-
linux进程概念(下)
环境变量
初识:
系统命令可以直接运行,我直接写的程序必须带路径。
基本概念
- 环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数
- 如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。
- 环境变量通常具有某些特殊用途,还有在系统当中通常具有全局特性
常见环境变量
- PATH : 指定命令的搜索路径
只在本次登录下修改有效,下次登录,修改的就无效了 - HOME : 指定用户的主工作目录(即用户登陆到Linux系统中时,默认的目录)
- SHELL : 当前Shell,它的值通常是/bin/bash。
查看环境变量方法
echo $NAME //NAME:你的环境变量名称
和环境变量相关的命令
- echo: 显示某个环境变量值
- export: 设置一个新的环境变量
- env: 显示所有环境变量
- unset: 清除环境变量
- set: 显示本地定义的shell变量和环境变量
通过代码如何获取环境变量
main函数最多可以带三个参数
前两个是命令行参数,第三个是环境变量参数
指针数组类型int main(int agrc,int *argv[],char *env[])- 1
命令行第三个参数#includeint main(int argc, char *argv[], char *env[]) { printf("begin********************\n"); int i = 0; for(; env[i]; i++){ printf("%s\n", env[i]); } printf("end********************\n"); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
通过第三方变量environ获取
#includeint main(int argc, char *argv[]) { extern char **environ; int i = 0; for(; environ[i]; i++){ printf("%s\n", environ[i]); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
libc中定义的全局变量environ指向环境变量表,environ没有包含在任何头文件中,所以在使用时 要用extern声明
getenv#includeint main(int argc, char *argv[], char *env[]) { printf("begin********************\n"); printf("%s\n",getenv("PATH")); printf("end********************\n"); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
环境变量具有全局属性#includeint main(int argc, char *argv[], char *env[]) { printf("begin********************\n"); printf("%s\n",getenv("class_105")); printf("end********************\n"); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
子进程的环境变量是从父进程来的
默认所有的环境变量都会被子进程继承
地址空间
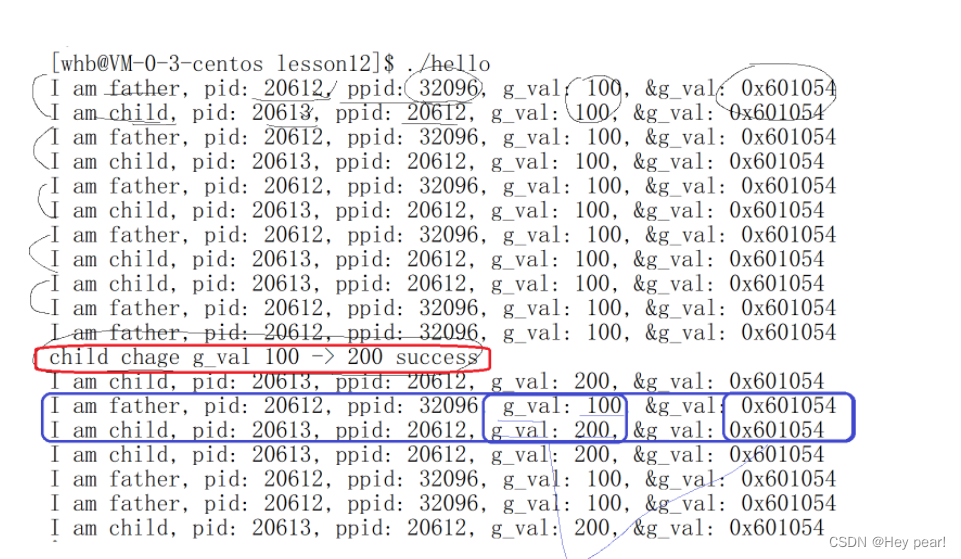
为什么,同一个地址,同时读取的时候出现了不同值?
因为这里的地址并不是物理地址,而是虚拟地址(线性地址)几乎所有的语言,如果有“地址”的概念,这个地址一定不是物理地址而是
虚拟地址函数在执行其实是进程在执行
代码
makefile
hello:hello.c gcc -o $@ $^//统一写法,简便代指后面所有整体文件 .PHONY:clean clean: rm -f hello- 1
- 2
- 3
- 4
- 5
hello.c
#include#include #include int g_unval; int g_val = 100; int main(int argc, char *argv[], char *env[]) { // int a = 10; //字面常量 const char *str = "helloworld"; // 10; // 'a'; printf("code addr: %p\n", main); printf("init global addr: %p\n", &g_val); printf("uninit global addr: %p\n", &g_unval); static int test = 10; char *heap_mem = (char*)malloc(10); char *heap_mem1 = (char*)malloc(10); char *heap_mem2 = (char*)malloc(10); char *heap_mem3 = (char*)malloc(10); printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1) printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1) printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1) printf("heap addr: %p\n", heap_mem3); //heap_mem(0), &heap_mem(1) printf("test stack addr: %p\n", &test); //heap_mem(0), &heap_mem(1) printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1) printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1) printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1) printf("stack addr: %p\n", &heap_mem3); //heap_mem(0), &heap_mem(1) printf("read only string addr: %p\n", str); for(int i = 0 ;i < argc; i++) { printf("argv[%d]: %p\n", i, argv[i]); } for(int i = 0; env[i]; i++) { printf("env[%d]: %p\n", i, env[i]); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
注意:地址都是进程在打印地址,是程序运行之后打印的栈和堆是相对而生:
栈向下增长
打印栈区地址:&heap_mem;
堆向上增长
打印堆区地址:heap_mem;在32位选,一个进程的地址空间的取值范围是
0x0000 0000~0xFFFF FFFF
[0,3GB]用户空间
[3GB,4GB]内核空间先描述再组织
内核中的地址空间本质将来也一定是一种数据结构
将来一定要和特定的进程关联起来在以前,是直接访问物理内存,特别不安全
如今计算机使用虚拟地址:要访问物理内存需要先进行映射
如果我的虚拟地址是一个非法地址,那将会禁止映射区域划分:本质是在一个范围里定义start和endstruct destop{ int start; int end; } struct destop one = {1,50}; struct destop two = {51,100};- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
地址空间是一种内核数据结构,它里面至少要有各个区域的划分
struct addr_room { int code_start; int code_start; int init_start; int init_end; int uninit_start; int uninit_end; int heap_start; int heap_end; int stack_start; int stack_end; .... //其他的属性 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
地址空间和页表(用户级)是每一个进程都私有一份,只要保证每一个进程的页表映射的是物理内存的不同区域就能做到进程之间不会互相干扰,保证进程的独立性
页表也是一种数据结构
关于一个fork()的问题
一个变量怎么可能会同时保存不同的值?
return会被执行两次
return的本质就是对id进行写入,但是发生了写时拷贝,所以父子进程各自其实在物理内存中,有属于自己的变量空间,只不过在用户层用同一个变量(虚拟地址)来标识当我们的程序在编译的时候,形成的可执行程序没有被加载到内存中,请问:我们的程序内部有地址吗?
可执行程序在编译的时候,内部已经有地址了
地址空间不要仅仅理解成为是os内部要遵守的,其实编译器也要遵守。
即编译器编译代码的时候,就已经给我们形成了各个区域(代码区,数据区等等)并且,采用和linux内核中一样的编址方式,给每一个变量、每一行代码都进行了编址
所以程序在编译的时候,每一个字段早已经具有看一个虚拟地址当cup读到指令的时候,指令内部也有地址
注意:cpu内部读取的是虚拟地址
程序内部的地址,依旧用的是编译器编译好的虚拟地址,当程序加载到内存的时候,每行代码,每个变量便具有了一个物理地址,外部的
每一个变量和每一个函数都有地址,是编译器给的
同样也一定会被加载到物理内存
为什么要有地址空间?
凡是非法访问或者映射,os都会识别到并且终止这个进程
有地址空间和页表的存在可以对用户的非法访问进行拦截,有效的保护了物理内存:
地址空间和页表是os创建被维护的,也就意味着凡是想使用用户地址空间和页表进行映射就一定要在OS的监管之下来进行访问。
便利保护物理内存中的所有合法数据,包括各个进程以及内核相关的有效数据
因为有地址空间和页表映射的存在,我们的物理内存中,可以对未来数据进行任意位置的加载
物理内存的分配与进程的管理就可以做到没有关系
内存管理模块 vs 进程管理模块
解耦合(减少模块与模块之间的关联性)
耦合度越低,维护成本越低
所以我们在c、c++语言上,new和malloc空间的时候本质是在哪里申请的呢?
虚拟地址空间
如果我申请了物理空间,但是并不是立马使用,是不是造成了空间的浪费呢?
是的!
延迟分配策略来提高整机的效率
几乎内存的有效使用是100%
本质上,因为有地址空间的存在,所以上层申请空间其实是在地址空间上申请的,物理内存可以一个字节都不给。而当你真正进行对物理地址空间进行访问的时候,才执行内存相关的管理算法,帮你申请内存,构建页表映射关系 (是由操作系统自动完成,用户包括进程完全零感知)
缺页中断
3.
因为在物理内存中理论上可以任意随意位置加载,那么说,在物理内存中的所有数据和代码在内存中是乱序的
但是,因为页表的存在,可以将地址空间上的虚拟地址和物理地址进行映射,是在进程视角中,所有的内存分布都是有序的
地址空间 + 页表 = 内存分布有序化
地址空间是OS给进程画的大饼
进程要访问的物理内存中的数据和代码可能目前并没有在物理内存中,同样的也可以让不同的进程映射到不同的物理内存,于是便很容易做到进程独立性的实现
进程的独立性,可以通过地址空间+页表的方式实现
(不干扰别人且不知道别的存在)
因为有地址空间的存在,每一个进程都认为自己拥有4GB(32)空间,并且各个区域都是有序的,进而可以通过页表映射到不同的区域来实现进程的独立性
每一个进程不会知道其他进程的存在,都以为自己是唯一的进程挂起
加载本质就是创建进程那么是不是必须非得立马把所有程序的代码和数据加载到内存中并创建内核数据结构建立映射关系?no
在最极端的情况下,刚开始只有内核结构被创建出来就行(这就是新建状态)
此时理论上可以实现对程序的分批加载
那可以分批换出吗?可以
而且这个进程短时间不会在被执行了(比如堵塞状态)
一旦进程的代码和数据被换出就是挂起实际上,页表映射的时候,不仅仅映射的是内存,还可以映射磁盘中的位置
-
相关阅读:
SQL Server教程 - T-SQL-游标(CURSOR)
Leetcode(34)——在排序数组中查找元素的第一个和最后一个位置
C++心决之stl中那些你不知道的秘密(string篇)
缓存与数据库双写一致性几种策略分析
【Go语言如何用 interface 实现多态】
C++类与对象 (上)
有向图和无向图的表示方式(邻接矩阵,邻接表)
MySQL的explain详解
C#使用DataTable的Select方法来选择特定的字段
驼峰式与下划线命名规则
- 原文地址:https://blog.csdn.net/Ll_R_lL/article/details/126907290
