-
采用协同搜索策略的算术优化算法
一、理论基础
1、算术优化算法
请参考这里。
2、协同搜索策略的算术优化算法
(1)协同搜索策略
标准AOA算法的“乘法搜索”、“除法搜索”、“加法搜索”、“减法搜索”相互之间不能同时兼顾或协同开展搜索,在不同的搜索阶段均以相同的概率选择搜索策略。这种采用排他性的搜索切换策略,必然造成其相互之间不能同时兼顾和协同开展搜索,从而使个体的搜索效率低下,进而难以提升群体的全局搜索效率。因此,本文对标准AOA的公式进一步完善,分别改为式(1)和式(2): x ( t + 1 ) = w ( t ) × b e s t ( x ) ÷ ( M O P + ε ) × L × sin ( θ ) + w ( t ) × b e s t ( x ) × M O P × L × cos ( θ ) (1) x(t+1)=w(t)\times best(x)\div(MOP+\varepsilon)\times L\times\sin(\theta)+w(t)\times best(x)\times MOP\times L\times\cos(\theta)\tag{1} x(t+1)=w(t)×best(x)÷(MOP+ε)×L×sin(θ)+w(t)×best(x)×MOP×L×cos(θ)(1) x ( t + 1 ) = w ( t ) × b e s t ( x ) + sgn ( f ( b e s t ( x ) ) − f ( x ) ) × M O P × L (2) x(t+1)=w(t)\times best(x)+\text{sgn}(f(best(x))-f(x))\times MOP\times L\tag{2} x(t+1)=w(t)×best(x)+sgn(f(best(x))−f(x))×MOP×L(2)其中, θ \theta θ为 [ 0 , π ] [0,\pi] [0,π]中的随机角,式(1)兼顾了“乘法搜索”与“除法搜索”,让两种搜索协同并行开展全局勘探,强了个体的搜索能力,进而有效提升了算法的全局探索能力;利用两部分信息来指导个体开展协同搜索,提升了个体的搜索效率。式(2)中 sgn ( ) \text{sgn}() sgn()为符号函数, f ( b e s t ( x ) ) − f ( x ) f(best(x))-f(x) f(best(x))−f(x)表示种群最优个体的适应度值减去当前个体的适应度值。式(2)中,利用符号函数动态切换法则,让减法搜索与加法搜索协同执行,增强了个体的局部搜索能力;利用最优个体的适应度值进行信息引导,可使搜索个体对减法搜索与加法搜索的选择更具有指向性,增强了算法的局部寻优能力,进而提升了算法的优化精度。其中, w ( t ) = 1.1 − g b e s t / f i t a v g w(t)=1.1-gbest/fit_{avg} w(t)=1.1−gbest/fitavg, g b e s t gbest gbest表示当前最优个体适应度值, f i t a v g fit_{avg} fitavg表示当前种群的平均适应度值, w ( t ) w(t) w(t)表示为一个基于适应度值反馈的惯性权重。算法在前期整体的离散程度较高,最优个体的适应度值和种群适应度平均值有着较大差距,因此, g b e s t / f i t a v g gbest/fit_{avg} gbest/fitavg的比值在算法前期较小,则惯性权重 w ( t ) w(t) w(t)较大,较大的惯性权重有利于算法的勘探行为;随着迭代次数的增加,更多的个体向最优解附近靠近,因此 g b e s t / f i t a v g gbest/fit_{avg} gbest/fitavg比值逐渐增大,惯性权重 w ( t ) w(t) w(t)减小,较小的惯性权重有利于算法的开发行为,加快算法对最优目标的获取。
(2)设计新的MOA
标准AOA利用MOA来切换“全局探索”与“局部开发”时,造成算法在搜索后期进行局部开发的概率反而比进行全局勘探的小,这与一般智能优化算法普遍采用“算法在搜索前期侧重进行全局探索、在后期侧重开展局部开发”搜索策略不一致,削弱了在算法后期的局部开发能力,这不利于算法的寻优速度和精度。因此本文设计新的 M O A ( t ) MOA(t) MOA(t),如式(3)所示: M O A ( t ) = a × ( 1 − exp ( − ( T − t ) / T ) ) + b (3) MOA(t)=a\times(1-\exp(-(T-t)/T))+b\tag{3} MOA(t)=a×(1−exp(−(T−t)/T))+b(3)其中, a = 0.8 a=0.8 a=0.8, b = 0.2 b=0.2 b=0.2,新的 M O A ( t ) MOA(t) MOA(t)是一个关于 t t t的非线性单调递减函数。本文利用 M O A ( t ) MOA(t) MOA(t)来控制执行全局探索与执行局部开发的个体数,来实现“在算法搜索的前期以较大概率进行全局探索、在算法搜索后期以较大概率进行局部开发”目标。这使得算法在搜索前期投入更多的个体进行全局勘探,在算法搜索后期则投入更多个体进行局部开发,以提升算法的收敛速度。
(3)采用外抛交叉变异策略
对于种群过度聚集容易造成算法陷入局部最优,本文设计一种新的判别系数以此判断种群是否陷入局部最优,从而实施变异操作。
假设第 t t t次迭代时第 i i i个体的最优适应度值为 f i t i fit_i fiti,如果该个体连续两次迭代其适应度值未发生改变,则该个体可能陷入局部最优,即 f i t i t − f i t i t − 2 fit_i^t-fit_i^{t-2} fitit−fitit−2的值为0。因此,本文设计一种新的判别系数,其数学表达式如式(4)(5)所示。 H i ( t ) = { 1 , ( f i t i t − f i t i t − 2 ) = 0 0 , otherwise (4) H_i(t)=\tag{4} Hi(t)=⎩ ⎨ ⎧1,(fitit−fitit−2)=00,otherwise(4) P ( t ) = ∑ i = 1 N H i ( t ) N (5) P(t)=\frac{\displaystyle\sum_{i=1}^NH_i(t)}{N}\tag{5} P(t)=Ni=1∑NHi(t)(5)其中, N N N为种群规模, H i ( t ) H_i(t) Hi(t)表示判别第 t t t次迭代第 i i i个体是否陷入局部最优,而 P ( t ) P(t) P(t)则表示第 t t t次迭代,种群总体陷入局部最优的程度,从式(5)可以看出, P ( t ) P(t) P(t)的值越大,则算法陷入局部最优的可能性越大。因此,在本文当中,若 P ( t ) > r a n d P(t)>rand P(t)>rand,则对最优个体进行交叉变异。从 P ( t ) P(t) P(t)的大小可知, P ( t ) P(t) P(t)越大则变异概率越大,算法摆脱局部最优的概率越大。其中交叉变异的步骤如下:\begin{dcases}1,\quad (fit_i^t-fit_i^{t-2})=0\\[2ex]0,\quad\text{otherwise}\end{dcases}
(1)设群体当前最优个体为 X b e s t X_{best} Xbest,随机选择的个体为 P r a n d P_{rand} Prand,其分别如式(6)所示, d i m dim dim表示个体的维度。 X b e s t = { x 1 , x 2 , ⋯ , x d i m } P r a n d = { p 1 , p 2 , ⋯ , p d i m } (6)\tag{6} Xbest={x1,x2,⋯,xdim}Prand={p1,p2,⋯,pdim}(6)(2)产生一个 d i m dim dim维度的交叉模板 N = { n 1 , n 2 , ⋯ , n d i m } N=\{n_1,n_2,\cdots,n_{dim}\} N={n1,n2,⋯,ndim},其中 n j = 0 , 1 , j = 1 , 2 , ⋯ , d i m n_j=0,1,j=1,2,\cdots,dim nj=0,1,j=1,2,⋯,dim, 0 0 0表示交叉, 1 1 1表示不交叉;产生一个在 [ 0 , 1 ] [0,1] [0,1]范围内 d i m dim dim维度的数 T = { t 1 , t 2 , ⋯ , t d i m } T=\{t_1,t_2,\cdots,t_{dim}\} T={t1,t2,⋯,tdim};在 [ − 1 , 1 ] [-1,1] [−1,1]中生成一个外抛系数 A = [ a 1 , a 2 , ⋯ , a d i m ] A=[a_1,a_2,\cdots,a_{dim}] A=[a1,a2,⋯,adim],即 a j ∈ [ − 1 , 1 ] a_j\in[-1,1] aj∈[−1,1]。最优个体 X b e s t X_{best} Xbest与随机个体 P r a n d P_{rand} Prand进行交叉操作后,得到的个体位置如式(7)所示: X n e w b e s t = { x 1 + a 1 n 1 ( 1 − t 1 p 1 ) , x 2 + a 2 n 2 ( 1 − t 2 p 2 ) , ⋯ , x d i m + a d i m n d i m ( 1 − t d i m p d i m ) } P r a n d = { p 1 + a 1 n 1 ( 1 − t 1 x 1 ) , p 2 + a 2 n 2 ( 1 − t 2 x 2 ) , ⋯ , p d i m + a d i m n d i m ( 1 − t d i m x d i m ) } (7)X b e s t = { x 1 , x 2 , ⋯ , x d i m } P r a n d = { p 1 , p 2 , ⋯ , p d i m } \tag{7} Xnewbest={x1+a1n1(1−t1p1),x2+a2n2(1−t2p2),⋯,xdim+adimndim(1−tdimpdim)}Prand={p1+a1n1(1−t1x1),p2+a2n2(1−t2x2),⋯,pdim+adimndim(1−tdimxdim)}(7)其中,系数 T = { t 1 , t 2 , ⋯ , t d i m } T = \{t_1,t_2,\cdots,t_{dim}\} T={t1,t2,⋯,tdim}表示交叉系数,最优个体通过与随机个体进行交叉信息交流,调整最优个体的搜索步长;利用 N = { n 1 , n 2 , ⋯ , n d i m } N = \{n_1,n_2,\cdots,n_{dim}\} N={n1,n2,⋯,ndim}来控制是否要进行维度交叉、以及哪个维度需要进行交叉操作; A = { a 1 , a 2 , ⋯ , a d i m } A = \{a_1,a_2,\cdots,a_{dim}\} A={a1,a2,⋯,adim}表示外抛系数,从 A A A的取值范围可以看出,其使得最优个体的每个维度的朝向有所区别,以此来增加最优个体搜索方向的多样性和跳出当前局部最优位置的能力,从而保证了在算法搜索前期不至于吸引过多个体过早聚集到群体当前最优位置的较小范围内开展搜索,增强了算法搜索跳出局部最优的能力。经式(7)变异操作后得到 X n e w b e s t X_{newbest} Xnewbest,并将 X n e w b e s t X_{newbest} Xnewbest与原群体当前最优个体 X b e s t X_{best} Xbest进行适应度值比较,若 X n e w b e s t X_{newbest} Xnewbest优于 X b e s t X_{best} Xbest,则更新 X b e s t X_{best} Xbest;否则不更新。X n e w b e s t = { x 1 + a 1 n 1 ( 1 − t 1 p 1 ) , x 2 + a 2 n 2 ( 1 − t 2 p 2 ) , ⋯ , x d i m + a d i m n d i m ( 1 − t d i m p d i m ) } P r a n d = { p 1 + a 1 n 1 ( 1 − t 1 x 1 ) , p 2 + a 2 n 2 ( 1 − t 2 x 2 ) , ⋯ , p d i m + a d i m n d i m ( 1 − t d i m x d i m ) } (4)改进算法执行步骤
步骤1:初始化种群规模 N N N、搜索空间维度 D i m Dim Dim、最大迭代次数 T T T、搜索范围上界 U B UB UB和下界 L B LB LB。
步骤2:使用式(3)计算 M O A ( t ) MOA(t) MOA(t),使用原始算法对应公式计算 M O P ( t ) MOP(t) MOP(t),使用原始算法对应公式计算出 L L L,产生随机数 r 1 r_1 r1,找出当前最优个体 b e s t ( x ) best(x) best(x)。
步骤3:如果 r 1 < M O A ( t ) r_1
步骤4:利用式(5)(7)进行变异操作,并保留优秀变异个体。
步骤5:判断算法是否达到最大迭代次数,满足算法结束条件,否则执行步骤2。
步骤6:算法结束,输出最优个体为寻优结果。二、仿真实验与结果分析
将CSSAOA与AOA、SCA、HHO和SSA进行对比,以文献[1]中表1的8个测试函数为例,实验设置种群规模为30,最大迭代次数为500,每种算法独立运算30次,结果显示如下:
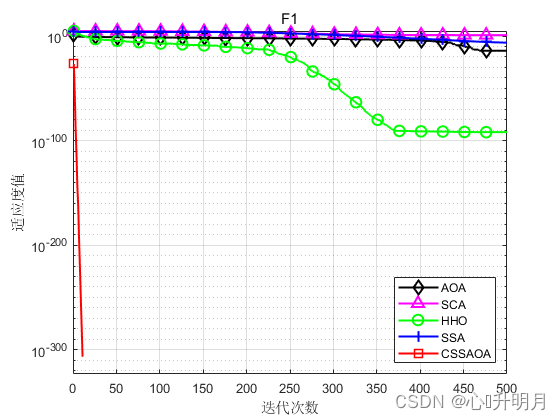

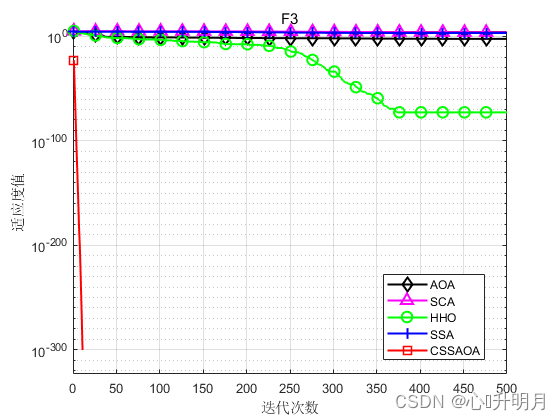
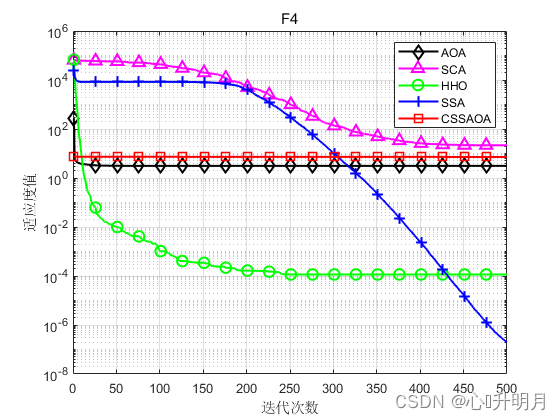
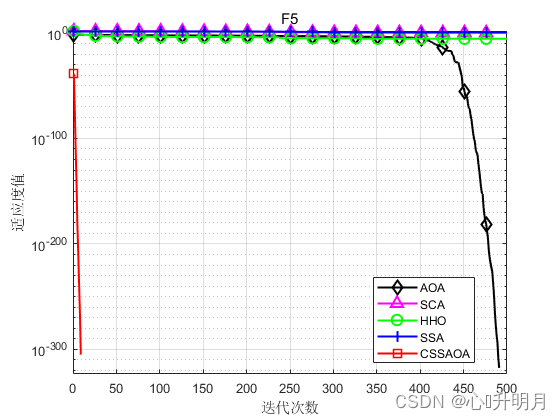
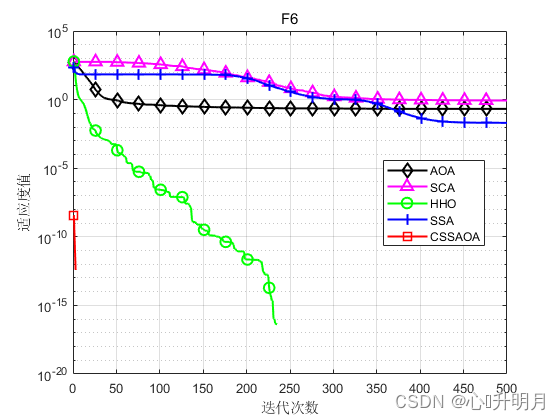
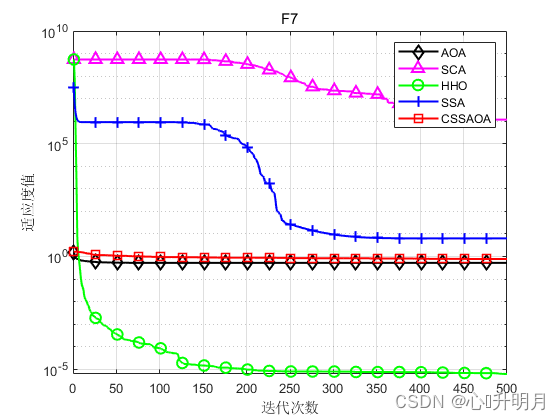
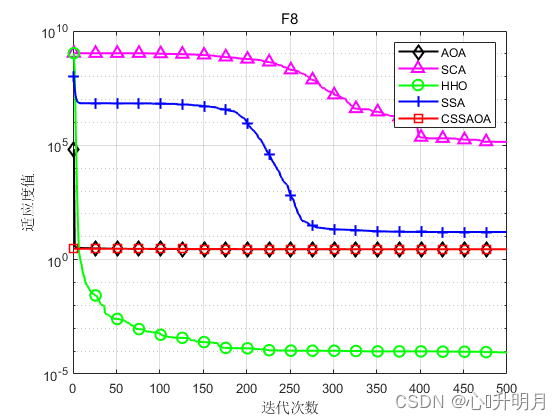
函数:F1 AOA:Best: 6.4094e-138,Worst: 2.3872e-13,Mean: 7.9573e-15,Sstd: 4.3584e-14 SCA:Best: 0.070536,Worst: 42.0846,Mean: 7.9515,Std: 10.7137 HHO:Best: 9.4807e-112,Worst: 3.2852e-91,Mean: 1.1023e-92,Std: 5.9967e-92 SSA:Best: 5.0654e-08,Worst: 4.3504e-06,Mean: 4.9993e-07,Std: 1.0517e-06 CSSAOA:Best: 0,Worst: 0,Mean: 0,Std: 0 函数:F2 AOA:Best: 0,Worst: 0,Mean: 0,Sstd: 0 SCA:Best: 0.00040208,Worst: 0.11987,Mean: 0.019185,Std: 0.027371 HHO:Best: 6.3858e-59,Worst: 3.0643e-47,Mean: 1.0248e-48,Std: 5.5939e-48 SSA:Best: 0.14405,Worst: 9.0078,Mean: 2.4097,Std: 2.3144 CSSAOA:Best: 0,Worst: 0,Mean: 0,Std: 0 函数:F3 AOA:Best: 1.8871e-124,Worst: 0.025435,Mean: 0.0043121,Sstd: 0.0073235 SCA:Best: 1283.0542,Worst: 26791.7263,Mean: 7799.5531,Std: 5799.132 HHO:Best: 1.0331e-100,Worst: 4.1434e-72,Mean: 1.8986e-73,Std: 7.722e-73 SSA:Best: 278.5585,Worst: 3703.6861,Mean: 1701.512,Std: 947.3121 CSSAOA:Best: 0,Worst: 0,Mean: 0,Std: 0 函数:F4 AOA:Best: 2.642,Worst: 3.7117,Mean: 3.1243,Sstd: 0.25563 SCA:Best: 4.3875,Worst: 178.0639,Mean: 21.7076,Std: 32.0023 HHO:Best: 2.1826e-08,Worst: 0.0006211,Mean: 0.00011523,Std: 0.00014831 SSA:Best: 3.2322e-08,Worst: 1.9346e-06,Mean: 1.9846e-07,Std: 3.478e-07 CSSAOA:Best: 6.1621,Worst: 7.5,Mean: 7.1872,Std: 0.40006 函数:F5 AOA:Best: 0,Worst: 0,Mean: 0,Sstd: 0 SCA:Best: 0.0020416,Worst: 11.2677,Mean: 1.1965,Std: 2.5587 HHO:Best: 1.8078e-63,Worst: 6.6982e-05,Mean: 3.2461e-06,Std: 1.3254e-05 SSA:Best: 1.0562,Worst: 9.6992,Mean: 4.3554,Std: 2.2121 CSSAOA:Best: 0,Worst: 0,Mean: 0,Std: 0 函数:F6 AOA:Best: 1.0685e-05,Worst: 0.6464,Mean: 0.20884,Sstd: 0.16623 SCA:Best: 0.14136,Worst: 1.6939,Mean: 0.86783,Std: 0.32412 HHO:Best: 0,Worst: 0,Mean: 0,Std: 0 SSA:Best: 0.00094328,Worst: 0.047327,Mean: 0.020294,Std: 0.013195 CSSAOA:Best: 0,Worst: 0,Mean: 0,Std: 0 函数:F7 AOA:Best: 0.43639,Worst: 0.62786,Mean: 0.5185,Sstd: 0.041555 SCA:Best: 0.71592,Worst: 30100281.7357,Mean: 1168637.8318,Std: 5512504.3544 HHO:Best: 1.9642e-08,Worst: 3.4944e-05,Mean: 6.153e-06,Std: 7.3579e-06 SSA:Best: 1.784,Worst: 12.8744,Mean: 6.329,Std: 2.5647 CSSAOA:Best: 0.35899,Worst: 1.1349,Mean: 0.77614,Std: 0.19035 函数:F8 AOA:Best: 2.6816,Worst: 2.9916,Mean: 2.8555,Sstd: 0.077301 SCA:Best: 2.8107,Worst: 2461483.6,Mean: 140882.3227,Std: 458195.1123 HHO:Best: 7.3174e-07,Worst: 0.00044404,Mean: 8.8381e-05,Std: 0.00011946 SSA:Best: 0.044397,Worst: 44.397,Mean: 16.1635,Std: 16.0519 CSSAOA:Best: 1.1791,Worst: 2.9662,Mean: 2.8391,Std: 0.41205- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
实验结果表明:CSSAOA具有更快的全局收敛速度和更高的优化精度。
三、参考文献
[1] 付小朋, 王勇, 冯爱武. 采用协同搜索策略的算术优化算法[J/OL]. 小型微型计算机系统: 1-9 [2022-09-16].
-
相关阅读:
docker (五) (搭建MySQL数据库集群)
VUE模板语法1
DIRECT_IO 配置参数(UNIX)
[ 渗透工具篇 ] 一篇文章让你掌握神奇的shuize -- 信息收集自动化工具
模电|PN结及其单向导电性
DDD领域驱动设计-何时要用DDD
ts+axios 定义接口返回值的类型
Python计算机毕业设计基于Django的学生作业管理系统
什么是Java?java是用来做什么的?
前端面试题及答案整理(2022最新版)
- 原文地址:https://blog.csdn.net/weixin_43821559/article/details/126889289