-
DelayQueue的源码分析
DelayQueue是延时队列,可以用于定时任务。比如有多个不同时间点需要执行的任务都可以放到这个队列中,取出任务时会按照时间点的顺序被取出。那DelayQueue是如何实现的呢?其实DelayQueue内部维护了一个优先队列:PriorityQueue。这个队列保证了可以按照时间顺序取出要执行的任务,PriorityQueue队列的作用其实就是将任务按照执行时间排序。DelayQueue还保证了任务在执行时间到了才能被取出执行。下面将分析如何实现优先队列?如何确保在任务执行的时间点才能取出任务?
PriorityQueue优先队列
PriorityQueue是一个优先队列,也就是说添加到PriorityQueue中的元素不是按照加入PriorityQueue的先后顺序排放的,而是由元素的优先级来决定元素在PriorityQueue中的位置。其实就是按照任务的优先级维护了一个大/小顶堆结构,如果熟悉堆排序那么能理解PriorityQueue是如何排序的了。
PriorityQueue的底层是一个数组结构,在创建PriorityQueue时可以指定一个数组长度不指定长度会有一个默认长度(11),PriorityQueue的数组长度会根据情况自增长。
PriorityQueue的底层是数组但是在逻辑上被看作是完全二叉堆,存入PriorityQueue的元素会被构建成大/小顶堆。处于堆顶的元素就是优先级最高的,因此每次取出元素都是去获取处于堆顶的元素,堆顶对应数组的下标:0;获取堆顶的元素之后需要重新调整堆使之满足大/小顶堆的性质;因此在源码中会看到每次poll获取元素都是取的下标0处的元素,并且获取元素之后会调整堆;
大顶堆:堆顶的值大于左右子节点的值;小顶堆:堆顶的值小于左右子节点的值。下面以小顶堆为例,做一个简单的介绍:
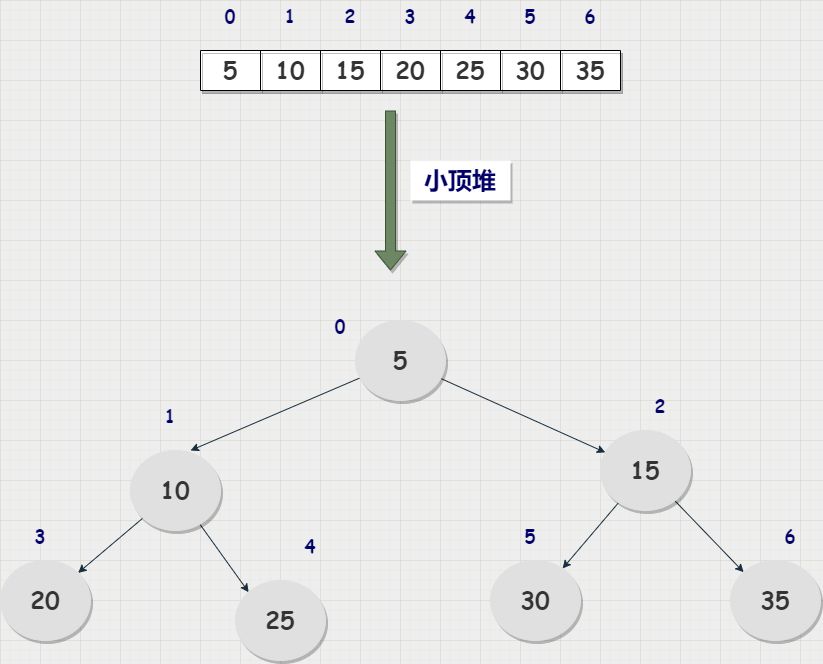
从上图可以看到每一个处于堆顶的值都要比它的左右子节点的值小。处于最顶端的堆顶值是整个堆的最小值。也可以观察到父节点和左右子节点之间下标的关系:
- leftIndex = 2 * parentIndex + 1 ,(leftIndex -1)/ 2 = parentIndex ;
- rightIndex = 2 * parentIndex + 2,(rightIndex -1)/ 2 = parentIndex;
以上图为例,现在添加一个元素:18,新加入元素在数组的下标是:7;调整堆的过程如下:

过程比较简单就是用新节点的下标找到父节点的下标,取出父节点的值与新加入的元素比较;如果newValue < parentValue ;就将newValue调整到这个小堆的堆顶;由于调整之后会影响到parenIndex作为子节点的堆,因此需要继续向上检查;
接下来就是,取出堆顶值堆的调整过程:

取出堆顶的值之后,将数组的最后一个元素放在堆顶上;找到堆顶的左右子节点,先找出子节点中较小的数;然后这个较小的数与堆顶的值比较;如果堆顶的值调整了,那就会影响子节点作为堆顶的小堆,此时需要向下调整;PriorityQueue调整堆的源码
在PriorityQueue中,添加元素调整堆的方法:
public boolean offer(E e) { if (e == null) throw new NullPointerException(); modCount++; int i = size; if (i >= queue.length)//扩容 grow(i + 1); size = i + 1; if (i == 0) queue[0] = e; else siftUp(i, e);//调整堆 return true; } //siftUpUsingComparator,siftUpComparable方法的调整过程都一样,只是使用的比较大小的类不一样。只看其中一个方法 private void siftUp(int k, E x) { if (comparator != null) siftUpUsingComparator(k, x); else siftUpComparable(k, x); } /* * k:新元素的下标 * x:新元素 */ private void siftUpUsingComparator(int k, E x) { while (k > 0) { //使用位运算,找parent下标,效率更高;(k - 1) >>> 1 <=====> (k-1)/2 这2个算法是等价的; int parent = (k - 1) >>> 1; Object e = queue[parent]; if (comparator.compare(x, (E) e) >= 0)//新元素与parent比大小 break;//新元素 x >= parent 结束;否则更换堆顶值,继续向上检查; queue[k] = e; k = parent; } queue[k] = x; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
在PriorityQueue中取出堆顶元素之后,调整堆的方法:
public E poll() { if (size == 0) return null; int s = --size; modCount++; E result = (E) queue[0];//取堆顶的值 E x = (E) queue[s];//获取数组最后一个元素 queue[s] = null; if (s != 0) siftDown(0, x);//调整堆;将最后一个元素放在堆顶(数组下标 0)的位置重新调整堆 return result; } //siftDownUsingComparator,siftDownComparable也都一样,只分析一个方法 private void siftDown(int k, E x) { if (comparator != null) siftDownUsingComparator(k, x); else siftDownComparable(k, x); } private void siftDownComparable(int k, E x) { Comparable<? super E> key = (Comparable<? super E>)x; int half = size >>> 1; // loop while a non-leaf while (k < half) { int child = (k << 1) + 1; // 找到 堆的左节点下标 Object c = queue[child]; int right = child + 1; // 找到 堆的右节点下标 if (right < size && ((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)//先左右子节点比较 c = queue[child = right];//选出左右子节点较小的数: c if (key.compareTo((E) c) <= 0)//较小的数与堆顶的值比较 break;//堆顶小于 c;也就是堆顶值不变;此时左右子节点的值也没变,因此不必继续往下检查 //堆顶值 不是最小,那么堆顶值与其中一个子节点的值发生交换,这影响到了子节点作为堆顶的堆 //就需要继续往下检查 queue[k] = c; k = child; } queue[k] = key; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
对向下调整的边界值做一个说明;从父节点与子节点的关系可以求出最后一个堆顶的坐标;lastParent = ((size-1)- 1)/ 2 = size/2 -1 ; 当调整完之后一个堆之后,后续没有堆就可以停止调整了。因此向下调整的结束条件 index <= size/2 -1 即 index < size/2。
如何使用PriorityQueue构建大顶堆
上节分析过PriorityQueue调整堆的源码,看源码知道它的比较对象大小的方法是compareTo,通过compareTo返回结果的正负数来判断2个对象的大小。源码中,将compareTo判定较小的值放堆顶;一般情况都是构建的小顶堆,因为 当子节点a 与父节点 b 比较大小时 a < b返回负数,就会将a的值赋值给堆顶,这样就形成了小顶堆。如果想要构建大顶堆,只需要将结果取相反数就可以构建出大顶堆;a > b 返回负数,会将a赋值给堆顶;a是较大数这样会使整个堆构建成大顶堆,举个例子:
@Test public void test1() { //创建PriorityQueue时,传入一个匿名内部类Comparable对象,定义compareTo方法 PriorityQueue<Integer> priorityQueue = new PriorityQueue<Integer>((q,a)-> q > a ? -1:1); for (int i = 5; i <= 40; i+=5) { priorityQueue.add(i); } //数组中下标 0 -> size -1 的元素 priorityQueue.forEach((x)->System.out.print(x +"\t")); System.out.println("\n==============================="); Iterator<Integer> iterator = priorityQueue.iterator(); for (; iterator.hasNext();) { //每次都取堆顶的值 System.out.print(priorityQueue.poll() +"\t"); } } ======================================result============================================== 数组中元素的顺序:(这是一个大顶堆的结构) 40 35 30 20 15 10 25 5 =============================== 按顺序利用poll获取堆顶的值:(每次获取堆顶的值之后都会重新调整堆,因此每次都是获取剩余值中的最大值) 40 35 30 25 20 15 10 5- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
数组中元素顺序,对应的大顶堆结构:

DelayQueue
由于PriorityQueue不是一个线程安全的队列,使用PriorityQueue的正确方式是在单线程中使用。而DelayQueue是在多线程环境下使用的,因此每次在DelayQueue方法中调用PriorityQueue方法之前都会获取锁,这样才能保证使用PriorityQueue时不会出现线程安全问题。在DelayQueue中添加了一个条件队列,在队列中没有任务或者当前时间没有到达执行任务的时间时调用take方法获取元素时会阻塞线程。
take获取任务的流程
take流程图

leader是等待执行队列中第一个任务的线程;
delay:获取任务时间与任务规定的执行时间差值。时间单位:纳秒。(在阻塞线程时用调用:awaitNanos(long nanosTimeout)方法,因此这里要将时间换算成纳秒)available:是条件队列,有2种情况会阻塞队列:
- 当priorityQueue有任务节点时:线程获取队列中的任务节点但是执行任务的时间还没有到的时候就会将线程阻塞到available队列中
- 当priorityQueue队列中没有任务节点:线程获取任务时,会阻塞线程;
举个例子,假设有3个定时任务分别要在:16:00,17:00,18:00执行;现在将3个定时任务放入DelayQueue队列中,分别在三个时间点执行对应的任务。

将3个定时任务放在队列中之后,在15:00,15:30分别有 T1,T2线程来获取任务;T1线程是第一个来获取队列中的任务;此时会用任务时间与当前时间计算差值,查看是否已经到了执行任务的时间。15:00这个时间点还没有到队列中第一个任务的执行时间,因此会阻塞线程,让该线程等到任务执行时间再恢复运行;等待时间:任务执行时间与当前时间的差值;
在阻塞T1前还会做一个标记,用leader来标识T1。表示T1是第一个等待获取队列中任务的线程。当有其他线程获取队列任务计算delay之后需要阻塞线程时,发现已经有线程在等待获取任务会将后来线程阻塞,并且这个阻塞是不限时的。
如上图中T2线程获取队列中的第一个任务时,发现还没到任务执行时间会被阻塞。这时检查leader标记发现已经有线程在等待获取第一个任务了。这个时候,第一个任务会被T1线程取走。而T2只能等T1取走队列中第一个任务之后,获取队列中的第二个任务。这个时候不再设置等待时间。因为获取的是队列中的第二个任务,任务时间不能确定设置等待时间也就没有意义。只能让T1恢复运行获取到第一个任务之后再将T2唤醒,T2被唤醒之后再去获取队列中剩余任务的第一个。
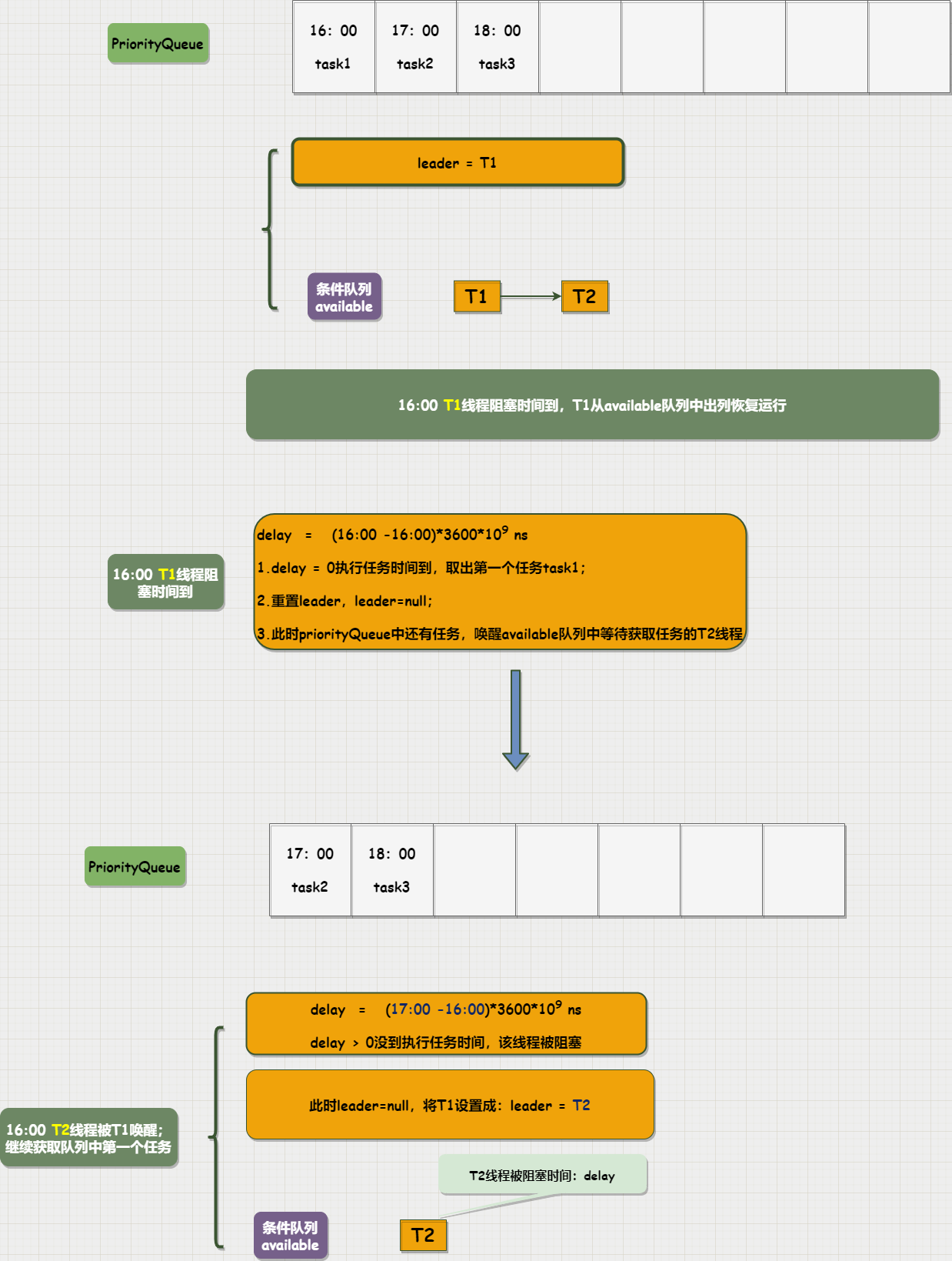
通过上面的例子可以理解条件队列的入队出队机制是如何保证没到任务执行时间时阻塞线程,以及如何唤醒条件队列中后续线程继续获取任务队列priorityQueue中任务的。
这个例子描述了在priorityQueue队列中有任务节点时如何阻塞线程,如何唤醒线程;还有一种阻塞线程的情况:如果线程获取任务时发现队列中没有任务节点也会将线程阻塞。那这个时候线程如何被唤醒呢?
在向任务队列priorityQueue中添加任务时,如果添加的任务节点排在在队列的第一个时会将available条件队列中的第一个线程唤醒。这就保证了当priorityQueue队列中没有任务节点将线程阻塞之后,当有新节点添加进队列时能将其唤醒。
public boolean offer(E e) { final ReentrantLock lock = this.lock; lock.lock(); try { q.offer(e);//添加任务节点 //新节点被排到PriorityQueue的头部就唤醒available队列中的第一个线程 if (q.peek() == e) { leader = null; available.signal(); } return true; } finally { lock.unlock(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在offer方法中,只要新节点被排在priorityQueue队列的头部就会将available队列中的线程唤醒。为什么要这么做呢?
被阻塞在available队列中的第一个节点有2种被阻塞的情况:
- 1.当priorityQueue队列种没有任务节点时,有线程调用take被阻塞。
- 2.在priorityQueue队列种有任务节点,但是没到执行时间这个时候调用take方法也会被阻塞。
第一种情况,被阻塞的线程没有设置阻塞时间,需要被别的线程唤醒。
第二种情况,被阻塞的线程成为leader,并且设置了阻塞时间到了时间会恢复运行。这个时候还有必要将其唤醒吗?
答案是应该将其唤醒,执行新任务或者刷新等待时间。举个例子:当前时间10:00,当前priorityQueue队列中的第一个任务执行时间是:20:00。在10:00开始陆续有线程调用take获取任务;在10:00 ~ 20:00期间添加向priorityQueue队列中添加了几百个任务,并且任务执行时间都是在20:00之前。在这期间如果唤醒了available队列中等待获取任务的线程是可以分批执行的,但因为没有唤醒available中等待执行任务的线程而导致任务大量堆积。在20:00的时候会造成这几百个任务都是可执行的,服务器在短时间内就需要创建大量的线程来执行这些任务,这会给服务器很大的压力。
思考
1.在take方法中,为什么在线程获取到任务之后唤醒available队列中的其他线程时要判断:leader == null && p.peek() != null ?
在priorityQueue中peek方法会返回priorityQueue队列的第一个任务节点。如果第一个任务节点为空,说明当前时间节点priorityQueue队列是一个空队列。既然是空队列,那自然不用唤醒available条件队列中的线程。如果唤醒available队列中的线程,被唤醒的线程会去获取PriorityQueue队列中的任务节点;而现在PriorityQueue队列是空的,因此没有必要唤醒。
为什么要判定 leader == null ?
如果leader==null说明当前线程在available队列中的时候是leader,在当前线程获取到任务节点之后将leader设置为null。leader == null ,说明还没有线程成为新的leader,此时就需要当前线程唤醒available队列中的后续节点让其继续获取PriorityQueue队列中的其他任务节点。没有这个唤醒机制available队列中的线程就会永远阻塞在available队列中。
如果leader != null 说明已经有了新的leader,那唤醒available队列中其他节点的任务就交给新的leader线程。
2.为什么在available队列中的第一个线程在阻塞了delay纳秒恢复运行之后,要将leader设置为null?
public E take() throws InterruptedException { 。。。。 。。。 Thread thisThread = Thread.currentThread(); leader = thisThread; try { available.awaitNanos(delay); } finally { if (leader == thisThread) leader = null; } 。。。 。。 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
因为当available的第一个线程恢复运行之后,说明这个线程已经不在available队列中了。而leader是表示在available种等待获取PriorityQueue队列中第一个任务的线程,线程不在available队列中自然需要将leader设置为null。
在恢复运行之后直接设置leader == null不行吗?为什么还要判断leader是不是当前线程?
在offer方法中,当新加入的任务节点排序后处在队列头部这时会直接将available队列中的第一个节点唤醒;在唤醒之前会将leader的值设置为null;而调用signal方法唤醒线程,只是将线程从条件队列:available转移到同步队列中,线程能够从阻塞状态到恢复运行还需要获取到锁。在获取到锁的期间可能有其他线程调用take被阻塞成为新的leader。这个时候如果不加判断直接设置leader=null就有问题。
3.在offer方法中,有唤醒available队列中节点的机制。如果没有这个唤醒机制,那available队列中的线程在什么情况下会一直阻塞?
在priorityQueue队列中没有任务节点时,线程调用take被阻塞。这个时候等待的线程没有设置阻塞的时间,需要被别的线程唤醒。假设后续的所有线程执行的操作是先take获取任务节点,后offer添加任务节点。就会造成available队列中的节点不会被唤醒一直阻塞。
假设有刚开始有11个线程对DelayQueue进行take,offer操作;其中有5个take线程,6个offer线程。5个take线程先调用被阻塞在available队列中;后续的6个offer线程再给DelayQueue添加任务节点。这个时候如果后续没有take线程全都是offer线程,那么这5个take线程会被一直阻塞。
-
相关阅读:
java集成datax
前端 JS 经典:浏览器中 ESModule 的工作原理
Spring Boot常见面试题
存储型XSS和BEEF浏览器攻击框架
【附源码】计算机毕业设计JAVA重工教师职称管理系统
时间序列论文-聚类和异常检测(二)
Mybatis动态SQL
[轻笔记] SHAP值的计算步骤
db2数据仓库集群的搭建
CMake重要指令&常用变量
- 原文地址:https://blog.csdn.net/m0_37550986/article/details/126882839
