-
了解下SparkSQL中的笛卡尔积
虽然应该尽量避免使用笛卡尔积,因为要全量匹配,所以运算的效率十分低下,但是有些业务有必须得用,所以在此了解下SparkSQL中的笛卡尔积。
SparkSQL中计算笛卡尔积时有两种Join方式:Cartesian Join 和 Broadcast Nested Loop Join。其中 Broadcast Nested Loop Join 是默认的 Join 机制,它可以用来进行任意条件任意类型的 Join。
Cartesian Join:
该种方式的执行其实就是RDD操作中的cartesian。最终partition的数量是两个RDD partition数量的乘积。它是遍历partition进行计算的,所以会产生巨量多的Task:

SparkSQL对此进行了优化,对右边的数据进行了cache,以便加快计算速度,计算的原理是一致的:

cache就是标红的地方,把数据放到rowArray结构中:

Broadcast Nested Loop Join:
选择BNLJ时,优先通过hints判断到底要广播哪一侧的表。如果没有hints的时候,再通过大小比较,广播小一侧的表:

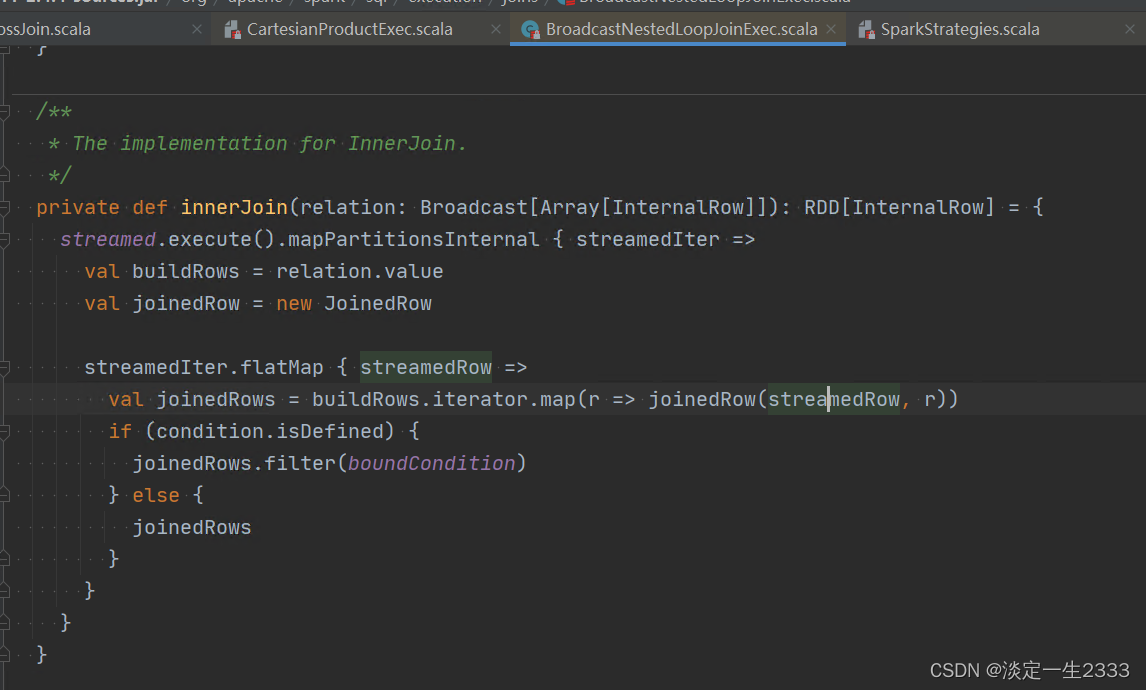
Join的流程很简单,以Inner Join为例,就是逐条匹配,然后按条件过滤。可以理解为Join的流程就是双重的for循环:
for(x in ***){
for(y in ***){
x match y
}
}
参考:
spark2.4 `Inner join`被“优化”成`CartesianProduct`
-
相关阅读:
力扣(LeetCode)88. 合并两个有序数组(C++)
iPhone 如何强制重启
如何利用 Seaborn 实现高级统计图表
【老师见打系列】:我只是写了一个自动回复讨论的脚本~
【Golang | reflect】利用反射实现方法的调用
Facebook的虚拟社交愿景:元宇宙时代的新起点
二叉树层序遍历及判断完全二叉树
地震勘探原理部分问题解答
C语言练习百题之求100之内的素数
【Android】切换系统全局语言设置
- 原文地址:https://blog.csdn.net/zc19921215/article/details/126755395