-
深度学习之文本分类 ----FastText
- ❤️ 作者简介:大家好我是小鱼干儿♛是一个热爱编程、热爱算法的大三学生,蓝桥杯国赛二等奖获得者
- 🐟 个人主页 :https://blog.csdn.net/qq_52007481
- ⭐ 个人社区:【小鱼干爱编程】
- 🔥 算法专栏:算法竞赛进阶指南
- 💯 刷题网站:市面上的刷题网站有很多如何选择一个适合自己的网站呢,博主给这里推荐一款我常用的刷题网站 👉点击跳转
FastText
FastText是一种典型的深度学习词向量的表示方法,它非常简单通过Embedding层将单词映射到稠密空间,然后将句子中所有的单词在Embedding空间中进行平均,进而完成分类操作。
FastText是一个三层的神经网络,输入层、隐含层和输出层。
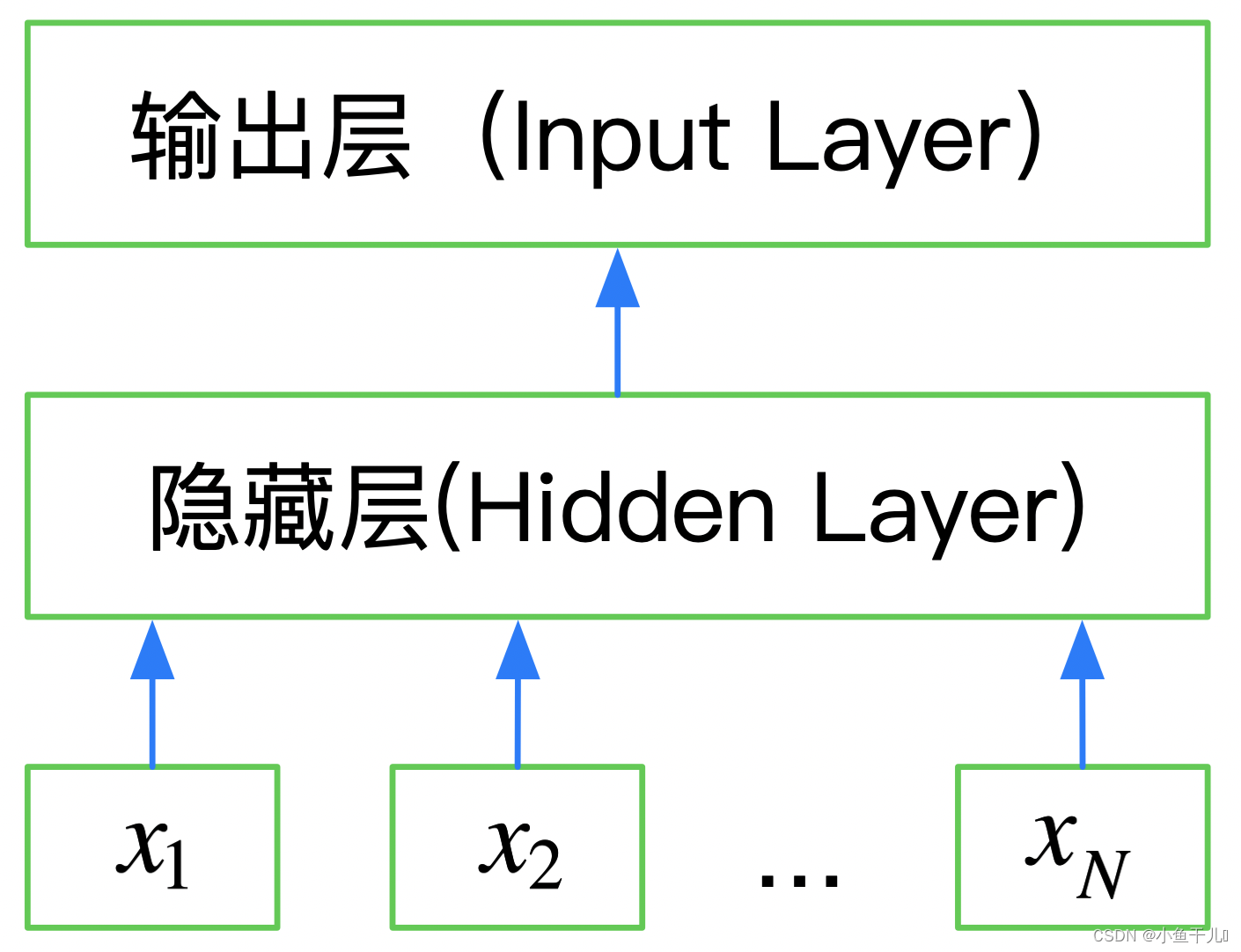
FastText的优点:使用浅层的神经网络实现了word2vec以及文本分类功能,效果与深层网络差不多,节约资源,且有百倍的速度提升
深度学习和机器学习的区别:
与传统机器学习不同,深度学习既提供特征提取功能,也可以完成分类的功能。机器学习需要再根据提取到的特征再进行分类。
安装FastText
使用pip安装pip install fasttext- 1
因为FastText依赖C++的环境,安装的时候可能会报错,有的是C++ 11
有的是C++14看报错里面缺少那个版本的C++环境就安装那个版本的环境就可以了使用FastText进行文本分类的一般步骤
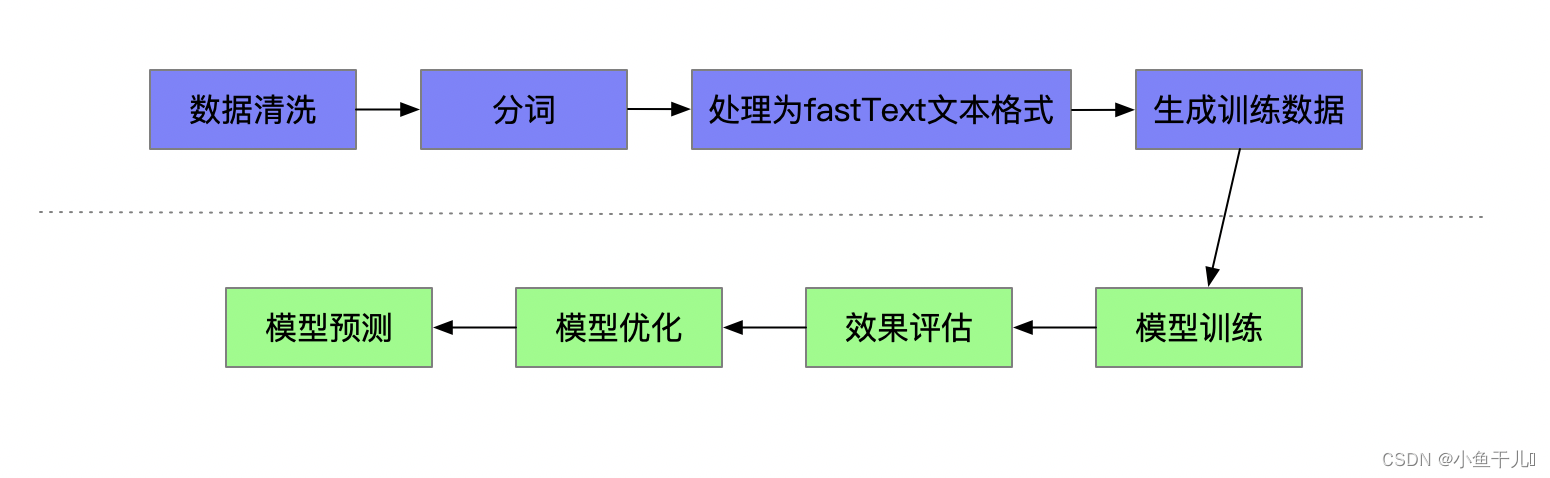
数据格式的要求:
__label__标签 文本内容 或 文本内容 __label__标签 __label__标签\t文本内容 或 文本内容\t__label__标签 文本内容和标签之间用\t或空格都可以 目前这几种形式都支持- 1
- 2
- 3
- 4
数据预处理:
将原数据处理为数据要求的格式,分词以后词于词之间用空格连接
这个根据自己数据的情况自己进行处理
训练模型import fasttext model = fasttext.train_supervised('train.csv', lr=1.0, wordNgrams=2, verbose=2, minCount=1, epoch=25, loss="hs") # 训练模型 # train.csv 文件路径,也可以是txt文件,里面的参数根据需要调 """ 训练一个监督模型, 返回一个模型对象 input: 训练数据文件路径 lr: 学习率 dim: 向量维度 ws: cbow模型时使用 epoch: 次数 minCount: 词频阈值, 小于该值在初始化时会过滤掉 minCountLabel: 类别阈值,类别小于该值初始化时会过滤掉 minn: 构造subword时最小char个数 maxn: 构造subword时最大char个数 neg: 负采样 wordNgrams: n-gram个数 loss: 损失函数类型, softmax, ns: 负采样, hs: 分层softmax bucket: 词扩充大小, [A, B]: A语料中包含的词向量, B不在语料中的词向量 thread: 线程个数, 每个线程处理输入数据的一段, 0号线程负责loss输出 lrUpdateRate: 学习率更新 t: 负采样阈值 label: 类别前缀 verbose: ?? pretrainedVectors: 预训练的词向量文件路径, 如果word出现在文件夹中初始化不再随机 model object """- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
预测数据
使用predict预测数据,预测一段文本属于的类别model.predict(x) # x文本内容 返回的数据格式(('__label__4',), array([0.99441689])) # 可能性最大的标签和准确率- 1
- 2
- 3
使用
test验证模型的准确率,传入的是一个文件,文件的格式和训练集一样
返回一个元组(样本数,精确率,找回率)模型的保存
model.save_model("model_cooking.bin") # 文件路径- 1
模型读取
fasttext.load_model("model_cooking.bin") # 读取模型- 1
模型的优化
直接使用默认参数去训练模型一般都得不到特别好的结果,可以通过一些手段来优化模型。第一种可以采取的手段是去掉语料库当中的停止词,对于英文的语料库来说,还可以把所有的大写字母都转化成小写字母。另一种可以采取的手段是调整超参数,比如说修改学习速率、修改epoch等,大家可以参照着fastTest的文档去进行相应的调整,fastText的文档中介绍了一种更加方便的自动调参方法,只要我们同时提供训练集和测试集就可以了,带来的精确度提升还是非常显著的:
model = fasttext.train_supervised(input='train.csv', autotuneValidationFile='test.csv', autotuneDuration=600) """ autotuneValidationFile='test.csv', 测试集数据集 autotuneDuration=600 时间限制,单位为秒,默认为5分钟 """ # 如果想查看对应的参数,可以使用 对象.属性的方式进行查看- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
举例:

使用FastText进行文本分类的基本操作就是这些内容,关于深层次的学习大家可以参考
https://fasttext.cc/docs/en/autotune.html -
相关阅读:
计算机毕业设计ssm高校学生宿舍管理系统183rq系统+程序+源码+lw+远程部署
前端导出Excel并下载到本地
Vue.config.js配置详解
Swift运行时(派发机制)
GBase 8c 分析表
设计模式(二)-创建者模式(3)-抽象工厂模式
Android绘图学习(一)
安装黑苹果常见问题总结
[附源码]计算机毕业设计JAVAjsp图书借阅系统
Animator动画状态机
- 原文地址:https://blog.csdn.net/qq_52007481/article/details/126628609