-
2022高教社杯数学建模国赛C题思路代码实现
1.比赛报名与思路解析(持续更新750967193)
2.比赛时间:2022年9月15日18点到2022年9月18日20点
如下为C题思路的配套代码:
首先导入表单:
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- import seaborn as sns
- plt.rcParams['font.sans-serif']='SimHei'
- plt.rcParams['axes.unicode_minus']=False
- df_表单1 = pd.read_excel('附件.xlsx', sheet_name='表单1')
- df_表单2 = pd.read_excel('附件.xlsx', sheet_name='表单2')
- df_表单3 = pd.read_excel('附件.xlsx', sheet_name='表单3')
画出各个属性占比图
- fig=plt.figure(figsize=(10,10))
- i=1
- for column in df_表单1.columns[1:]:
- data ={elem:np.sum(df_表单1[column]==elem) for elem in df_表单1[column].unique()}
- ax=fig.add_subplot(2,2,i)
- i+=1
- ax.pie(data.values(), labels=data.keys(), autopct='%1.2lf%%', pctdistance=0.5)
- ax.set_title(column+'占比图')
- plt.savefig('各属性数量占比图.png')
- plt.show()
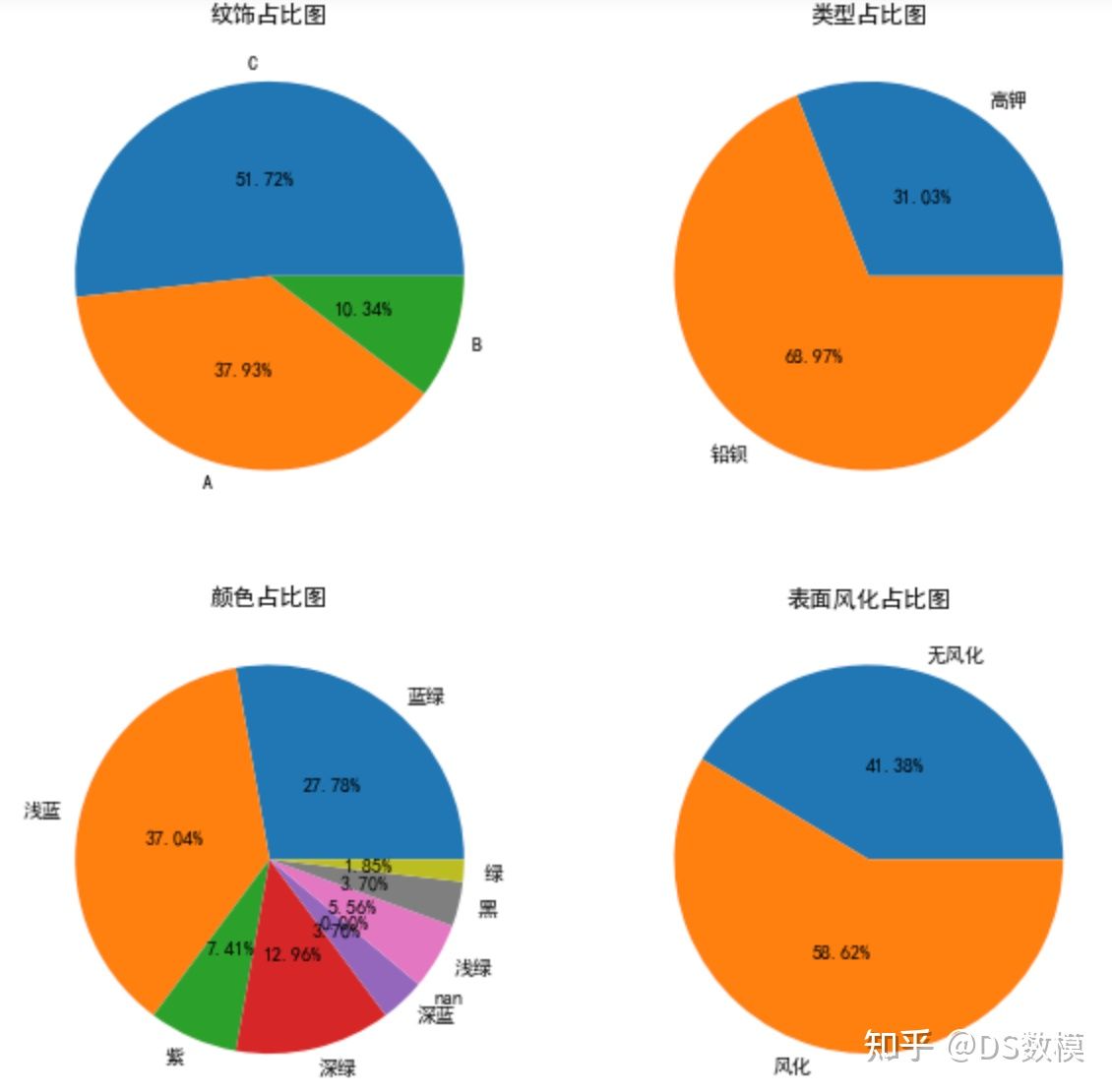
可以对数据采用如下方式处理:
- 空白处表示未检测到该成分,即该成分的含量为0,所以对于表单2中所用的控制用0进行填充;
- 对于‘文物采样点’进行分开处理,分开为‘文物编号’,采样点;
- 将成分之和不在区间[85,105]范围内的删除;
- 各成分含量之和应为100%,但因检测手段等原因加和并非100%,所以对各成分进行归一化处理,使其成分含量和为100%
- df_表单2 = pd.read_excel('附件.xlsx', sheet_name='表单2')
- df_表单2['采样点']=df_表单2['文物采样点'].apply(lambda x:x[2:])
- df_表单2['文物编号']=df_表单2['文物采样点'].apply(lambda x:x[:2])
- df_表单2=df_表单2.fillna(0)
- print(df_表单2.shape)
- df_表单2['总含量']=df_表单2[df_表单2.columns[1:15]].sum(axis=1)
- index = df_表单2[df_表单2['总含量']<85].index
- df_表单2=df_表单2.drop(index=index)
- print(df_表单2.shape)
- index = df_表单2[df_表单2['总含量']>105].index
- df_表单2=df_表单2.drop(index=index)
- print(df_表单2.shape)
- for column in df_表单2.columns[1:15]:
- df_表单2[column]=df_表单2[column]/df_表单2['总含量']*100
- df_表单2.head()
然后合并1、2表单:
- df_表单1['文物编号']=df_表单1['文物编号'].astype('str')
- df_表单1['文物编号']=df_表单1['文物编号'].apply(lambda x:'0'*(2-len(x))+x)
- df_表单1.index=df_表单1['文物编号']
- columns = ['纹饰', '类型', '颜色', '表面风化']
- df_表单2[columns]=''
- for i in df_表单2.index:
- index = df_表单2['文物编号'][i]
- for column in columns:
- df_表单2.loc[i,column]=df_表单1[column][index]
- df_表单2['颜色'].unique()
- dic = {'风化':1,'无风化':0,
- 'A':1,'C':0, # 这里未对B进行转换,不过在apriori的地方使用的是汉字不影响,后续也没有使用
- '高钾':1,'铅钡':0,
- '蓝绿':0, '浅蓝':1, '紫':2, '深绿':3, '深蓝':4, '浅绿':5, '黑':6, '绿':7}
- df_表单2['是否风化']=df_表单2['表面风化'].apply(lambda x:dic.get(x))
- df_表单2['类型是否高钾']=df_表单2['类型'].apply(lambda x:dic.get(x))
- df_表单2['纹饰A']=df_表单2['纹饰'].apply(lambda x:dic.get(x))
- df_表单2['颜色编号']=df_表单2['颜色'].apply(lambda x:dic.get(x))
- columns = ['文物编号','采样点','是否风化','类型是否高钾','纹饰A','颜色编号']
- columns.extend(df_表单2.columns[1:15])
- df = df_表单2[columns]
- df.to_excel('表单1-2合并.xlsx')
- df
得到完整的合并表单:

各成分占比:
- plt.figure(figsize=(10,10))
- data = df[df.columns[5:]].mean()
- print(data[data<=1].index)
- value = list(data[data>1].values)+[sum(data[data<=1].values)]
- labels = list(data[data>1].index)+['其他']
- plt.pie(value, labels=labels, autopct='%1.2lf%%')
- plt.savefig('各成分平均占比图.png')
- plt.show()
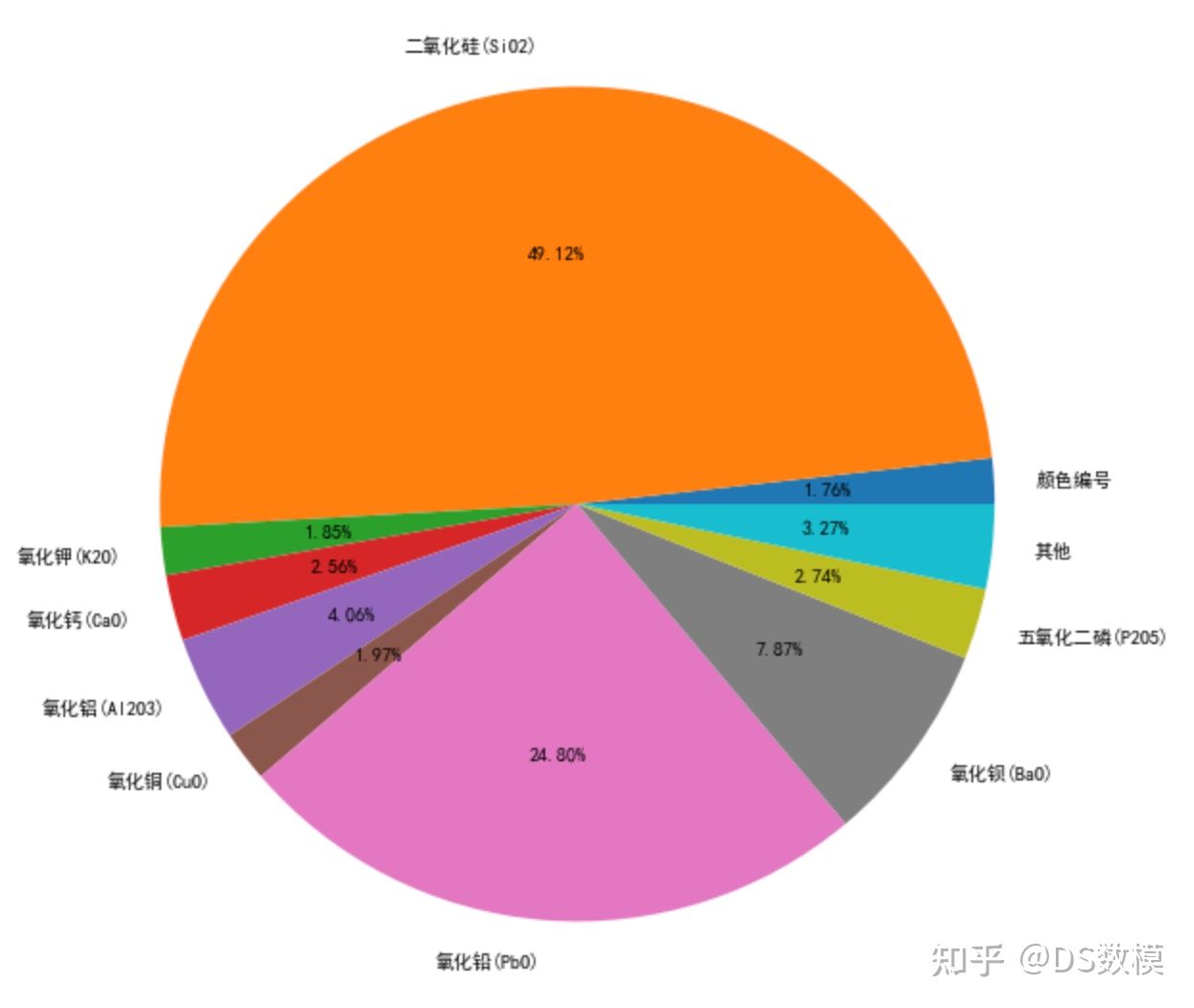
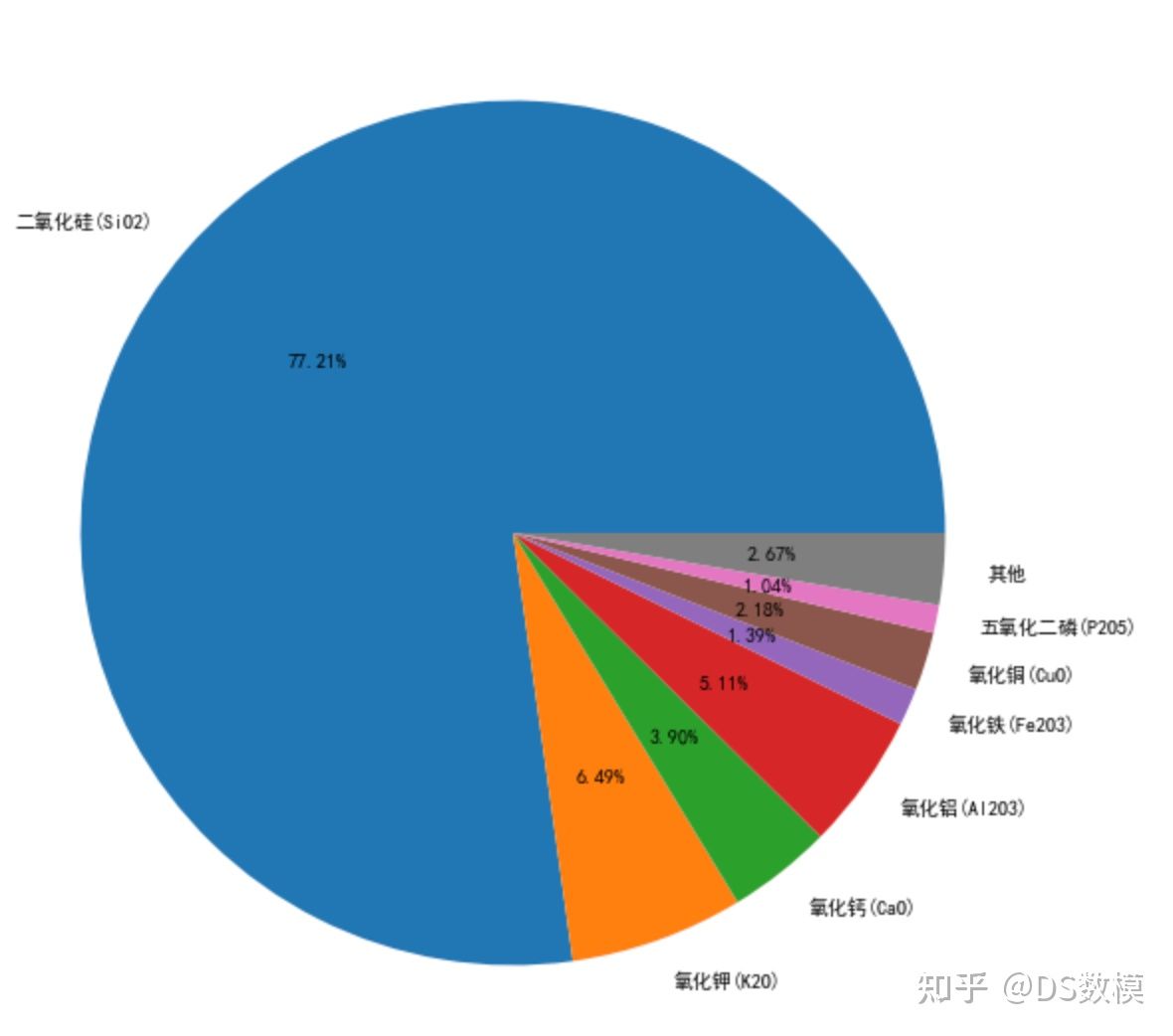
- df1 = df[df['类型是否高钾']==1]
- plt.figure(figsize=(10,10))
- data = df1[df1.columns[5:]].mean()
- print(data[data<=1].index)
- value = list(data[data>1].values)+[sum(data[data<=1].values)]
- labels = list(data[data>1].index)+['其他']
- plt.pie(value, labels=labels, autopct='%1.2lf%%')
- plt.savefig('类型为高钾的成分占比图.png')
- plt.show()
此图为:类型为高钾的成分占比图
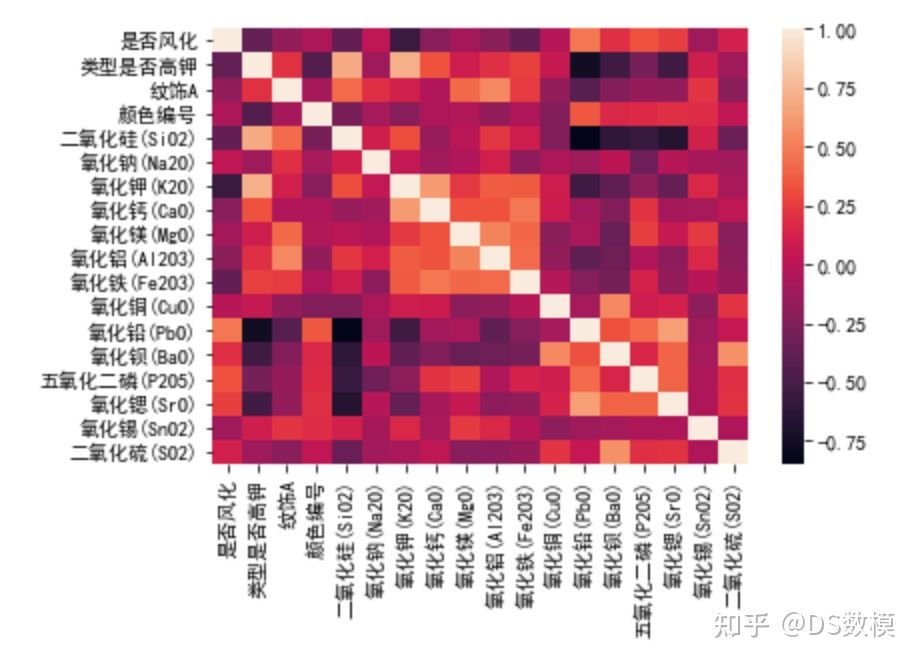
画出热力图:
- sns.heatmap(df[df.columns[1:5]].corr())
- plt.savefig('风化,纹饰,颜色,类型相关性热力图.png')
- plt.show()

所有属性热力图
以上仅为部分数据预处理内容,第二问小部分内容摘选:
- df['亚类']=''
- 高钾亚类 = ['高钾亚类'+str(i) for i in 高钾kmeans[1]]
- 铅钡亚类 = ['铅钡亚类'+str(i) for i in 铅钡kmeans[1]]
- df.loc[高钾_df.index,'亚类']=高钾亚类
- df.loc[铅钡_df.index,'亚类']=铅钡亚类
- df.to_excel('所有文物分别按亚类分类表.xlsx')
以上仅为部分数据预处理内容和摘选的第二问的小部分内容
-
相关阅读:
mac使用python递归删除文件夹下所有的.DS_Store文件
Kotlin高仿微信-第9篇-单聊-文本
tcpdump 抓包快速上手
背包问题学习笔记-混合背包问题
初入职场必备丨二进制面试问题汇总
算法日常训练12.5
C++ 的设计模式之 工厂方法加单例
9月24日,每日信息差
前端培训丁鹿学堂:node入门之url模块和querystring模块
Windows 控制台程序的 binary 输出
- 原文地址:https://blog.csdn.net/weixin_43345535/article/details/126900089
