-
强化学习学习笔记
献上一篇非常详细的DQN教程(英文版的讲得太好了!)
https://download.csdn.net/download/mossfan/86854634
入门源码(pytorch实现DQN玩gym,根据代码可以很快了解框架运行流程)
https://download.csdn.net/download/mossfan/86902062强化学习是什么
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
强化学习是agent在环境的互动当中为了达成一个目标而进行的学习过程。
强化学习组成元素
基本元素:
agent:‘玩家’
environment
goal主要元素:
state
action
reward动作空间(Action Space):A,可以采取的所有合法动作的集合,所有合法的落子。
状态空间(State Space):S;所有的状态的集合称为状态空间,所有的棋盘布局。核心元素
policy:策略
value:state value、state-action value关系如下

两个特点,一个核心问题
特点
trial and error:试错
delayed reward:延迟奖励问题
exploration vs exploitationexploitation:利用就是根据已有的经验去取得最大回报。比如,附近有十家餐馆,你已经去过里边的七家了,你知道这七家中红烧排骨最好吃,所以你会根据已有经验去吃红烧排骨,也不会去尝试另外的三家餐馆。这样是局部最优解。
exploration :探索是指做你以前从来没有做过的事情,以期望获得更高的回报。 这时候你就要去尝试剩下的三家餐馆,看看有没有更好吃的菜,去寻找全局最优解。
围棋
agent:我
环境:棋局
goal:赢state:棋盘上棋子的分布情况,afterstate(本次action后的状态)
action:落子
reward:落子后的反应policy:使赢棋概率最大的行动
value:赢棋的概率,赢棋为1,输为0多臂老虎机
对比两个老虎机的奖励哪个更好特点:只有一个状态,没有延迟奖励
agent:玩家,我
environment:老虎机
goal:获得奖励state:只有一个状态
action:摇一次
reward:服从一定概率分布的随机变量学习方法
平均误差学习法
Qn+1=Qn+1/n(Rn-Qn)Q:奖励估计值
Qn+1:New Estimate
Qn:Old Estimate
Rn:Real Estimate(Reward)1/n:learning rate
Rn-Qn:Error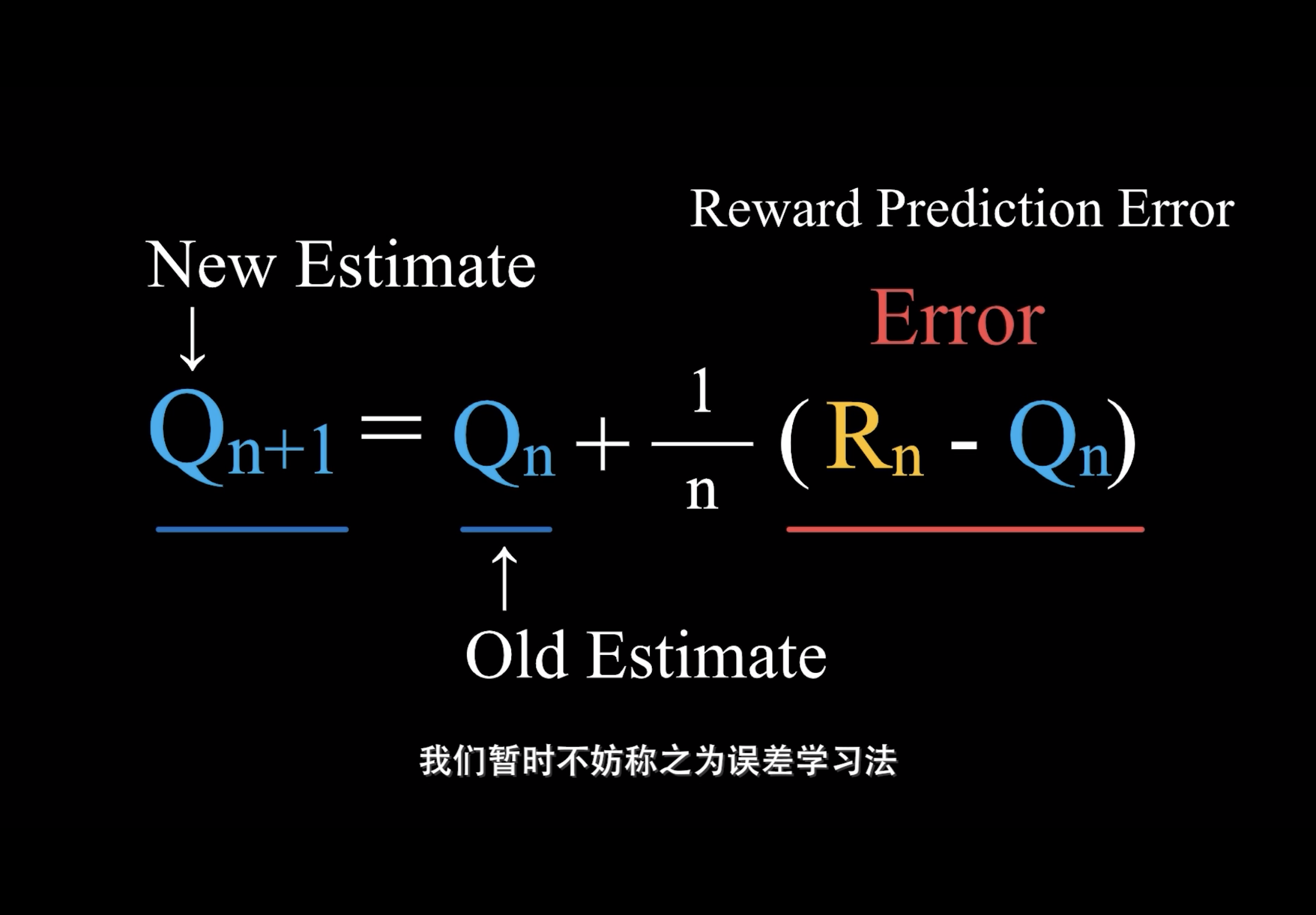
加权平均误差

贪婪策略和e-greedy贪婪策略
贪婪策略:
是一个确定性的策略,每一次都选择回报价值最大的那个策略。e-greedy贪婪策略:
是一个不确定性的策略,平衡了利用和探索,其中选取动作值函数最大的部分为利用,仍有概率去寻找全局最优解为探索部分。令e=0.1,也就是有1-0.1=0.9的概率是利用,有0.1的概率是探索。也就是选择当前最大回报的概率是0.9,去寻找全局最优解进行探索的概率是0.1.【强化学习】一小时完全入门 哔哩哔哩up主:PenicilinLP
https://blog.csdn.net/qq_39435411/article/details/113731168价值函数(important)
价值函数,是一种连接最优准则和策略的方法。大多数针对MDP的学习算法通过学习价值函数来计算出最优策略。
一个价值函数表示在一个特定的状态(或是在该状态采取的某一动作的条件)下对一个agent好的程度的的估计。好的程度的概念由最优准则来表达。价值函数被特定的策略所定义。
行为价值


Qπ的值依赖于St和at
状态价值

https://blog.csdn.net/weixin_33204399/article/details/119118179
https://blog.csdn.net/qq_40694497/article/details/122735667MDP(马尔科夫决策过程)
Markov 的定义
首先定义一下什么是Markov:下一个状态的产生只和当前的状态有关,即:
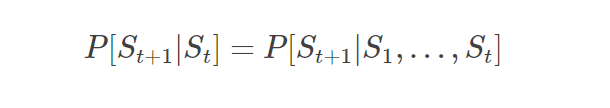
本来直观上讲,下一个状态的产生跟所有历史状态是有关的,也就是等式右边所示。但是Markov的定义则是忽略掉历史信息,只保留了当前状态的信息来预测下一个状态,这就叫Markov。马尔科夫决策要求:
- 能够检测到理想的状态。
- 可以多次尝试(死了重来、输了重来等)。
- 系统的下个状态只与当前状态信息有关,而与更早之前的状态无关。在决策过程中还和当前采取的动作有关。
MDP定义

马尔科夫决策过程可以用一个五元组(S, A, P(:😅, R(:😅, γ)来描述,其中:
- S是一组有限的状态集(state);
- A是一组有限的动作集(action);
- Pa(s,s’)=Pr(St+1=s’|St=s,at=a)表示在时间 t 状态 s 采取动作 a 可以在时间 t+1 转换到状态 s’的概率;
- Ra(s,s’)表示通过动作 a ,状态 s 转换到 s’ 所带来的及时收益或回报(reword);
- γ是折扣因子,表示未来收益和当前收益之前的差别,意味着当下的 reward 比未来反馈的 reward 更重要。从状态s出发,经过一系列的状态转移最终达到终点,得到了一条路径,每次状态转移都会有一个R,所以最终G就表示从s开始一直到终点的所有R之和。因为离s越远的地方一般影响较小,所以加了一个折扣因子。
马尔可夫决策过程并不要求 S 或者 A 是有限的,但基础的算法中假设它们是有限的。


https://blog.csdn.net/yingwei3958/article/details/79561295
https://blog.csdn.net/liweibin1994/article/details/79079884
https://blog.csdn.net/weixin_33204399/article/details/119118179Q-learning
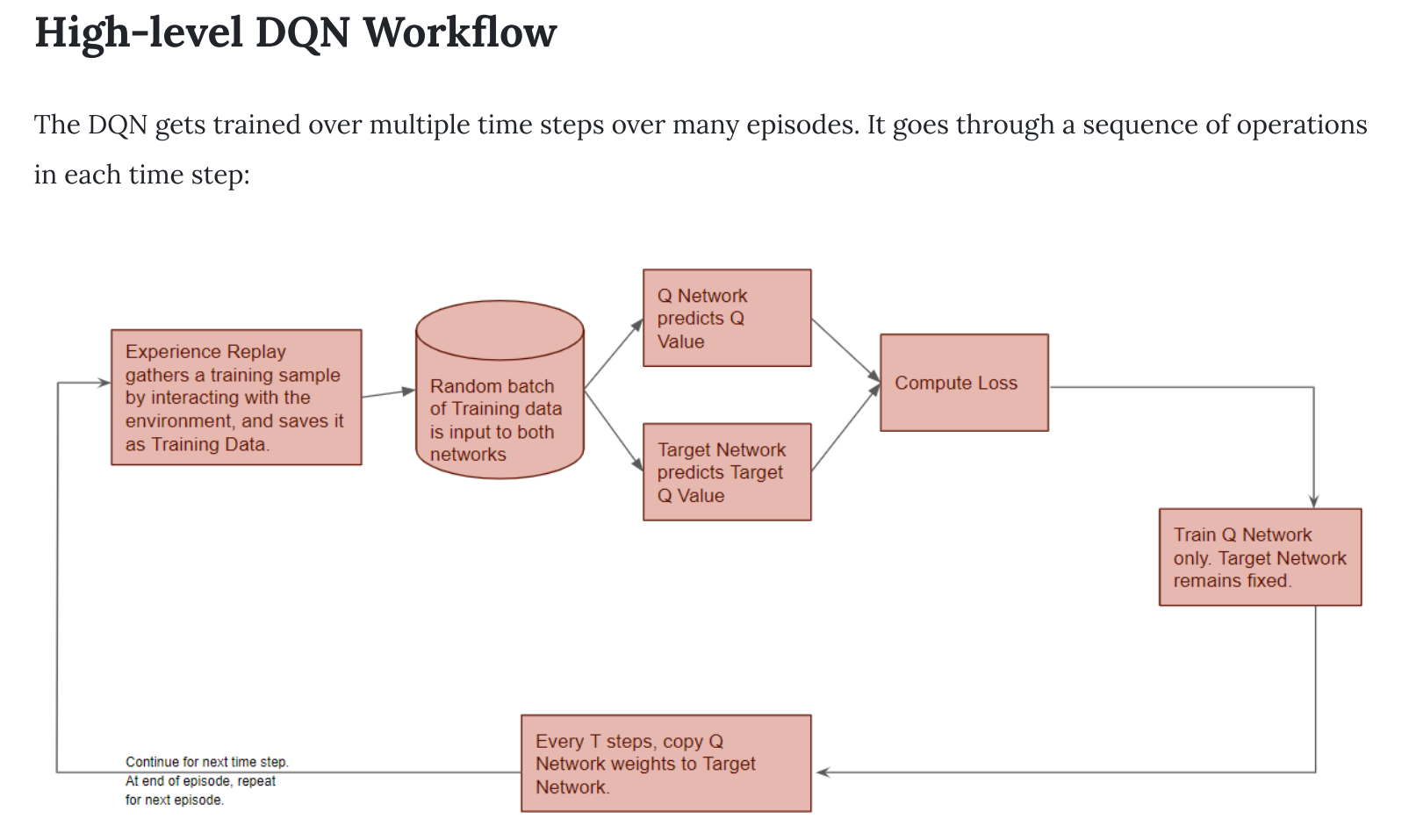
算法的更新是需要使用q_predict来逼近q_target,当两者相等时,算法将停止更新,当传统的qlearning转化为deep Qlearning,也是这样操作的,只是深度qlearning使用一个神经网络来表示q表。
Q(s,a)是什么?
Q ( s , a ) 是状态动作价值函数,是在状态s时采取动作a之后,可以获得的奖励的期望值。Q(s,a)越大表示在agent在看到状态s是采取动作a比较好。
Q表(DQN用deep network代替)
q表里面记录的都是状态动作价值函数,前面说到q表可以间接决定agent采取什么样的决策,就是因为q表记录了所有的状态和动作的组合情况,比如agent看到状态s2时,就会在状态s2所在的行选取最大的q值所对应的动作。
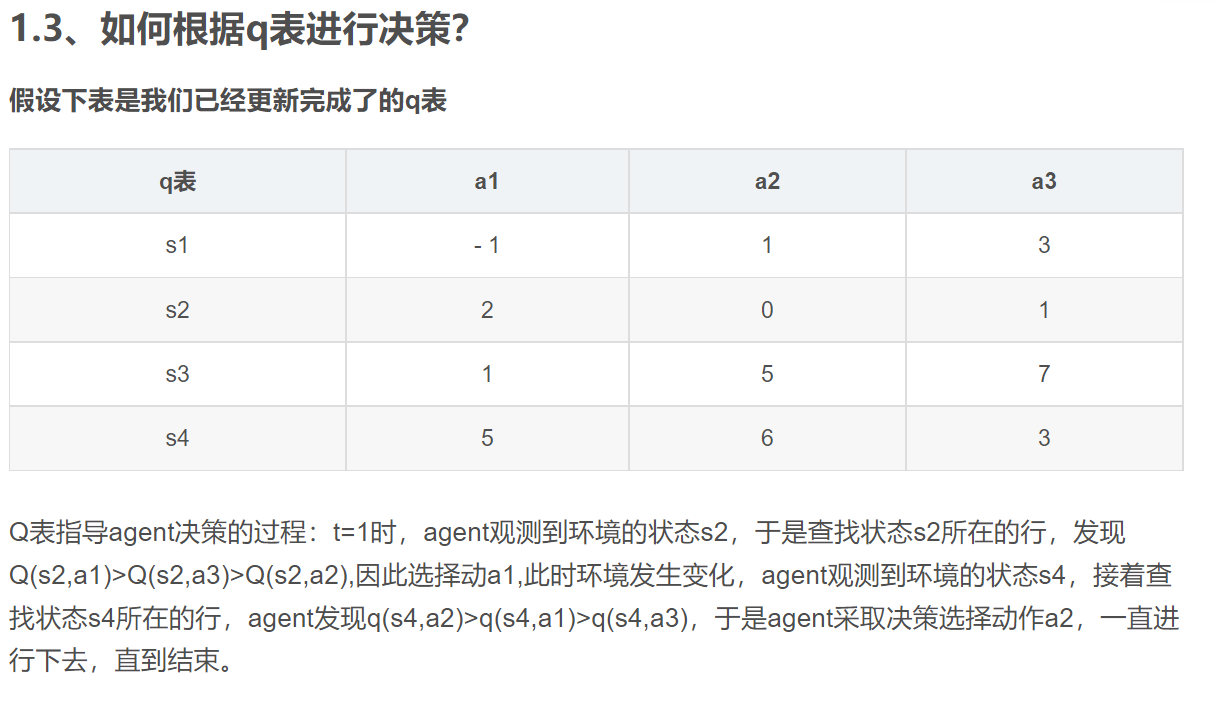
https://blog.csdn.net/qq_41626059/article/details/114364666
DQN
-
相关阅读:
React 配置别名 @ ( js/ts 项目中通过 @craco/craco 配置)
nodejs+vue+elementui宠物医院管理系统php-java-python
[激光原理与应用-33]:典型激光器 -5- 不同激光器的全面、综合比较
Databend v0.8 新版本上线!
overflow:auto的用法
MySQL与openGauss 时间操作比较分析
网络参考资料汇总(1)
【数据结构】排序1——排序的概述分类、存储结构定义
VOP —— Noise
【带限制的完全背包】Educational Codeforces Round 133 (Rated for Div. 2) D. Chip Move
- 原文地址:https://blog.csdn.net/mossfan/article/details/126874167