-
自定义类型:结构体
目录
引言:自定义类型相对的是内置类型


一、结构体的声明
1.结构的基础知识
结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。
2.结构的声明
- struct tag
- {
- member-list;
- }variable-list;
关键字:struct (不能缺,不能改)
tag:结构体标签(根据自己实际需求写)
member-list:成员列表(可以是一个,也可以是多个)
variable-list:变量列表
例如描述一本书:书名+作者+定价+书号
- struct Book
- {
- char book_name[20];//书名
- char author[20];//作者
- int price;//价格
- char id[15];//书号
- };

上图可选项:- struct Book
- {
- char book_name[20];
- char author[20];
- int price;
- char id[15];
- }sb3, sb4;
- //sb3, sb4 也是struct Book类型的结构体变量
- //是全局变量
- int main()
- {
- struct Book sb1;//局部变量
- struct Book sb2;//局部变量
- struct Stu ss1;
- struct Stu ss2;
- return 0;
- }
3.特殊的声明(不完全的声明)
不完全的声明——标签省略不写(省略后,还通过这种类型传递变量,只能在sb1、sb2处跟着传递变量,否则不能传递)
此匿名结构体类型只能用一次,用完之后不能再用
- struct
- {
- char book_name[20];
- char author[20];
- int price;
- char id[15];
- }sb1, sb2;//匿名结构体类型
- int main()
- {
- return 0;
- }
4.结构的自引用
数据结构——数据在内存中存储的结构
线性数据结构:顺序表、链表
树形数据结构:二叉树
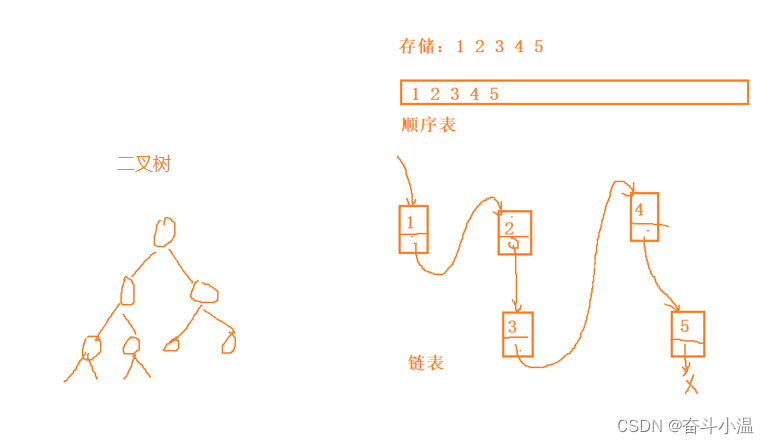
在结构中包含一个类型为该结构本身的成员是否可以呢?
- //代码1
- struct Node
- {
- int data;
- struct Node next;
- };
- //可行否?
- 如果可以,那sizeof(struct Node)是多少?
正确的自引用方式:
- //代码2
- struct Node
- {
- int data;
- struct Node* next;
- };
注意:
- //代码3
- typedef struct
- {
- int data;
- Node* next;
- }Node;
- //这样写代码,可行否?
- //解决方案:
- typedef struct Node
- {
- int data;
- struct Node* next;
- }Node;
5.结构体变量的定义和初始化
- struct Point
- {
- int x;
- int y;
- }p1; //声明类型的同时定义变量p1
- struct Point p2; //定义结构体变量p2
- //初始化:定义变量的同时赋初值。
- struct Point p3 = {x, y};
- struct Stu //类型声明
- {
- char name[15];//名字
- int age; //年龄
- };
- struct Stu s = {"zhangsan", 20};//初始化
- struct Node
- {
- int data;
- struct Point p;
- struct Node* next;
- }n1 = {10, {4,5}, NULL}; //结构体嵌套初始化
- struct Node n2 = {20, {5, 6}, NULL};//结构体嵌套初始化
6.结构体内存对齐(非常重要!!!!!!!!!)
深入讨论一个问题:计算结构体的大小
这也是一个特别热门的考点: 结构体内存对齐
我们先来看一个代码:
- struct S1
- {
- char c1;
- int i;
- char c2;
- };
- struct S2
- {
- char c1;
- char c2;
- int i;
- };
- int main()
- {
- printf("%d\n", sizeof(struct S1));
- printf("%d\n", sizeof(struct S2));
- return 0;
- }
运行结果是什么呢
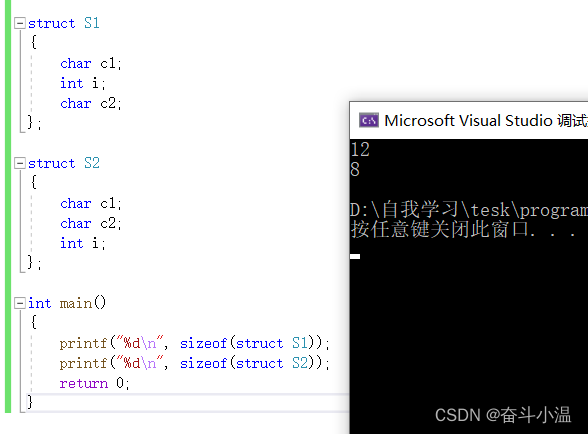
答案是 12 8
首先补充一个知识点:
offsetof——宏:用来计算结构成员相对于起始位置的偏移量
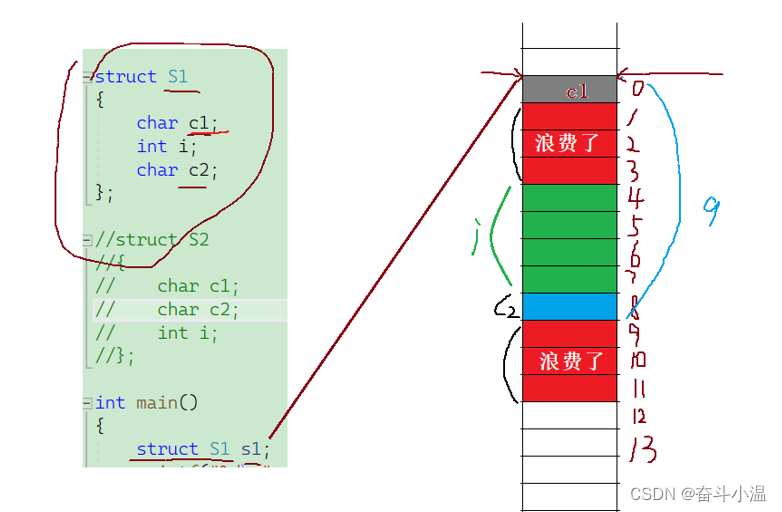
接下来我们看一下S1:
- struct S1
- {
- char c1;
- int i;
- char c2;
- };
- #include
- int main()
- {
- printf("%d\n", offsetof(struct S1, c1));
- printf("%d\n", offsetof(struct S1, c2));
- printf("%d\n", offsetof(struct S1, i));
- return 0;
- }

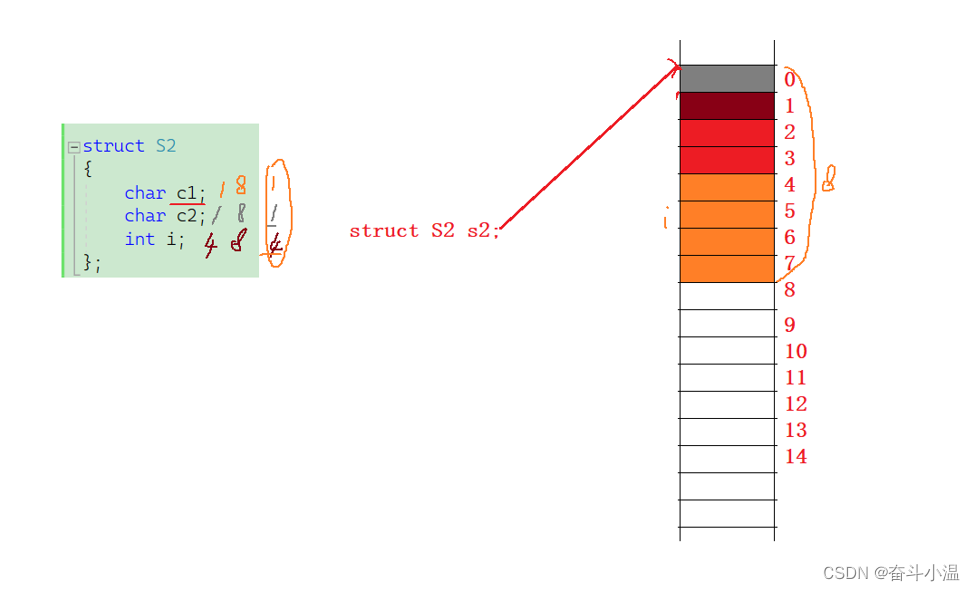
我们再来看一下S2:
- struct S2
- {
- char c1;
- char c2;
- int i;
- };
- #include
- int main()
- {
- printf("%d\n", offsetof(struct S2, c1));
- printf("%d\n", offsetof(struct S2, c2));
- printf("%d\n", offsetof(struct S2, i));
- return 0;
- }


6.1考点(规则)
如何计算?
首先得掌握结构体的对齐规则:
1. 结构体的第一个成员直接对齐到相对于结构体变量起始位置为0的偏移处。
2. 从第二个成员开始,要对齐到某个对齐数的整数倍的偏移处
对齐数 :结构体成员自身大小和默认对齐数的较小值
VS:8Linux环境默认不设置对齐数(对齐数是结构体成员的自身大小)
3. 结构体总大小必须是最大对齐数的整数倍。每个成员变量都有一个对齐数,其中最大的对齐数就是最大对齐数
4. 如果嵌套了结构体的情况嵌套的结构体对齐到自己的最大对齐数的整数倍处,
结构体的整体大小就是所有最大对齐数
(含嵌套结构体的对齐数)的整数倍。


为什么存在内存对齐?
1. 平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常2. 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。
原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。假设:
- struct S
- {
- char c;
- int i;
- };

总体来说:
结构体的内存对齐是拿空间来换取时间的做法那在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到:
让占用空间小的成员尽量集中在一起。
- //例如:
- struct S1
- {
- char c1;
- int i;
- char c2;
- };
- struct S2
- {
- char c1;
- char c2;
- int i;
- };
7.修改默认对齐数
之前我们见过了 #pragma 这个预处理指令,这里我们再次使用,可以改变我们的默认对齐数。
- 设置默认对齐数
- #pragma pack(1)
- struct S1
- {
- char c1;
- int i;
- char c2;
- };//
- //恢复默认对齐数
- #pragma pack()
- int main()
- {
- printf("%d\n", sizeof(struct S1));
- return 0;
- }
结论:
结构在对齐方式不合适的时候,我么可以自己更改默认对齐数。8.结构体传参
- struct S
- {
- int data[1000];
- int num;
- };
- struct S s = {{1,2,3,4}, 1000};
- //结构体传参
- void print1(struct S s)
- {
- printf("%d\n", s.num);
- }
- //结构体地址传参
- void print2(struct S* ps)
- {
- printf("%d\n", ps->num);
- }
- int main()
- {
- print1(s); //传结构体
- print2(&s); //传地址
- return 0;
- }
上面的 print1 和 print2 函数哪个好些?
答案是:首选print2函数。
原因:
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。
如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的下降。结论:
结构体传参的时候,要传结构体的地址。 -
相关阅读:
MFC使用NuGet安装库并使用库 比如tinyxml
SpringBoot - Failed to determine a suitable driver class
[杂记]C++中关于虚函数的一些理解
Redis之string类型的三大编码解读
掌握 Scikit-Learn: Python 中的机器学习库入门
[machine Learning]推荐系统
vue elementui 实现从excel从复制多行多列后粘贴到前端界面el-table
sqlite3入门
华为eNSP配置专题-VRRP的配置
SpringBoot + Nacos + K8s 优雅停机
- 原文地址:https://blog.csdn.net/m0_72161237/article/details/126907118