-
助力防疫,基于安防摄像头的人脸佩戴口罩检测
最近趁着周末的时间在做一个口罩检测的项目,虽说之前已经做过类似的竞赛了,为什么又要做呢?因为有实际项目落地的需求,还没有真实采集场景的数据进来,我现在能做的就是汇聚网络多源头获取到的数据集来构建一个通用型的模型,后期真实场景数据进来后,以当前通用型模型为基础进行迁移训练会更容易效率也会更高一点。
还是老样子,先看效果图:
先来整体看下:

这里模型选择的依旧是YOLO系列,在我的目标检测专栏里面已经有很多YOLO模型实战的介绍了感兴趣的话可以看下,这里我没有选择最新的v7模型,而是选择使用我之前使用的比较多的mobilenet+yolov4组合的模型。
接下来看下数据集情况,我从网上多个渠道采集标注一共得到2.6W+的数据,如下:



为了能够便捷方便的处理和生成数据集,我这里开发了数据集构建模块,如下:
- train_test_sets = ["train", "test"]
- classes = ["mask","nomask"]
- #ID随机划分
- xmlfilepath = "./dataset/xmls/"
- saveBasePath = "./dataset/"
- train_percent = 0.8
- test_percent = 1 - train_percent
- temp_xml = os.listdir(xmlfilepath)
- total_xml = []
- for xml in temp_xml:
- if xml.endswith(".xml"):
- total_xml.append(xml)
- num = len(total_xml)
- print("num: ", num)
- train_num = int(num * train_percent)
- test_num = num - train_num
- train=random.sample(total_xml,train_num)
- test=list(set(total_xml)-set(train))
- print('TrainNum: ', train_num)
- print('TestNum: ', test_num)
- with open(saveBasePath+'train.txt','w') as f:
- for one_xml in total_xml:
- one_name=one_xml[:-4]
- f.write(one_name.strip()+'\n')
- with open(saveBasePath+'test.txt','w') as f:
- for one_xml in test:
- one_name=one_xml[:-4]
- f.write(one_name.strip()+'\n')
- #训练集-测试集 txt 文件生成
- def convert_annotation(image_id, list_file):
- in_file = open("dataset/xmls/%s.xml" % (image_id), encoding="utf-8")
- tree = ET.parse(in_file)
- root = tree.getroot()
- for obj in root.iter("object"):
- difficult = 0
- if obj.find("difficult") != None:
- difficult = obj.find("difficult").text
- cls = obj.find("name").text
- if cls not in classes or int(difficult) == 1:
- continue
- cls_id = classes.index(cls)
- xmlbox = obj.find("bndbox")
- b = (
- int(xmlbox.find("xmin").text),
- int(xmlbox.find("ymin").text),
- int(xmlbox.find("xmax").text),
- int(xmlbox.find("ymax").text),
- )
- list_file.write(" " + ",".join([str(a) for a in b]) + "," + str(cls_id))
- prefix = ""
- for image_set in train_test_sets:
- image_ids = open("dataset/%s.txt" % (image_set)).read().strip().split()
- list_file = open("%s.txt" % (image_set), "w")
- for image_id in image_ids:
- one_line_prefix = prefix + "dataset/JPEGImages/" + image_id + ".jpg"
- list_file.write(one_line_prefix)
- convert_annotation(image_id, list_file)
- list_file.write("\n")
- list_file.close()
可以很方便地一键生成数据集文件。
终端执行完成后即可在同级目录下自动创建train.txt和test.txt文件。
train.txt如下:

test.txt如下:

启动训练日志输出如下:

可以看到:训练所需的时间很漫长。
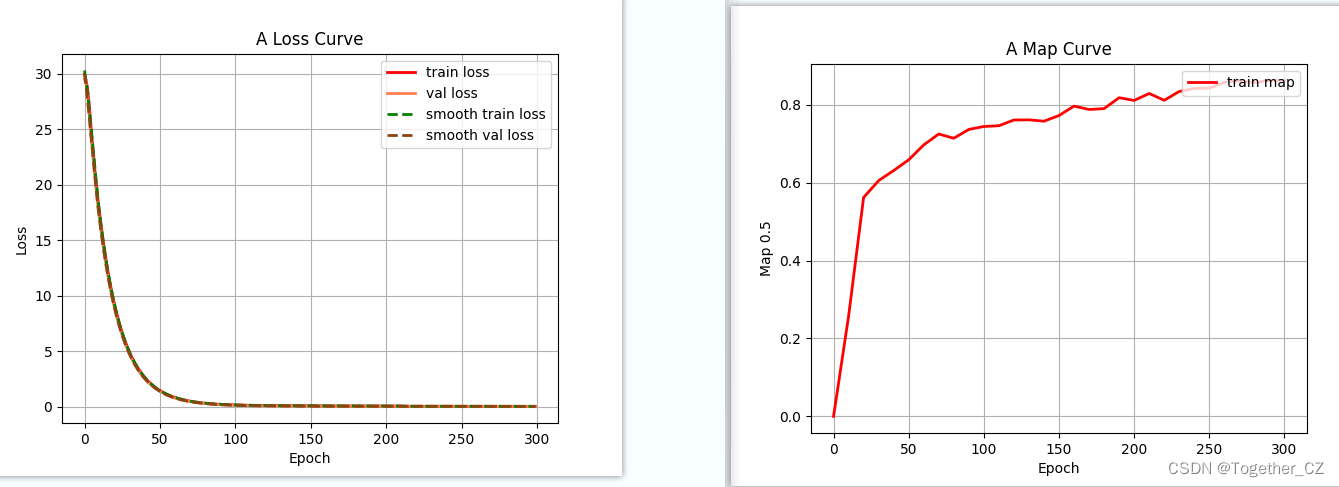
训练结束后会计算map指标,如下所示:



从map指标上面直观来看效果还是不错的。
训练过程可视化如下所示:
为了方便使用模型,这里我开发了界面用于上传图片、调用模型、识别推理和结果呈现,如下:

上传图片:

调用模型检测推理:


-
相关阅读:
TCP网络编程入门
小程序导航栏透明,精准设置小程序自定义标题的高度和定位
并发、并行和多线程关系
Java多商户新零售超市外卖商品系统
Java实操必坑指南二、java泛型、反射、编译优化
ELK 企业级日志分析系统
gitlab-runner 的安装使用(含 .gitlab-ci.yml 的简单使用)
网络安全(黑客)自学
spring的一个properties配置文件,引用另外一个properties配置的变量
c# 值类型和引用类型的区别
- 原文地址:https://blog.csdn.net/Together_CZ/article/details/126907092