce.framework.name</name> yarn</value> </property> </configuration> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
-
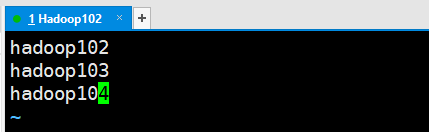
(3) 配置集群
参与集群的所有主机都需要记录在
$HADOOP_HOME/etc/hadoop/,即/opt/module/hadoop-3.1.3/etc/hadoop/路径下的works文件中。[root@Hadoop102 ~]# cd /opt/module/hadoop-3.1.3/etc/hadoop/ [root@Hadoop102 hadoop]# vim workers- 1
- 2
(4) 使用xsync将配置机的集群配置文件同步给其他克隆机
从逻辑上说,是用户hao安装的Hadoop,所以要使用hao用户去同步Hadoop的文件
[hao@Hadoop102 hadoop]# xsync /opt/module/hadoop-3.1.3/etc/hadoop/- 1
然后,可以在Hadoop103中查看是否同步成功。
第九步:启动集群
(1) 初始化NameNode
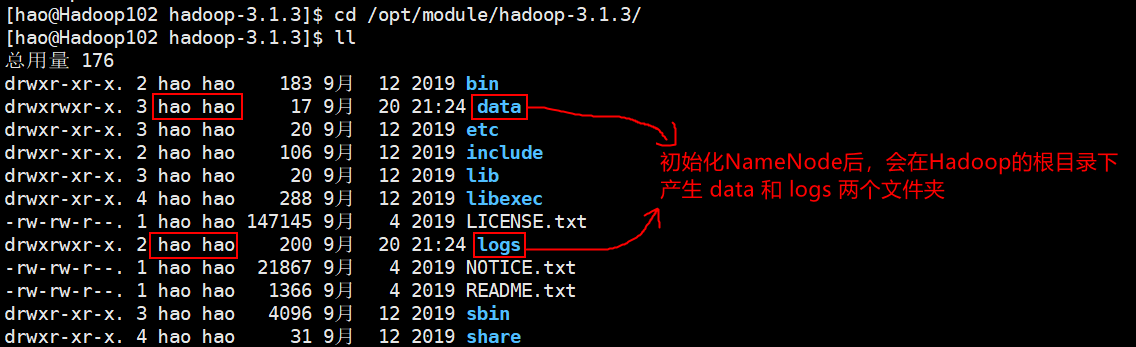
如果是第一次启动集群,需要对NameNode进行初始化操作,不是第一次则不用。(类似于电脑新加了一个硬盘,需要给硬盘进行分盘符等初始化操作)
非常重要: 由于配置机以及其他克隆机的Hadoop都是以
hao用户去创建的,所以为了保证权限的同一,应该hao用户去执行以下指令,这样该指令所创建的data文件和logs文件 还是hao用户。在配置NameNode的主机上执行以下命令:
# 在任何路径下输入以下初始化命令 [hao@Hadoop102 ~]# hdfs namenode -format- 1
- 2
注意:如果多次格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止NameNode和DataNode的进程,并且要使用
rm -rf 文件夹名删除所有机器的data和logs目录,然后再进行格式化(2) 启动 / 关闭 HDFS
-
启动:在配置NameNode的主机上执行
/opt/module/hadoop-3.1.3/sbin下的start-dfs.sh文件。

-
**查看:**再输入
jps查看当前主机运行的 hdfs 的java进程和集群规划的是否一致。
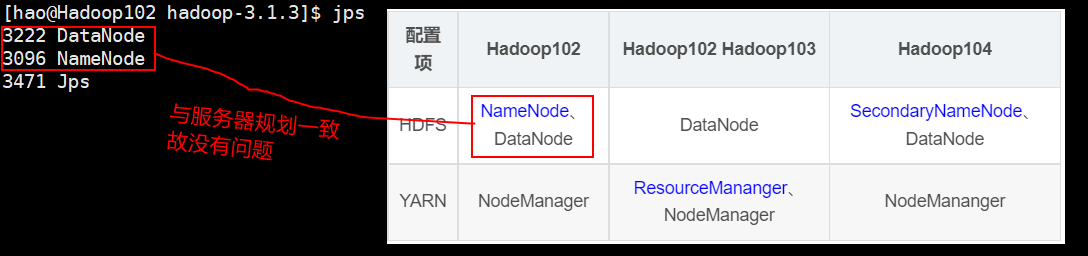
再上Hadoop103、Hadoop104上查看一下,是否与服务器规划一致,若所有服务器都一致,则hdfs配置成功。 -
关闭:
- 关闭namenode/datanode/secondarynamenode一个或多个,则在集群中的任意主机上输入:
hdfs --daemon start/stop namenode/datanode/secondarynamenode- 1
- 如果要关闭HDFS:namenode/datanode/secondarynamenode所有,则:在配置NameNode的主机上执行
/opt/module/hadoop-3.1.3/sbin下的stop-dfs.sh文件。 - 关闭所有HDFS、YARN等,则在集群中的任意主机上执行
stop-all.sh文件。
- 关闭namenode/datanode/secondarynamenode一个或多个,则在集群中的任意主机上输入:
(3) 启动 / 关闭 YARN
-
启动:在配置ResourceManager的主机上执行
/opt/module/hadoop-3.1.3/sbin下的start-yarn.sh文件。 -
**查看:**再输入
jps查看当前主机运行的 hdfs 的java进程和集群规划的是否一致。

再上Hadoop103、Hadoop104上查看一下,是否与服务器规划一致,若所有服务器都一致,则yarn配置成功。
-
关闭:
- 关闭resourcemanager/nodemanager一个或多个,则在集群中的任意主机上输入:
hdfs --daemon start/stop resourcemanager/nodemanager- 1
- 关闭所有的YARN:resourcemanager/nodemanager所有,则:在配置NameNode的主机上执行
/opt/module/hadoop-3.1.3/sbin下的stop-yarn.sh文件。 - 关闭所有HDFS、YARN等,则在集群中的任意主机上执行
stop-all.sh文件。
- 关闭resourcemanager/nodemanager一个或多个,则在集群中的任意主机上输入:
(4) 启动 / 关闭 历史服务器
-
在配置JobHistoryServer的主机上的终端输入以下命令:
[hao@Hadoop102 hadoop]$ mapred --daemon start historyserver- 1
-
再输入
jps查看当前主机运行的 hdfs 的java进程和集群规划的是否一致。

-
如果要关闭历史服务器:
[hao@Hadoop102 hadoop]$ mapred --daemon stop historyserver- 1
第十步:集群测试
(1) Web端端测试
- Web端查看HDFS的NameNode:打开浏览器输入:
http://192.168.10.102:9870【192.168.10.102是配置机Hadoop102的IP】就可打开如下界面:

- Web端查看ResourceManager:打开浏览器输入:
http://192.168.10.103:8088【192.168.10.103是克隆机Hadoop103的IP】就可打开如下界面:
- Web端查看日志:
http://192.168.10.102:19888【192.168.10.102是克隆机Hadoop102的IP】就可打开如下界面:

(2) HDFS测试
-
在hdfs创建文件夹testDir:
- 命令方式创建:
[hao@Hadoop102 sbin]$ hadoop fs -mkdir /testDir- 1
- web界面创建:

- 命令方式创建:
-
查看创建的文件夹testDir:
- 命令查看:
[hao@Hadoop102 ~]$ hadoop fs -ls /testDir- 1
- 在web页面查看:
- 命令查看:
-
上传文件a.sh:
- 命令方式上传:
# 将 a.sh 文件 上传到 /testDir目录下 [hao@Hadoop102 temp]$ hadoop fs -put /home/hao/temp/a.sh /testDir- 1
- 2
- web界面上传:

注意:上传后,集群中的每台服务器都会存储一份a.sh文件,具体存储在
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-xxxxxxxx/current/finalized/subdir0/subdir0中。- 如果上传的是小文件,该目录下会生成一个文件,则用vim打开就是完整内容:

- 如果上传的是大文件,该目录下会生成多个文件,需要先用拼接命令,将多个文件拼接成一个完整文件,再用vim打开该文件就是完整内容:

- 命令方式上传:
-
下载文件a.sh:
- 命令方式下载:
hadoop fs -get /testDir/a.sh /home/hao/temp/aa.sh- 1
- web方式下载:

- 命令方式下载:
-
删除文件:
# Hadoop中: # 能 rm -f # 能 rm -r # rm -rf 要写成 rm -r -f (r、f要分开) [hao@Hadoop102 temp]$ hadoop fs -rm -f /testDir/a.sh- 1
- 2
- 3
- 4
- 5
(3) YARN测试
# 在任意地方 hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /testDir/a.sh /output- 1
- 2
然后通过yarn的web管理页面查看,可以发现多出来一个正在运行的wordcount任务。当yarn管理页面上的job状态变为
FINISHED时,代表着程序执行完毕,就可以在/output目录下查看到输出的结果/output/part-r-00000。

第十一步:时间同步
如果是集群中的主机都能连接外网,那么他们的时间一定是同步的。所以不需要配置时间同步。只有内网有服务器不能连接外网才需要将其与其他主机时间同步。故一般不需要配置
3. 补充
3.1 使用shell脚本启动集群
在
/home/hao/bin/下创建hadoop.sh脚本:

其内容为:#!/bin/bash if [ $# -lt 1 ] then echo "No args Input..." exit; fi case $1 in "start") echo "============= 启动hadoop集群 ======================" echo "------------- 启动 hdfs ---------------------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh" echo "------------- 启动 yarn ---------------------------" ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh" echo "---------- 启动 historyserver ----------------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver" ;; "stop") echo "================ 关闭hadoop集群 ==========================" echo "-------------- 关闭historyserver ------------------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver" echo "---------------- 关闭 yarn ------------------------------" ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh" echo "---------------- 关闭 hdfs ------------------------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh" ;; *) echo "Input Args Error..." ;; esac- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
然后命令为:
hadoop.sh stop是停止hdfs、yarn、历史服务器hadoop.sh start是启动hdfs、yarn、历史服务器
例如:
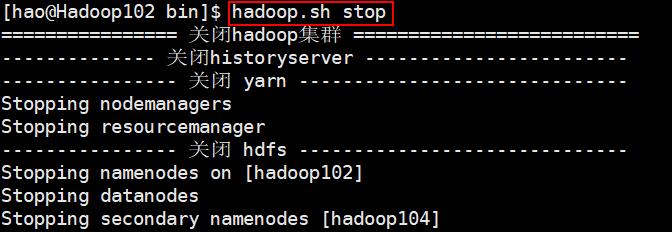
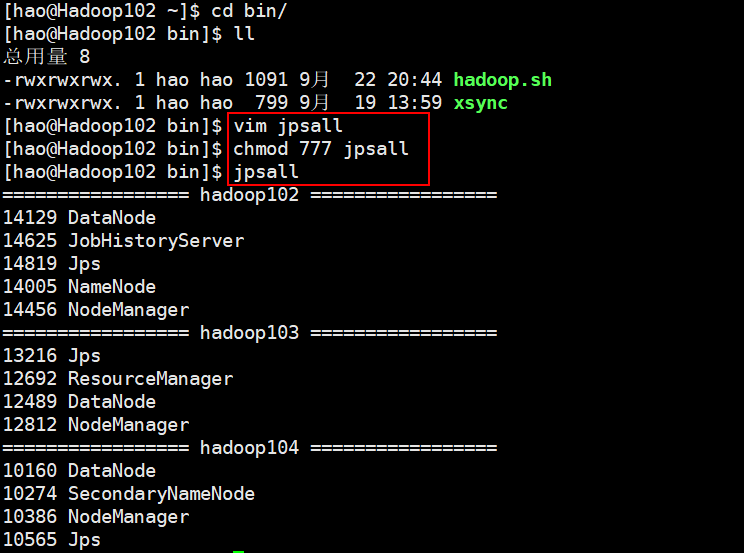
3.2 使用shell脚本查看所有服务器启动状况
在
/home/hao/bin/下创建jpsall脚本:#!/bin/bash for host in hadoop102 hadoop103 hadoop104 do echo ================= $host ================= ssh $host jps done- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.3 Hadoop常用端口和配置文件(面试题)
(1) 常用端口号
- Hadoop 3.x中:
- HDFS NameNode 内部通讯端口:8020/9000/9820
- HDFS NameNode 对用户的web查询端口:9870
- Yarn查看任务运行情况的web页面端口:8088
- 历史服务器对外暴露的web页面端口:19888
- Hadoop 2.x中:
- HDFS NameNode 内部通讯端口:8020/9000
- HDFS NameNode 对用户的web查询端口:50070
- Yarn查看任务运行情况的web页面端口:8088
- 历史服务器对外暴露的web页面端口:19888
(2) 配置文件:
-
- Hadoop 3.x中:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、workers
- hadoop 2.x中:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、slaves
3.4 集群崩溃时的处理
- 关闭
HDFS、Yarn、历史服务器。 - 删除所有服务器
/opt/module/hadoop-3.1.3下的data和logs文件 - 重新执行
启动集群步骤
-
相关阅读:
ROS2——DDS(十三)
现在公司都在用的CI/CD框架到底是什么?
【云原生 | Kubernetes 系列】--Gitops持续交付 实现从代码克隆到应用部署
buuctf-web-p6 [NPUCTF2020]web 狗
Vue组件自定义事件
山西电力市场日前价格预测【2023-10-06】
Android gradle编译常见的使用方式
C++之UDP通信例程
6. vector
04 Springboot 格式化LocalDateTime
- 原文地址:https://blog.csdn.net/qq_43546676/article/details/126910508