-
实验三 创建数据集(二)
实验3 第2章 创建数据集(二)
1.创建下图所示数据框stu,并进行相关操作

要求:
a) height属性通过产生均值为155,标准差为10的服从正态分布的随机数获得
> height<-trunc(rnorm(10,155,10)) > height [1] 151 156 171 152 149 154 155 150 135 164- 1
- 2
- 3

b) gender属性的获得随机生成。参考方案如:首先随机产生{0,1}二进制向量,然后依照ifelse函数将{0,1}映射为字符串”female”和“male”。
> x<-round(runif(10,0,1)) > x [1] 1 1 1 1 1 1 1 1 0 1 > x<-round(runif(10,0,1)) > x [1] 1 0 1 1 1 1 0 1 0 1 > gender<-ifelse(x<=0,"female","male") > gender [1] "male" "female" "male" "male" "male" "male" "female" "male" "female" "male"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
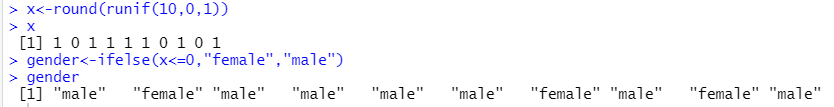
> stu<-data.frame(height,gender) > stu height gender 1 151 male 2 156 female 3 171 male 4 152 male 5 149 male 6 154 male 7 155 female 8 150 male 9 135 female 10 164 male- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

c) 将gender属性转换为因子gender_fac
> gender_fac<-factor(stu$gender) > gender_fac [1] male female male male male male female male female male Levels: female male- 1
- 2
- 3
- 4
- 5
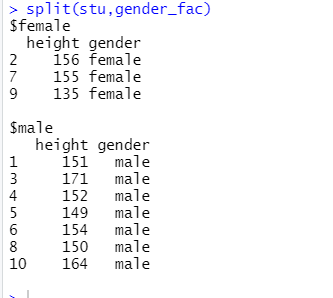
d) 使用split函数按照因子gender_fac对数据框进行分组。
> split(stu,gender_fac) $female height gender 2 156 female 7 155 female 9 135 female $male height gender 1 151 male 3 171 male 4 152 male 5 149 male 6 154 male 8 150 male 10 164 male- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
e)使用tapply()对stu的height向量依据因子gender_fac计算平均值
> tapply(height,gender_fac,mean) female male 148.6667 155.8571- 1
- 2
- 3

2.读取数据文件bus.csv,进行如下操作
(1) 统计不同站点的上车人数(tapply函数)
实验结果为:
1 2 3 4 5
35 35 20 30 19
> bus<-read.csv("E:/R语言/作业/bus.csv") > bus 线路名称 车牌号 到达站点 上车人数 1 81 冀A002 1 1 2 81 冀A001 4 6 3 81 冀A002 2 9 4 81 冀A003 3 4 5 81 冀A001 4 7 6 81 冀A003 1 10 7 81 冀A002 4 6 8 81 冀A003 2 1 9 81 冀A003 3 5 10 81 冀A003 5 0 11 81 冀A001 1 5 12 81 冀A003 3 3 13 81 冀A001 2 6 14 81 冀A003 4 9 15 81 冀A002 3 8 16 81 冀A003 2 3 17 81 冀A003 4 2 18 81 冀A003 1 1 19 81 冀A001 3 0 20 81 冀A003 2 6 21 81 冀A002 5 7 22 81 冀A003 5 0 23 81 冀A003 5 4 24 81 冀A003 2 9 25 81 冀A001 5 2 26 81 冀A003 1 9 27 81 冀A002 5 5 28 81 冀A003 5 1 29 81 冀A003 2 1 30 81 冀A001 1 9 > tapply(bus$上车人数,bus$到达站点,sum) 1 2 3 4 5 35 35 20 30 19- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37

(2) 按照车牌号分类,分别统计不同站点上车人数(split函数,sapply函数,tapply函数)
实验结果为:
冀A001 冀A002 冀A003
1 14 1 20
2 6 9 20
3 0 8 12
4 13 6 11
5 2 12 5
> tapply(bus$上车人数,list(bus$到达站点,bus$车牌号),sum) 冀A001 冀A002 冀A003 1 14 1 20 2 6 9 20 3 0 8 12 4 13 6 11 5 2 12 5- 1
- 2
- 3
- 4
- 5
- 6
- 7

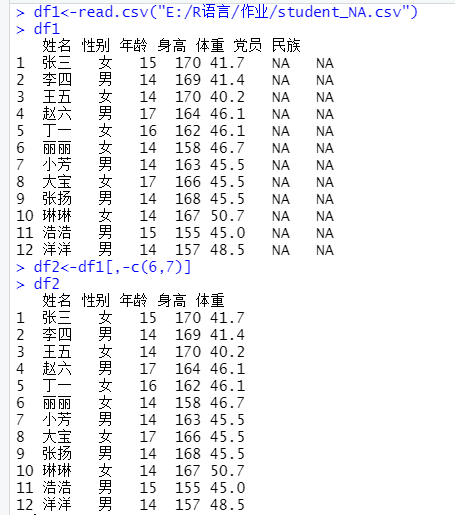
3.读取student_NA.csv文件到数据框df1,显示读取的数据框df1。删除数据框df1中的NA值所在的列,将结果保存到df2,显示df2。
> df1<-read.csv("E:/R语言/作业/student_NA.csv") > df1 姓名 性别 年龄 身高 体重 党员 民族 1 张三 女 15 170 41.7 NA NA 2 李四 男 14 169 41.4 NA NA 3 王五 女 14 170 40.2 NA NA 4 赵六 男 17 164 46.1 NA NA 5 丁一 女 16 162 46.1 NA NA 6 丽丽 女 14 158 46.7 NA NA 7 小芳 男 14 163 45.5 NA NA 8 大宝 女 17 166 45.5 NA NA 9 张扬 男 14 168 45.5 NA NA 10 琳琳 女 14 167 50.7 NA NA 11 浩浩 男 15 155 45.0 NA NA 12 洋洋 男 14 157 48.5 NA NA > df2<-df1[,-c(6,7)] > df2 姓名 性别 年龄 身高 体重 1 张三 女 15 170 41.7 2 李四 男 14 169 41.4 3 王五 女 14 170 40.2 4 赵六 男 17 164 46.1 5 丁一 女 16 162 46.1 6 丽丽 女 14 158 46.7 7 小芳 男 14 163 45.5 8 大宝 女 17 166 45.5 9 张扬 男 14 168 45.5 10 琳琳 女 14 167 50.7 11 浩浩 男 15 155 45.0 12 洋洋 男 14 157 48.5- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
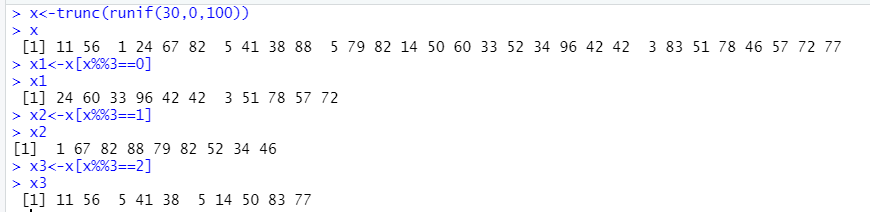
4.随机生成30个自然数, 然后把3的倍数的储存到一个向量,3k+1形式的数储存到另外一向量, 3k+2形式储存到第三个向量。写出R代码。
> x<-trunc(runif(30,0,100)) > x [1] 11 56 1 24 67 82 5 41 38 88 5 79 82 14 50 60 33 52 34 96 42 42 3 83 51 78 46 57 72 77 > x1<-x[x%%3==0] > x1 [1] 24 60 33 96 42 42 3 51 78 57 72 > x2<-x[x%%3==1] > x2 [1] 1 67 82 88 79 82 52 34 46 > x3<-x[x%%3==2] > x3 [1] 11 56 5 41 38 5 14 50 83 77- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
5.随机产生一个包括负数和正数的整数向量,元素的范围为-50,50,向量元素个数为10,负数采用1-负数替代,即-3变成4,正数用1+正数替代,即2变成3,怎么编写代码?(数据重编码)
> x<-trunc(runif(10,-50,50)) > x [1] -27 45 -40 -32 49 33 -31 -1 -4 -28 > x<-ifelse(x>0,1+x,1-x) > x [1] 28 46 41 33 50 34 32 2 5 29- 1
- 2
- 3
- 4
- 5
- 6
- 7

6.对R内部数据iris, 求出三类花各个属性的中位数.写出R代码.
> tapply(iris$Sepal.Length,iris$Species,median) setosa versicolor virginica 5.0 5.9 6.5 > tapply(iris$Sepal.Width,iris$Species,median) setosa versicolor virginica 3.4 2.8 3.0 > tapply(iris$Petal.Length,iris$Species,median) setosa versicolor virginica 1.50 4.35 5.55 > tapply(iris$Petal.Width,iris$Species,median) setosa versicolor virginica 0.2 1.3 2.0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
7.向量x=c(“我”,“你”,“我”,“我”,“你”,“他”,“们”,“他”,“人”)中,统计向量x中的字出现的次数。 写出R代码。
> x<-c("我","你","我","我","你","他","们","他","人") > x [1] "我" "你" "我" "我" "你" "他" "们" "他" "人" #方法1 > x1<-factor(x) > summary(x1) 们 你 人 他 我 1 2 1 2 3 #方法2 > x2<-table(x) > x2 x 们 你 人 他 我 1 2 1 2 3- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

8.构建一个向量x,向量由5个1,3个2,4个3和2个4构成。(使用rep())
> x<-rep(1:4,times=c(5,3,4,2)) > x [1] 1 1 1 1 1 2 2 2 3 3 3 3 4 4- 1
- 2
- 3
- 4

9.构造4×5矩阵A和B,其中A将1,2,…,20按列输入,B按行输入。矩阵C是由A的前3行和前3列构成的矩阵,矩阵D是由矩阵B的各列构成的矩阵,但不含B的第3列。
> A<-matrix(1:20,4,5) > A [,1] [,2] [,3] [,4] [,5] [1,] 1 5 9 13 17 [2,] 2 6 10 14 18 [3,] 3 7 11 15 19 [4,] 4 8 12 16 20 > B<-matrix(1:20,4,5,byrow = TRUE) > B [,1] [,2] [,3] [,4] [,5] [1,] 1 2 3 4 5 [2,] 6 7 8 9 10 [3,] 11 12 13 14 15 [4,] 16 17 18 19 20 > C<-A[1:3,1:3] > C [,1] [,2] [,3] [1,] 1 5 9 [2,] 2 6 10 [3,] 3 7 11 > D<-B[,-3] > D [,1] [,2] [,3] [,4] [1,] 1 2 4 5 [2,] 6 7 9 10 [3,] 11 12 14 15 [4,] 16 17 19 20- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27


10.设x=(1,3,5,7,9)T,构造5×3的矩阵X,其中第1列全为1,第2列为向量x,第3列的元素为x2,并给矩阵的3列命名,分别为Const, Univariate和Quadratic。
> x<-c(1,3,5,7,9) > Const<-c(1) > Univariate<-x > Quadratic<-x*x > X<-cbind(Const,Univariate,Quadratic) > X Const Univariate Quadratic [1,] 1 1 1 [2,] 1 3 9 [3,] 1 5 25 [4,] 1 7 49 [5,] 1 9 81- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

11.假设某班有50位同学,某门课程的平均成绩为75,标准差为5,成绩分布为正态分布,请生成服从该分布的成绩向量。
> score<-trunc(rnorm(50,75,5)) > score [1] 71 76 72 74 76 71 75 78 86 77 69 71 68 69 73 74 71 77 78 69 74 70 77 72 66 75 85 79 72 72 75 [32] 76 63 74 81 68 82 71 71 74 72 74 71 76 81 73 71 69 78 74- 1
- 2
- 3
- 4

12.图形处理:绘制散点图,根据不同因子,设置不同颜色
1.) 根据基础包basesets中的数据集airquality的两列数据:Wind 和Temp绘制散点图,图形标题为“The scatter plot of temp and wind”。散点图中点的属性自定。
2.) 每个月份对应一个颜色,数据对应到颜色上面,需要加上aes函数
> library(ggplot2) > ggplot(data=airquality,aes(x=Wind,y=Temp,color=factor(Month)))+ geom_point(shape=21,alpha=0.5,size=0.5,stroke=1.5)+ ggtitle("The scatter plot of temp and wind")- 1
- 2
- 3
- 4
- 5
12.图形处理:绘制散点图,根据不同因子,设置不同颜色
1.) 根据基础包basesets中的数据集airquality的两列数据:Wind 和Temp绘制散点图,图形标题为“The scatter plot of temp and wind”。散点图中点的属性自定。
2.) 每个月份对应一个颜色,数据对应到颜色上面,需要加上aes函数
> library(ggplot2) > ggplot(data=airquality,aes(x=Wind,y=Temp,color=factor(Month)))+ geom_point(shape=21,alpha=0.5,size=0.5,stroke=1.5)+ ggtitle("The scatter plot of temp and wind")- 1
- 2
- 3
- 4
- 5
-
相关阅读:
S7-1200/1500程序设计规范指南之二:定义
33.2.4 配置Mycat负载均衡
【GEE笔记9】数值Number(常见指令方法2)
20240810将荣品RK3588S-AHD开发板的USB3.0口切换为HOST模式接鼠标和U盘
低功耗工业RFID设备应用
输电线路分布式故障监测装置:准确定位故障点、辨识故障原因
QSqlTableModel使用简介
Photographic Tone Reproduction for Digital Images
Java 代码性能基准测试
为什么Move将超越Solidity成为主流编程语言?
- 原文地址:https://blog.csdn.net/W_chuanqi/article/details/126917363
