-
Kafka架构和使用场景
Kafka和主流MQ对比

由上图可以看到,kafka一开始是不支持事务的,从0.11版本后开始支持,为什么这么厉害的组件一开始不支持事物呢?
这主要是因为它们的定位不一样,我们思考一个问题,假设公司现在用的是RabbitMQ,一般支持1-2W的吞吐量,此时突然产品爆火,吞吐量涨到了5W,而Kafka支持约10W的吞吐量,此时能否直接将应用简单的由RabbitMQ切换到Kafka上呢?
答案当然是否定的,这可能会导致很多问题,需要具体情况具体分析。分布式流式处理平台
Kafka是一个分布式流式处理平台。
流处理是什么?
就是在生产者(Producer)和消费者(Consumer)与kafka之间建立管道流,可以持续不断的向kafka交互,区别于其它MQ的建立连接、通道等,其显著特征就是实时性更好,速度更快,吞吐量更高。流处理平台特性
- 可以让你发布和订阅流式的记录。
- 可以存储流式的记录,并且有较好的容错性。
- 可以在流式记录产生时就进行处理。
Kafka适合什么样的场景?
- 构建实时流数据管道,它可以在系统或应用之间可靠地获取数据。(相当于消息队列)
- 构建实时流式应用程序,对这些流数据进行转换或者影响。
对流数据进行转换或者影响,可以理解为对数据做了个增强,类似于AOP之类的功能。
Kafka的特性
特性
- kafka作为一个集群运行在一个或多个服务器上
- kafka通过topic对存储的流数据进行分类
- 每条记录中包含一个key,一个value和一个timestamp(时间戳)
Topics
Topic就是数据主题,是数据记录发布的地方,可以用来区分业务系统。Kafka中的Topics总是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据。
对于每个topic,kafka集群都会维持一个分区日志,如图所示:

每个partition都可以理解为一个队列。
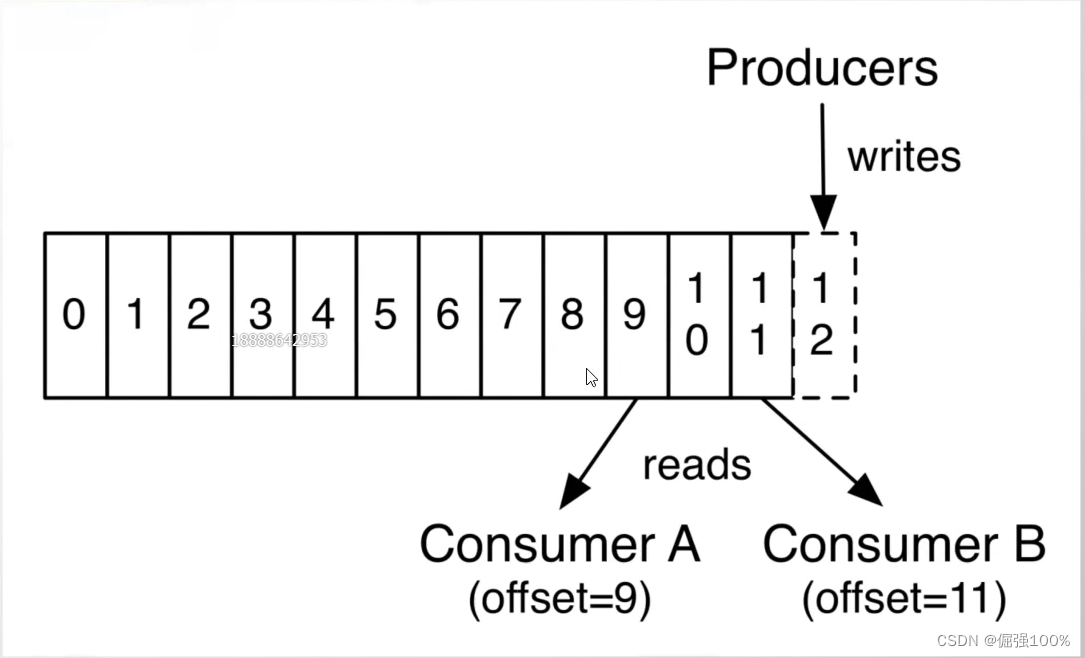
Distribution
Log的分区被分配到集群中的多个服务器上,每个服务器处理它分到的分区,根据配置每个分区还可以复制到其它服务器作为备份容错。
每个分区有一个leader,零或多个follower。Leader处理此分区的所有读写请求,而follower被动的复制数据。如果leader宕机,其它的一个follower会被推举成为新的leader。一台服务器可能同时是一个分区的leader,另一个分区的follower。这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。Consumers
消费者使用一个消费组名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例。消费者实例可以分布在多个进程中或者多个机器上。
- 如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例。
- 如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程。
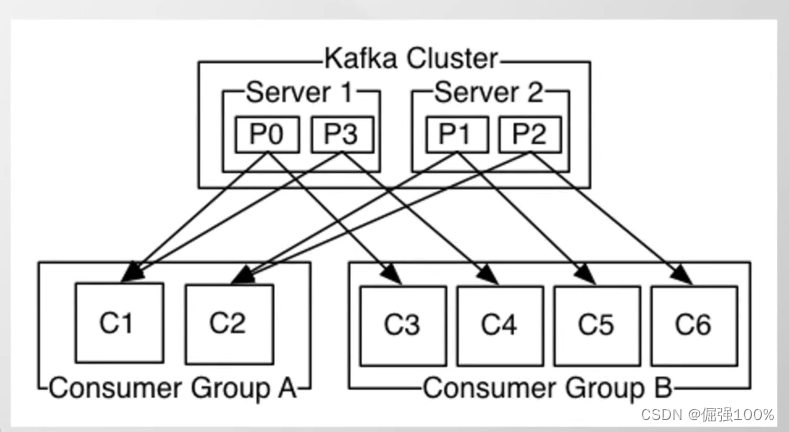
Replication
每个partition还会被复制到其它服务器作为replication,这是一种冗余备份的策略。

同一个partition的多个replication不允许在同一broker上
每个partition的replication中,有一个leader,零或多个follower
leader处理此分区的所有的读写请求,follower仅仅被动的复制数据
leader宕机后,会从follower中选举出新的leaderKafka整体架构

-
相关阅读:
Java发展简史
TCP和UDP的区别以及它们各自的优缺点
【踩坑指南】线程池使用不当的五个坑
信道复用技术
【ES6闯关】Promise堪比原生的自定义封装then、catch、resolve、reject...
集群部署看过来,低代码@AWS智能集群的架构与搭建方案
MySQL数据库约束与表的设计
YbtOJ「数据结构」第4章 线段树
雷电模拟器frida脱壳
【Nginx】nginx配置文件学习
- 原文地址:https://blog.csdn.net/qq_40359381/article/details/126700455