-
【调研】国内芯片公司对于存算一体芯片的相关调研
理论研究
清华大学 Fully hardware-implemented memristor convolutional neural network
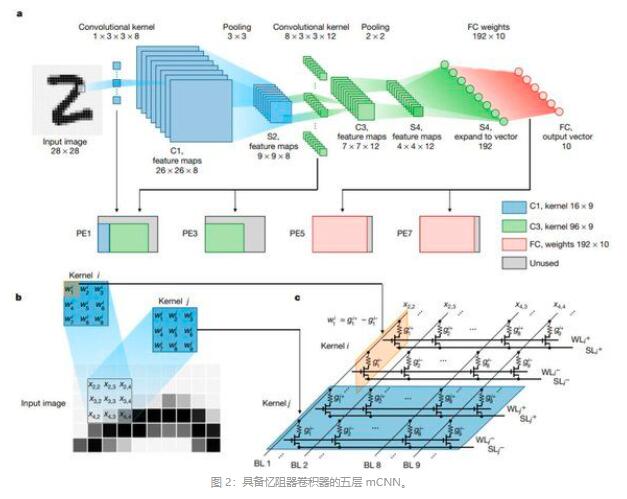
2020年1月29号,清华大学微电子所等机构在 Nature 上发表了首个完全基于忆阻器的 CNN 存算一体芯片。

该项工作中开发的阵列芯片集成了 8 个包含 2048 个忆阻器的列阵,并构建的基于忆阻器的五层 CNN 在 MNIST 手写数字识别任务中实现了 96.19% 的准确率,为大幅提升 CNN 效率提供了可行的解决方案。

该阵列展示了极具可重复性的多级电导率状态,如图 1c 测试结果所示。图 1c 展示了 1024 个忆阻器在 32 个不同电导率状态中的分布,其中所有曲线均独立且没有重叠。将使用 50 ns 脉宽训练的相同 SET 和 RESET 脉冲部署到闭环编程操作中,以达到特定的电导率状态。

落地实践
后摩智能
业内首款存算一体大算力AI芯片,成功跑通智能驾驶算法模型,采用SRAM作为存算一体介质,通过存储单元和计算单元的深度融合,实现高性能和低功耗,样片算力达20TOPS,可扩展至200TOPS,计算单元能效比高达20TOPS/W。

苹芯科技
基于SRAM架构的存内计算加速器已测试成功。值得关注的是,这款加速器首次将商用存内计算带入28nm时代。
亿铸科技
基于ReRAM(RRAM)全数字存算一体大算力AI芯片,可切实将存算一体架构在大算力、高能效比的芯片平台应用并落地,这一技术通过稀疏化的设计原理以及无需AD/DA(数模转换)部分,将芯片的面积和能耗用于数据计算本身,从而实现大算力和高精度的多维度满足。
ReRAM的优势在于非易失、密度大、密度上升空间巨大、能耗低、读写速度快、成本低、稳定、兼容CMOS工艺等特点。
即将于2023年上半年推出自己的第一代芯片,并于同年投片第二代芯片。知存科技
知存科技第二代芯片WTM2101是一个基于Flash的存算一体芯片,可以实现一些深度学习算法,同时有加速单元可以加速算法,也有RAM存储数据,同时这个芯片针对语音做了很多工作,也可以做一些算法级应用,包括语音识别等。
芯片内包含 Timer、WDT、RTC、VAD 以及电源管理(PMU)等功能模块;外围接口上,具备多种常见外围接口,包括UART、SPI、I2C、I2S、PWM 以及 GPIO。加上 WTM2101 采用 WLCSP 极小封装,非常适合小体积、功耗要求苛刻的离线语音识别产品。芯片型号:WTM2101
芯片类型:超低功耗AI SOC芯片
应用: 智能语音和智能健康
封装:WLCSP(2.7x3.1mm2)
功耗:5uA-3mA
AI算力:50Gops
最大模型参数:1.8M清华大学 Fully hardware-implemented memristor convolutional neural network 详细分析
一个典型的CNN计算过程包括大量的卷积操作,非常需要能够支持并行乘法累加运算(MAC)的计算单元,这个需求导致了包括GPU以及一些专用的神经网络加速器的出现,但是他们受限于冯诺依曼体系结构,因为内存和处理单元在物理上是分离的,他们之间的交互就会带来性能的损耗与时延的增加。
相比之下,基于忆阻器的存内计算结构就会有很大的优势,直接使用欧姆定律来做乘法和基尔霍夫电流定律来做加法,一个忆阻器阵列能够实现并行存内MAC操作。但是以往的研究并不是完全基于忆阻器构建硬件系统的,因为首先生产的忆阻器CNN芯片经常有低良率和忆阻器阵列不统一的问题,然后因为硬件本身的不完美(工艺偏差、电导漂移和器件状态死锁)很难实现和软件结果相媲美的表现,还有就是全连接向量-矩阵乘法(VMM)将导致忆阻器卷积器和忆阻器阵列之间的速度不匹配。
我们优化了材料堆栈,使得2048个1T1R构成的阵列中有着可靠的和统一的模拟开关特性,并且混合训练策略对于整个测试数据集的识别准确率达到了96.19%。更进一步地,将卷积核复制到三个并行的忆阻器卷机器将忆阻器CNN的延迟大约减少了1/3。
忆阻器单元使用TiN/TaO_x/HfO_x/TiN构成的材料堆栈,在增强(置位)和抑制(复位)过程中通过调节电场和热量,表现出连续的电导调控能力。材料和制造过程和传统的CMOS过程相兼容,减少过程偏差和实现高重复率,从而提高良品率解决忆阻器阵列不统一的问题,并且生产的交叉阵列表现出统一的模拟开关特性。

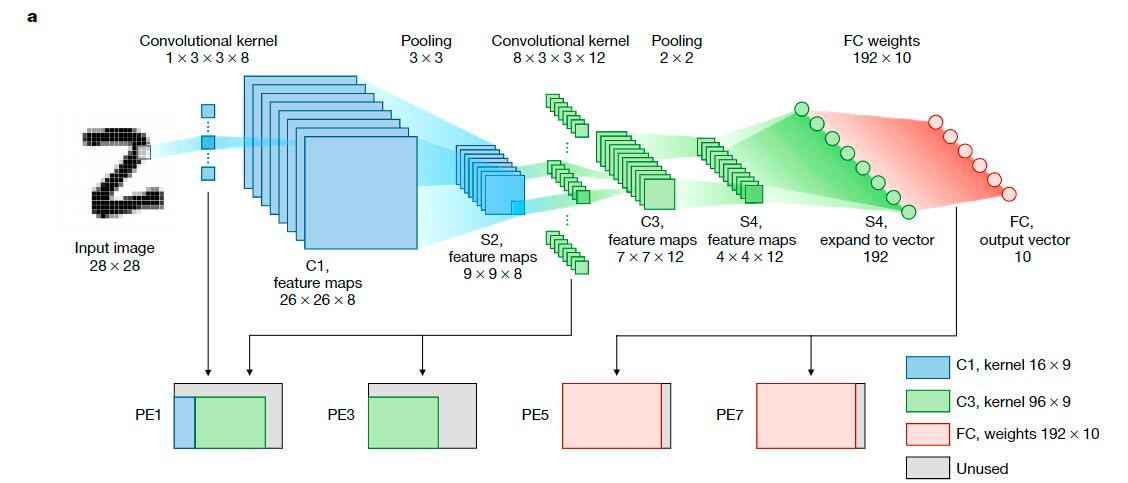
忆阻器阵列在共享不同核的输入的条件下,可以很高效的实现并行MAC。图2b展示了一个典型的卷积示例在滑动过程中的示意图,图2c揭示了在1T1R忆阻器阵列中的相关操作。输入值依据它被量化的位码、通过脉冲的数量来编码。一个有符号的核权重,被映射到一对忆阻器的电导的差分。在这种方法下,一个核中的所有权重都被映射到两行电导上:一行通过正的脉冲输入来表示正的权重,另一行通过大小相等的负脉冲来表示负的权重。在将编码脉冲输入到位线之后,通过两条差分电源线上的输出电流被探测和求和。差分电流是相应于输入批量(数据)和选中核的加权和。有着不同权重的不同核被映射到不同对的差分行,并且整个忆阻器阵列在相同的输入下并行地执行MAC。所有想要的加权和结果可以同时得到。
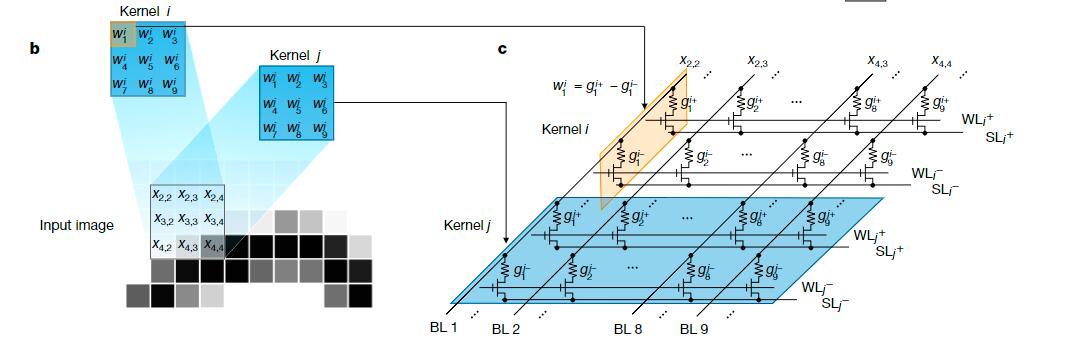
在典型的CNN训练中,有必要根据最后的输出反向传播目标梯度,来达到更新所有权重的目的。这项任务要求相当复杂的操作,来将编码读脉冲从后向前、一层一层地应用于电源线。而且,由于器件的不理想特性,例如非线性和非对称的电导调节,训练一个复杂的深度神经网路是有挑战性的。相比于纯粹的原位训练方案,异位训练看起来像是一条利用了已有的高性能参数的捷径。然而,不可避免的硬件缺陷,例如器件缺陷和导线的寄生电阻与电容,将使得在把异地学习到的权重转移到忆阻器电导时,权重变得模糊并且使系统的性能下降。因此,异位训练在正常情况下需要提前了解硬件的情况,并且基于这种代价高昂的认识,使用软件来学习权重。
为了避免各种不理想的器件特性,我们提出一种混合训练方法来实现忆阻器卷积神经网络。在图3a中展示的整个流程表包含两个阶段。首先,一个CNN模型进行异位训练,之后所有被确定的权重通过一种闭合回路写入的方法传输到忆阻器处理单元。

图 3:利用混合训练方法得到 mCNN。
a:实验所用混合训练方法的流程图。b:实验中使用混合训练方法训练 mCNN 的图示。首先,系统将不同卷积层的核权重以及 192 × 10 FC 权重迁移至忆阻器 PE。然后,系统保持核权重不变,仅通过实时训练更新 FC 权重。c–e:与 C1 层(c,大小为 8 × 9)、C3 层(d,大小为 96 × 9)和 FC 层(e,大小为 120 × 16)中的核权重目标值相比,权重迁移误差(weight-transfer error)的分布情况。彩条表示权重迁移误差的绝对值。f:经过 550 次混合训练迭代循环后的误差率轨迹。绿色曲线表示 55,000 张训练图像上的趋势,蓝色曲线表示 10,000 张测试图像上的趋势。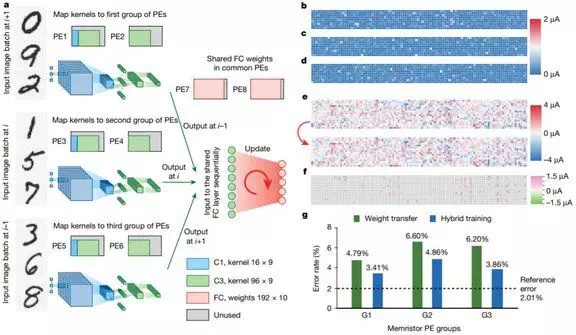
图 4:使用混合训练方法得到的并行忆阻器卷积器,可以提升卷积效率。
a:使用混合训练方法的硬件系统操作流程图,其为并行忆阻器卷积器调节不完美的设备特性。三批输入图像(左侧手写数字)输入到三个 PE 卷积器组中。所有处理后的中间数据输入到共享 FC PE 中,以完成实时调整。在神经网络图中,蓝色表示卷积层 C1 和子采样层 S2,绿色表示卷积层 C3 和子采样层 S4。在 PE 图中,蓝色区域表示 C1 层的卷积核,绿色区域表示 C3 层的卷积核。b–d:从 C1 和 C3 层的异地训练核权重映射到三个不同组 G1 (b)、G2 © 和 G3 (d) 的权重迁移误差分布。色彩图的大小是 104 × 9。彩条表示在 0.2-V 读数脉冲处迁移后的当前值中存在的误差。e:实验 FC 权重分布 (120 × 16) 在混合训练前(上)后(下)的演化。f:与 e 对应的电导率-权重变化的分布情况。g:混合训练后在测试集上得到的误差率比对每个卷积器组执行权重迁移后直接得到的误差率低得多。 -
相关阅读:
手把手教你搭建 Ceph+JuiceFS
LaTeX中的数学公式
第29集丨死亡的真相&生活的态度
基于springboot,vue疫情防疫管理系统
Linux系统InfluxDB数据和日志目录迁移教程
几种典型的深度学习算法:(CNN、RNN、GANS、RL)
SAP ABAP Gateway Client 里 OData 测试的 PUT, PATCH, MERGE 请求有什么区别
软件测试工程师成长记:职场人的职业探寻之路
Java8中的函数式接口(你知道几个?)
2023年6月电子学会Python等级考试试卷(五级)答案解析
- 原文地址:https://blog.csdn.net/qq_44173974/article/details/126910252