-
[Pandas技巧] 多行合并成一行

美图欣赏2022/09/16 在最近的需求开发中,有如下需求需要进行修改,数据源demo如下所示

根据字段'material'进行分组,对字段'site'进行合并,内容之间用逗号(,)分隔,再进行去重处理;对字段'LT'取最大值,最终呈现结果如下所示

具体实现代码如下所示
- import pandas as pd
- df = pd.DataFrame([['FJZ','A123',123],
- ['FOC','A123',456],
- ['FJZ','B456',112],
- ['FJZ','B456',245],
- ['FJZ','B456',110],
- ['FOC','C789',202],
- ['FOC','C789',205]
- ],columns=['site','material','LT'])
- # 筛选字段'material'并进行去重处理
- merge_data = df[['material']]
- merge_data = merge_data.drop_duplicates(subset = ['material'])
- # 对'site'和'LT'字段进行处理
- df = df.groupby(['material']).agg({'site':[','.join],'LT':max})
- # 更换字段栏位名称
- new_column = ['site','LT']
- df.columns = new_column
- # 对字段'site'中的值进行去重处理
- def data_deduplication(row):
- data_list = row['site'].split(',')
- res = ','.join(set(data_list))
- return res
- df['site'] = df.apply(lambda row:data_deduplication(row), axis=1)
- merge_data = pd.merge(merge_data, df, how='left', on=['material'])
- # 调整字段顺序
- order = ['site','material','LT']
- merge_data = merge_data[order]
df(未进行合并处理)

merge_data

将上述核心关键代码进行拆分讲解
- import pandas as pd
- df = pd.DataFrame([['FJZ','A123',123],
- ['FOC','A123',456],
- ['FJZ','B456',112],
- ['FJZ','B456',245],
- ['FJZ','B456',110],
- ['FOC','C789',202],
- ['FOC','C789',205]
- ],columns=['site','material','LT'])
- # 对'site'和'LT'字段进行处理
- df = df.groupby(['material']).agg({'site':[','.join],'LT':max})
该段代码可将多行数据合并成一行数据

从上图可以看出df中的字段名发生了变化,我们需要对此进行更换字段名操作,便于后续的理解以及数据处理
- # 更换字段栏位名称
- new_column = ['site','LT']
- df.columns = new_column

另一种解决方案(更优)
- import pandas as pd
- df = pd.DataFrame([['FJZ','A123',123],
- ['FOC','A123',456],
- ['FJZ','B456',112],
- ['FJZ','B456',245],
- ['FJZ','B456',110],
- ['FOC','C789',202],
- ['FOC','C789',205]
- ],columns=['site','material','LT'])
- df_copy = df.copy()
- # 筛选字段'material'并进行去重处理
- merge_data = df_copy[['material']]
- merge_data = merge_data.drop_duplicates(subset = ['material'])
- # 定义拼接函数,并对字段进行去重
- def concat_func(row):
- return pd.Series({
- 'site':','.join(map(str,row['site'].unique()))
- })
- # 对'site'和'LT'字段进行处理
- df_copy = df_copy.groupby(df_copy['material']).apply(lambda row:concat_func(row))
- merge_data = pd.merge(merge_data, df_copy, how='left', on=['material'])
- df_copy = df.copy()
- df_copy = df_copy.groupby(df['material']).agg({'LT':max})
- merge_data = pd.merge(merge_data, df_copy, how='left', on=['material'])
- # 调整字段顺序
- order = ['site','material','LT']
- merge_data = merge_data[order]
扩展补充多行合并成一行操作案例
案例1
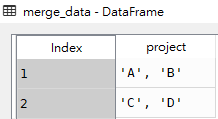
问题:根据字段'id'进行分组,对字段'project'进行合并,内容之间用逗号(,)分隔
- import pandas as pd
- data = pd.DataFrame({'id':[1,1,2,2],'project':['A','B','C','D']})
- #合并数据
- merge_data = data.groupby(['id'])['project'].apply(list).to_frame()
- merge_data['project'] = merge_data['project'].apply(lambda x:str(x).replace('[','').replace(']',''))
合并前

合并后
案例2
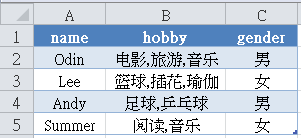
问题:把多行数据按“姓名”合并,并保留所有信息
数据源

经过合并后的数据
具体代码如下所示
- import pandas as pd
- df = pd.DataFrame([['Odin','电影','男'],
- ['Odin','旅游','男'],
- ['Odin','音乐','男'],
- ['Lee','篮球','女'],
- ['Lee','插花','女'],
- ['Lee','瑜伽','女'],
- ['Andy','足球','男'],
- ['Andy','乒乓球','男'],
- ['Summer','阅读','女'],
- ['Summer','音乐','女'],
- ],columns=['name','hobby','gender'])
- # 定义拼接函数,并对字段进行去重
- def concat_func(row):
- return pd.Series({
- 'hobby':','.join(row['hobby'].unique()),
- 'gender':','.join(row['gender'].unique())
- })
- result = df.groupby(df['name']).apply(lambda row:concat_func(row)).reset_index()
案例3
问题: 把多行数据按“material”合并,并保留所有信息,其中'site'字段进行去重处理,'usages'字段不进行去重处理
数据源

经过合并后的数据

- import pandas as pd
- df = pd.DataFrame([['FJZ','A123',1],
- ['FOC','A123',1],
- ['FJZ','B456',1],
- ['FJZ','B456',2],
- ['FJZ','B456',2],
- ['FOC','C789',3],
- ['FOC','C789',5]
- ],columns=['site','material','usages'])
- order = ['site','material','usages']
- data_new = df[order]
- # 定义拼接函数,并对字段进行去重
- def concat_func(row):
- return pd.Series({
- 'site':','.join(map(str,row['site'].unique())),
- 'usages':','.join(map(str,row['usages']))
- })
- data_new = data_new.groupby(data_new['material']).apply(lambda row:concat_func(row)).reset_index()
- # 调整字段栏位顺序
- order = ['site','material','usages']
- data_new = data_new[order]
-
相关阅读:
【计算机网络笔记】TCP的拥塞控制机制
智能制造数字工厂 规划建设方案
cookie、session、Token究竟区别在哪?如何进行身份认证,保持用户登录状态?
监督学习和非监督学习, 半监督学习和增强学习
leetcode日记(32)字符串相乘
【服务器】ASUS ESC4000-E11 安装系统
第7章-查找
【C语言】指针的定义、概念和运用
Jmeter v5.6.x 使用说明书(简要版)
云计算考试题
- 原文地址:https://blog.csdn.net/Hudas/article/details/126891082
