-
【目标检测】52、YOLOP | 一次就能完成全景驾驶的三大任务

论文:YOLOP: You Only Look Once for Panoptic Driving Perception
代码:https://github.com/hustvl/YOLOP
作者:华中科大王兴刚团队
时间:2022.03
贡献:
- 提出了一个高效的多任务网络,能够同时解决自动驾驶中的三个问题:目标检测、可通行区域分割、车道线检测,利于降低计算量并加速推理,首个在 BDD100K 上实现实时且 SOTA 的网络
- 在消融实验中证明了联合学习的效果,也证明了 grid-based 方法比 region-based 方法更适合检测+分割的多任务学习
一、背景
全景自动驾驶感知系统在自动驾驶系统中非常重要,可以帮助车辆做出正确的决策。
全景驾驶感知系统的两个重要的要求,也是挑战,分别是:
- High-precision
- Real-time
但全景驾驶面临的最大的难点在于:系统需要部署到边端设备上,需要优先考虑其有限的计算资源
还有一个隐藏的信息:全景驾驶系统虽然有多个任务,但这些任务面对的对象都是有一定的关联的。车道线通常是可通行区域的边界,可通行区域一般紧密的环绕在车辆等的周围,所以多任务网络非常适合解决这类问题:
- 多任务网络可以通过同时进行多个任务来加速图像分析
- 多任务网络可以进行多任务之间的 backbone 抽取特征的信息共享
基于上述讨论,提出了 panoptic driving perception network(YOLOP), 是一个支持多任务学习的全景感知网络,能够同时支持目标检测、可通行区域识别、车道线检测任务。
YOLOP 的构成:
- 一个 Encoder:用于特征提取
- 三个 Decoder:用于支持三个不同的任务

二、方法

2.1 Encoder
1、Backbone:使用 CSP-Darknet 作为 backbone(YOLOv4 中的)
2、Neck:SPP + FPN,SPP 生成并结合各个不同尺度的特征,FPN 结合各个不同语义尺度的特征,让组合后的特征包含多尺度和多语义层级的信息。
2.2 Decoder
1、Detect Head
和 YOLOv4 类似,使用 anchor-based multi-scale 检测方式:
- 首先,使用 PAN-FPN 结合的方式,FPN 是 top-down 的方式来传递语义特征,PAN 是 bottom-up 的方式来传递位置特征,两者结合能够让特征更好的融合,然后直接将 PAN 中的特征进行多尺度特征融合,用于检测。
- 然后,所有尺度的特征图中的每个 grid,都会被分配 3 个不同纵横比的 anchor,然后检测头回预测其位置偏移和宽高、类别得分。
2、Drivable Area Segmentation Head and Lane Line Segmentation Head
这两个头使用的是相同的网络结构,输入 FPN 的最后一层给分割分支,大小为 (W/8, H/8, 256)。
上采样 3 次后,最终的输出为 (W, H, 2),2 是分割类别:前景(可通行区域和车道线)+ 背景
3、Loss
由于有三个 decoder,所以也需要三部分的 loss 函数
① 检测任务的 loss: L d e t L_{det} Ldet

② 可通行区域分割的 loss: L d a − s e g L_{da-seg} Lda−seg,交叉熵 loss
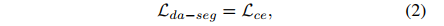
③ 车道线分割的 loss: L l l − s e g L_{ll-seg} Lll−seg,交叉熵 loss + IoU loss( L I o U = 1 − T P T P + F P + F N L_{IoU}=1-\frac{TP}{TP+FP+FN} LIoU=1−TP+FP+FNTP),因为车道线像素比较稀疏,IoU loss 更高效一些
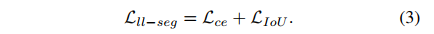
总的 loss 如下:

三、效果
数据集:BDD100K
共有 100K 数据,支持 10 个自动驾驶任务
训练,验证,测试 分别为 70k,10k,20k
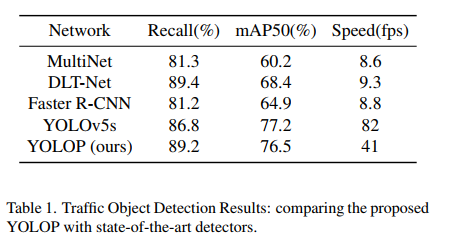
1、检测效果

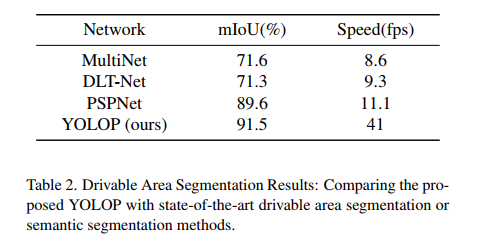
2、可通行区域分割效果

3、车道线分割效果


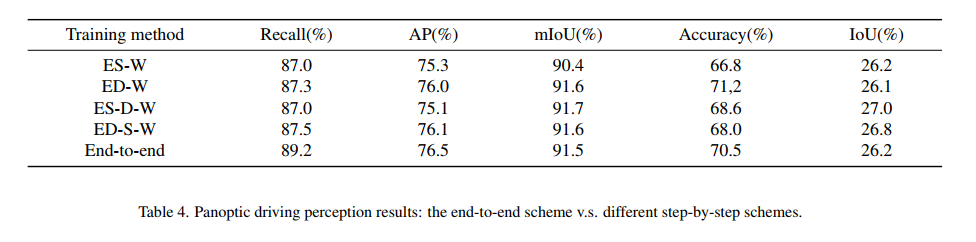
4、消融实验① 到底端到端训练好呢还是分步训练好呢
表 4 中对比了不同的训练方式:
- 端到端的训练效果已经很好了,但可以看出先训练检测任务效果会更好一些,这可能因为检测任务的 loss 最难收敛
- 三步训练略微优于两步训练
② 多任务效果好还是单任务效果好呢
表 5 对比了两种方式的效果:
- 多任务和单任务的效果类似
- 多任务可以节约很多时间

③ Region-based 方法好还是 Grid-based 方法好呢
作者给 Faster RCNN 添加了两个分割头,得到 R-CNNP,分别使用同时训练和单独训练的方式,结果如表 6。
- R-CNNP 结构,使用单独训练比联合训练效果好,多任务结合会影响 R-CNNP 这种结构,它是先选择候选区域,然后检测,和分割的过程不一致
- YOLOP 结构,多任务训练和单任务训练效果类似,作者猜测这是由于 YOLOP 的结构,它的检测和分割都是在整张图上去进行

-
相关阅读:
go-zero 是如何实现令牌桶限流的?
【2023-10-23】$(‘xx‘).css()方法设置元素css样式问题随记
我的第一个Spring MVC应用的过程与解释
CVE-2022-21907 Windows HTTP拒绝服务漏洞复现
深化产教融合,知了汇智助力高校数字化人才培养
SQL语句如何避免在mysql插入重复数据
Error: Activity class {xxx.java} does not exist
Mysql数据库大数据量的解决方案介绍(一、分库分表与读写分离)
PHP-面向服务器端的Web编程- print语句——直接打印内容,等效于echo “ 文本“
uCOSii中的互斥信号量
- 原文地址:https://blog.csdn.net/jiaoyangwm/article/details/126894424