-
如何在大数据集群中手工增加一个节点
当运维丢给你一台新装的操作系统,本文将记录手工添加一个节点需要做哪些具体的操作,当前的版本是apache hadoop,未使用CDH版本。
1 系统环境设置
1.1 修改hostname
根据IP设置对应节点的名称,比如增加一个192.168.1.130节点作为数据节点。
临时设置:hostname hadoop-130
永久设置:vim /etc/hostname 中添加hadoop-1301.2 关闭服务器反向解析
此项解决xshell连接虚拟机需要很长时间的问题
修改配置文件vim /etc/ssh/sshd_config- # 关闭UseDNS
- UseDNS no
- # 关闭GSSAPIAuthentication
- GSSAPIAuthentication no
重启sshd
systemctl restart sshd1.3 yum安装的软件
yum -y install vim wget unzip net-tools gcc tree nmap lrzsz dos2unix tcpdump ntpdate1.4 时区设置
先修改localtime
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime如果还不行的话,再修改vim /etc/profile,添加以下,
- TZ='Asia/Shanghai'
- exportTZ
source /etc/profile 激活
1.5 时钟同步设置
1.5.1 提供服务节点设置
vim /etc/ntp.conf
修改以下位置:- # 设置可供同步的服务器地址
- server time.windows.com # 中国国家授时中心
- server 3.cn.pool.ntp.org
- server 1.asia.pool.ntp.org
- server 3.asia.pool.ntp.org
- server hadoop-57 #本机ip作为ntp服务器时间
主节点定时调度
10 22 * * * root (/usr/sbin/ntpdate cn.pool.ntp.org && /sbin/hwclock -w) &> /root/ntpdate.log1.5.2 定时同步节点调度设置
root账号配置时钟同步
- vim /var/spool/cron/root
- 0 */1 * * * /usr/sbin/ntpdate hadoop-57 >>/root/ntpdate.log 2>&1
1.6 关闭防火墙
- systemctl stop firewalld.service #停止firewall
- systemctl disable firewalld.service #禁止firewall开机启动
- firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running)
1.7 关闭交换分区 swap
在/etc/fstab中,将
/dev/mapper/centos-swap swap该行加#注释掉1.8 关闭大透明页
关闭HugePages(Linux 7/8)
- sed -i 's/quiet/quiet transparent_hugepage=never numa=off/' /etc/default/grub
- grub2-mkconfig -o /boot/grub2/grub.cfg
需要重启,重启后通过以下命令查看是否关闭成功。
- cat /sys/kernel/mm/transparent_hugepage/enabled
- cat /proc/cmdline

1.9 关闭selinux
vim /etc/selinux/config
- # 临时关闭
- setenforce 0
- # 永久关闭
- 将SELINUX=enforcing 更改为 SELINUX=disabled
1.10 hadoop组和账户
- sudo groupadd hadoop
- sudo useradd -d /home/hadoop/ -g hadoop hadoop
- # 修改密码
- passwd hadoop
设置hadoop用户密码,并使其密码永久有效
chage -M 99999 hadoop查看普通用户账号有效期的命令
chage -l hadoop
1.11 参数:最大进程数
vim /etc/security/limits.conf
- * soft nofile 65536
- * hard nofile 65536
- * soft nproc 131072
- * hard nproc 131072
针对普通用户,还需要设置:
vim /etc/security/limits.d/20-nproc.conf- * soft nproc 131072
- root soft nproc unlimited
- #查看所有用户创建的进程数,使用命令
- ps h -Led -o user | sort | uniq -c | sort -n
- #查看hadoop用户创建的进程数,使用命令:
- ps -o nlwp,pid,lwp,args -u hadoop | sort -n
1.12 vm参数
vim /etc/sysctl.conf
- vm.swappiness=0
- vm.max_map_count=262144
执行
sysctl -p命令生效1.13 添加hosts
拷贝/etc/hosts文件,分发到各个节点
1.14 ssh免密登录设置
第一步:先在每个节点生成公钥,然后将公钥追加到主服务器上。
- #先生成秘钥
- cd /home/hadoop/
- ssh-keygen -t rsa
- # 拷贝公钥
- cd /home/hadoop/.ssh
- cp id_rsa.pub authorized_keys
- # 将公钥追加到目标主服务器上
- ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop-50
第二步,从主服务器上得到所有的追加进来的公钥的文件/home/hadoop/.ssh/authorized_keys。
将该文件分发拷贝到所有其他节点上。- # 先修改权限
- cd /home/hadoop/.ssh
- chmod 600 authorized_keys
- # 然后复制分发
- scp /home/hadoop/.ssh/authorized_keys hadoop@hadoop-01
- ...
- ...
- ...
- scp /home/hadoop/.ssh/authorized_keys hadoop@hadoop-xxx
完成后,需要测试ssh是否已正常免密登录过去。
1.15 挂载磁盘
(1)查看磁盘个数 lsblk
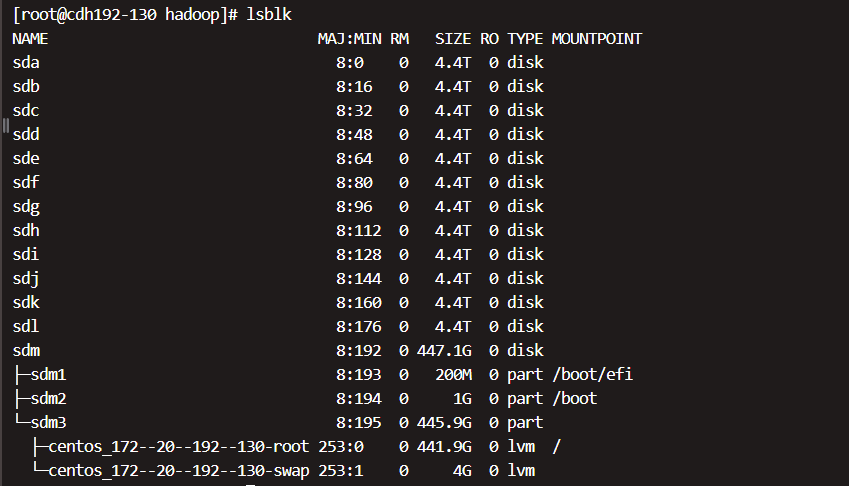
(2)根据磁盘个数创建对应的数据盘目录,如上图中12个磁盘作为数据盘,则创建12个磁盘目录。
- #下面是在一行执行的
- mkdir -p /dfs/data1/ /dfs/data2/ /dfs/data3/ /dfs/data4/ /dfs/data5/ /dfs/data6/ /dfs/data7/ /dfs/data8/ /dfs/data9/ /dfs/data10/ /dfs/data11/ /dfs/data12/
- # 或者是一个个创建
- mkdir -p /dfs/data1/
- mkdir -p /dfs/data2/
- mkdir -p /dfs/data3/
- mkdir -p /dfs/data4/
- mkdir -p /dfs/data5/
- mkdir -p /dfs/data6/
- mkdir -p /dfs/data7/
- mkdir -p /dfs/data8/
- mkdir -p /dfs/data9/
- mkdir -p /dfs/data10/
- mkdir -p /dfs/data11/
- mkdir -p /dfs/data12/
(3)格式化磁盘
- mkfs.xfs -f /dev/sda
- mkfs.xfs -f /dev/sdb
- mkfs.xfs -f /dev/sdc
- mkfs.xfs -f /dev/sdd
- mkfs.xfs -f /dev/sde
- mkfs.xfs -f /dev/sdf
- mkfs.xfs -f /dev/sdg
- mkfs.xfs -f /dev/sdh
- mkfs.xfs -f /dev/sdi
- mkfs.xfs -f /dev/sdj
- mkfs.xfs -f /dev/sdk
- mkfs.xfs -f /dev/sdl
(4)挂载磁盘到目录
这种挂载是临时挂载目录,重启后还会消失,还需要配置启动自动挂载,见(5)- mount /dev/sda /dfs/data1/
- mount /dev/sdb /dfs/data2/
- mount /dev/sdc /dfs/data3/
- mount /dev/sdd /dfs/data4/
- mount /dev/sde /dfs/data5/
- mount /dev/sdf /dfs/data6/
- mount /dev/sdg /dfs/data7/
- mount /dev/sdh /dfs/data8/
- mount /dev/sdi /dfs/data9/
- mount /dev/sdj /dfs/data10/
- mount /dev/sdk /dfs/data11/
- mount /dev/sdl /dfs/data12/
挂载好后如下:

(5)配置启动自动挂载
vim /etc/fstab ,新增以下挂载项- /dev/sda /dfs/data1/ xfs defaults 0 0
- /dev/sdb /dfs/data2/ xfs defaults 0 0
- /dev/sdc /dfs/data3/ xfs defaults 0 0
- /dev/sdd /dfs/data4/ xfs defaults 0 0
- /dev/sde /dfs/data5/ xfs defaults 0 0
- /dev/sdf /dfs/data6/ xfs defaults 0 0
- /dev/sdg /dfs/data7/ xfs defaults 0 0
- /dev/sdh /dfs/data8/ xfs defaults 0 0
- /dev/sdi /dfs/data9/ xfs defaults 0 0
- /dev/sdj /dfs/data10/ xfs defaults 0 0
- /dev/sdk /dfs/data11/ xfs defaults 0 0
- /dev/sdl /dfs/data12/ xfs defaults 0 0
(6)重启系统
注意:1-5步骤做完后,一定要重启系统。防止哪里操作有误,重启起不来。
重启后,再看lsblk如下就ok了。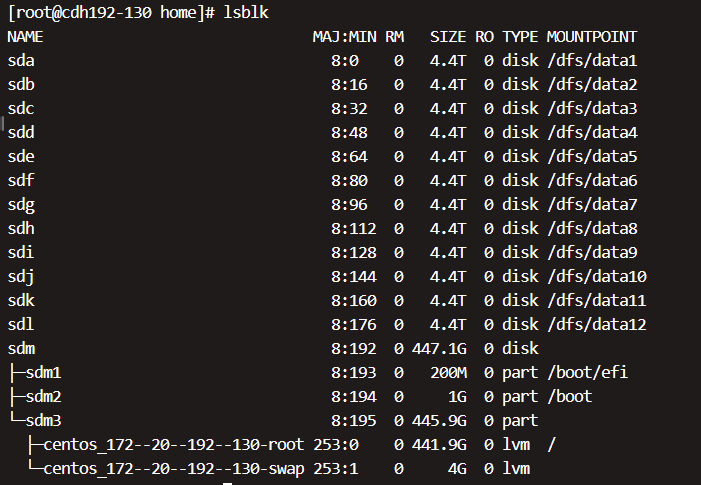
2. 大数据环境设置
2.1 目录操作
修改/dfs目录所有者和组为hadoop
- cd /dfs
- chown -R hadoop:hadoop *
创建目录
mkdir -p /home/hadoop/data/hadoop/storage /home/hadoop/data/journaldata /home/hadoop/data/hadoop/pids2.2 配置环境变量
vim /etc/profile 在最后增加以下内容
- export JAVA_HOME=/home/hadoop/bigdata/jdk
- export HADOOP_HOME=/home/hadoop/bigdata/hadoop
- export HADOOP_USER_NAME=hadoop
- export HIVE_HOME=/home/hadoop/bigdata/hive
- export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$PATH
- export SCALA_HOME=/home/hadoop/bigdata/scala
- export PATH=$PATH:$SCALA_HOME/bin
- export SPARK_HOME=/home/hadoop/bigdata/spark
- export PATH=$PATH:$SPARK_HOME/bin
- export ZK_HOME=/home/hadoop/bigdata/zk
- export PATH=$PATH:$ZK_HOME/bin
- export HBASE_HOME=/home/hadoop/bigdata/hbase
- export PATH=$PATH:$HBASE_HOME/bin
- export FLINK_HOME=/home/hadoop/bigdata/flink
- export PATH=$PATH:$FLINK_HOME/bin
- export LD_LIBRARY_PATH=/home/hadoop/bigdata/hadoop/lib/native:$LD_LIBRARY_PATH
- #210918 支持flink
- export HADOOP_CLASSPATH=`hadoop classpath`
- export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
2.3 拷贝软件
本次是新增几个节点,所以直接从已有的节点上拷贝已经安装的软件。
用hadoop账号从其他节点拷贝软件。scp -r /home/hadoop/bigdata hadoop@hadoop-130:/home/hadoop/2.4 修改hadoop配置
2.4.1 修改yarn-site.xml
查看配置,不同的配置需要修改为对应的Yarn配置文件
- # 查看内存
- free -g
- # 查看cpu核数
- cat /proc/cpuinfo| grep 'processor'|wc -l
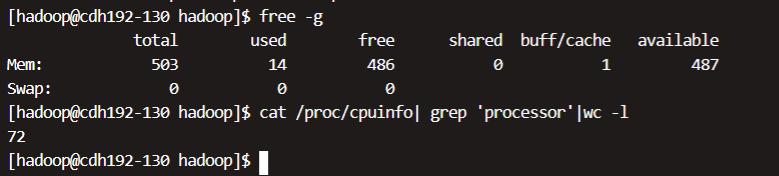
内存大约为512G,CPU为72个核数。
-
yarn.nodemanager.resource.memory-mb
单节点最大可用内存,预留16G作为系统使用,496G作为Yarn资源调度(496G * 1024 = 507904MB) -
yarn.nodemanager.resource.cpu-vcores
单节点最大可用核数,预留2核,提供70个核作为Yarn资源调度使用。
因此,如果提供的机器配置不一样,需要根据具体的机器配置修改这里的参数。
- <property>
- <name>yarn.nodemanager.resource.memory-mbname>
- <value>507904value>
- property>
- <property>
- <description>Number of vcores that can be allocated
- for containers. This is used by the RM scheduler when allocating
- resources for containers. This is not used to limit the number of
- physical cores used by YARN containers.description>
- <name>yarn.nodemanager.resource.cpu-vcoresname>
- <value>70value>
- property>
2.4.2 修改hdfs-site.xml
根据本地数据磁盘个数不同去修改
- <property>
- <name>dfs.datanode.data.dirname>
- <value>/dfs/data1,/dfs/data2,/dfs/data3,/dfs/data4,/dfs/data5,/dfs/data6,/dfs/data7,/dfs/data8,/dfs/data9,/dfs/data10,/dfs/data11,/dfs/data12value>
- property>
2.4.3 修改works文件
在/home/hadoop/bigdata/hadoop/etc/hadoop/workers 文件中添加新的节点hostname,比如本次新添加节点hadoop-130, 在workers中追加hadoop-130
然后将该文件拷贝分发到所有的节点。3. 启动服务
- cd /home/hadoop/bigdata/hadoop/sbin
- # 启动datanode
- ./hadoop-daemon.sh start datanode
- # 启动nodemanager
- ./yarn-daemon.sh start nodemanager
-
相关阅读:
基于javaweb的电力设备监测管理系统(servlet+jsp)
java计算机毕业设计ssm社会救援力量信息管理统计系统6q3cn(附源码、数据库)
Java语言的过滤数据流
Cocos Creator3.8 项目实战(十)使用 protobuf详细教程
OpenLayer系列——【一】初识OpenLayer与OpenLayer视图操作
【RV1106/RV1103】RV1103增加RTL8723BS
C. LIS or Reverse LIS?
Unity3D AStar地图编辑与寻路测试详解
【AI视野·今日CV 计算机视觉论文速览 第279期】Tue, 31 Oct 2023
C++PrimerPlus 第七章 函数-C++的编程模块-7.1 复习函数的基本知识
- 原文地址:https://blog.csdn.net/wang6733284/article/details/126906276