-
分库分表三:ShardingJDBC进阶实战案例下
ShardingJDBC进阶实战案例下
对ShardingSphere了解不多的话请先看前两篇博客
分库分表一:ShardingSphere介绍和入门实战
分库分表二:ShardingJDBC进阶实战案例上SPI机制介绍
首先来来了解什么是SPI。
在Apache ShardingSphere中,很多功能实现类的加载方式是通过SPI注入的方式完成的。 Service Provider Interface (SPI)是一种为了被第三方实现或扩展的API,它可以用于实现框架扩展或组件替换。
Apache ShardingSphere之所以采用SPI方式进行扩展,是出于整体架构最优设计考虑。 为了让高级用户通过实现Apache ShardingSphere提供的相应接口,动态将用户自定义的实现类加载其中,从而在保持Apache ShardingSphere架构完整性与功能稳定性的情况下,满足用户不同场景的实际需求。
有哪些通过spi加载的模块呢?从官网截取


具体信息可查看官网https://shardingsphere.apache.org/document/4.1.1/cn/features/spi/SPI机制是怎么注入的,后续在源码分析中会分析到,现在直接来说结果,
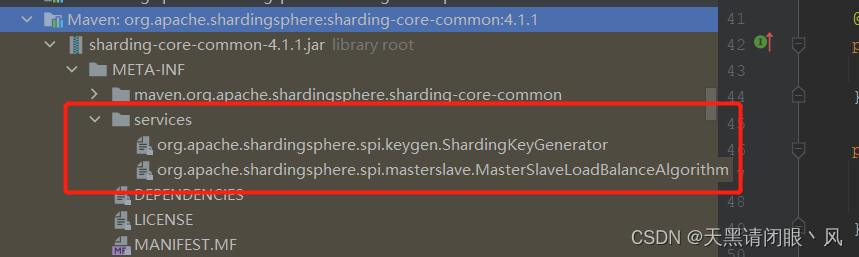
这就是spi加载的路径,该路径下的两个文件就是shardingjdbc需要加载类。
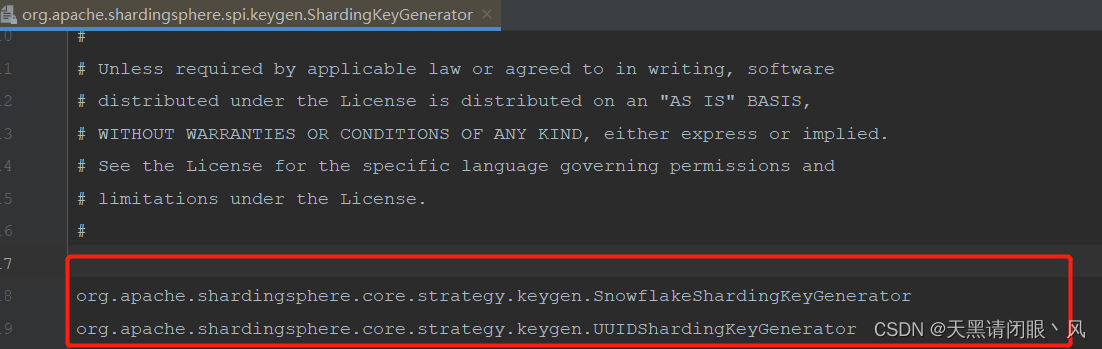
也就是说shardingjdbc会扫描META-INF/service下的文件获取到全类名,进行加载。知道了spi是如何加载的,接下来就通过这样的机制实现自定义主键生成策略自定义主键生成策略
主键策略需要实现ShardingKeyGenerator接口
public class MyShardingKeyGenerator implements ShardingKeyGenerator { private static final long WORKER_ID = 1; @Getter @Setter private Properties properties = new Properties(); @Override public synchronized Comparable<?> generateKey() { long workerId = getWorkerId(); Snowflake snowflake = IdUtil.getSnowflake(workerId); String snowflakeId = snowflake.nextIdStr(); Calendar calendar = Calendar.getInstance(); int i = calendar.get(Calendar.MONTH) + 1; String monthString = ""; if (i >= 10){ monthString = i+""; }else { monthString = "0"+i; } String substring = snowflakeId.substring(3); String first = snowflakeId.substring(0, 1); String idString = first + monthString + substring; return Long.valueOf(idString); } @Override public String getType() { return "CUSTOMID"; } private long getWorkerId() { long result = Long.valueOf(properties.getProperty("worker.id", String.valueOf(WORKER_ID))); return result; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
其中getType的返回值对应
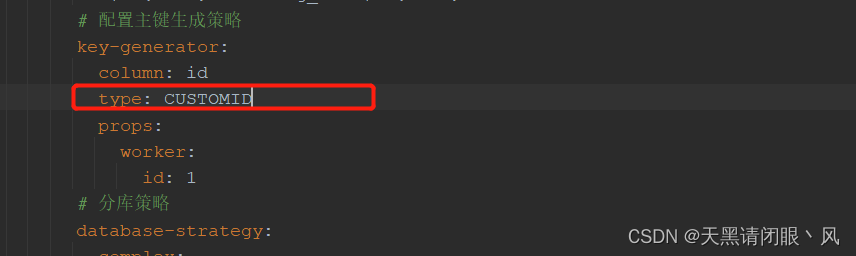
getWorkerId()方法从配置中获取worker.id的值
generateKey()主键返回的值,在这里定义算法。这个例子中,把月份插入到雪花id中。在上一篇的案例四中,通过id可以确定表,那么现在通过id也可以确定库了。
在配置文件如何配置我们的主键生成策略,就是如上图的配置,把getType的返回值配到主键策略的地方即可。配置好之后在项目resource下创建META-INF/service,创建org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator文件
在该文件中添加以下代码//这两个是shardingjdbc提供的主键生成策略 org.apache.shardingsphere.core.strategy.keygen.SnowflakeShardingKeyGenerator org.apache.shardingsphere.core.strategy.keygen.UUIDShardingKeyGenerator //自定义主键生成策略的全类名 org.springblade.common.shardingJDBC.MyShardingKeyGenerator- 1
- 2
- 3
- 4
- 5
如图:


这一步一定要完成,不然加载不到自定义的类。同理其他的模块sql解析、数据库协议、数据脱敏、XA事务管理器等等 都可以通过spi机制来自定义。
案例六:两表关联对应插入和查询
在实际开发中遇到过类似的功能,对用户表和视频表进行分表,user表1的用户上传的视频存在video表1,同理,表2的用户对应视频也要在表2。当然除了表对应库也要对应。
user和video表,分两库两表
环境准备CREATE TABLE `sharding_user` ( `id` bigint(11) NOT NULL AUTO_INCREMENT, `user_name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, `source` varchar(255) DEFAULT 'test', `create_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; CREATE TABLE `sharding_video` ( `id` bigint(20) NOT NULL, `video_name` varchar(255) DEFAULT NULL, `user_id` bigint(20) DEFAULT NULL, `create_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, `source` varchar(255) DEFAULT 'test', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

对应实体类和service mapper controller等都创建好,在此省略。分片规划
用户不需要范围查询,选择标准分片策略,分片键为主键,视频要和用户表对应那么也只能选择userId作为分片键。为了更好的测试和模拟数据,用户表主键通过setid方法赋值,视频表选择雪花算法。
用户表主键生成算法//把月份替换雪花id的1 2位 public synchronized Long generateKey() { long workerId = 1L; Snowflake snowflake = IdUtil.getSnowflake(workerId); String snowflakeId = snowflake.nextIdStr(); //随机生成月份 int i = new Random().nextInt(12)+1; String monthString = ""; if (i >= 10){ monthString = i+""; }else { monthString = "0"+i; } String substring = snowflakeId.substring(3); String first = snowflakeId.substring(0, 1); String idString = first + monthString + substring; return Long.valueOf(idString); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
用户表分库分表算法
用户表不需要范围查询,所以只需要实现PreciseShardingAlgorithm接口//分库算法 把1-6 月份放到1号库 7-12月份放到2号库 public class MyDbMonthPreciseSharding implements PreciseShardingAlgorithm<Long> { @Override public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) { String dbIndex = ""; String id = shardingValue.getValue()+""; String monthString = id.substring(1, 3); int month = Integer.valueOf(monthString); if (month>=1 && month<=6){ dbIndex = "m1"; }else if (month >=7 && month <=12){ dbIndex = "m2"; }else { dbIndex = "errorDB"; } if(availableTargetNames.contains(dbIndex)){ return dbIndex; } throw new UnsupportedOperationException(" route "+dbIndex+" is not supported. please check your config"); } } //分表算法 按照id的奇偶数来分 public class MyTableMonthPreciseSharding implements PreciseShardingAlgorithm<Long> { @Override public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) { Long id = shardingValue.getValue(); Long inddex = (id % 2) + 1; String logicTableName = shardingValue.getLogicTableName(); String tabesName = logicTableName + inddex; if (availableTargetNames.contains(tabesName)) return tabesName; throw new UnsupportedOperationException(" route " + tabesName + " is not supported. please check your config"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
视频表分库分表算法
视频表根据userId作为分片键,使用user表定义的分库分表算法即可。
yml配置shardingsphere: props: # 开启sql打印 sql: show: true datasource: # 配置逻辑库名 names: m1,m2 m1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/sharding_test?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true username: root password: root m2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://xxx/xmkf_zt?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true&rewriteBatchedStatements=true username: xxx password: xxx sharding: # 分库分表配置 tables: # 配置逻辑表名 sharding_user: actual-data-nodes: # 逻辑库逻辑表对应真实库、表的关系 m$->{1..2}.sharding_user$->{1..2} # 分库策略 database-strategy: standard: # 分片键 sharding-column: id # 分片算法 precise-algorithm-class-name: org.springblade.common.shardingJDBC.MyDbMonthPreciseSharding table-strategy: standard: # 分片键 sharding-column: id # 分片算法 precise-algorithm-class-name: org.springblade.common.shardingJDBC.MyTableMonthPreciseSharding sharding_video: actual-data-nodes: # 逻辑库逻辑表对应真实库、表的关系 m$->{1..2}.sharding_video$->{1..2} # 配置主键生成策略 key-generator: column: id type: SNOWFLAKE props: worker: id: 1 # 分库策略 database-strategy: standard: # 分片键 sharding-column: user_id # 分片算法 precise-algorithm-class-name: org.springblade.common.shardingJDBC.MyDbMonthPreciseSharding # 分表策略 table-strategy: standard: # 分片键 sharding-column: user_id # 分片算法 precise-algorithm-class-name: org.springblade.common.shardingJDBC.MyTableMonthPreciseSharding- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
测试插入
@GetMapping("/shardingTest") @ApiOperation(value = "测试分库分表") @ApiOperationSupport(order = 9, author = "lsx") public R shardingTest(String name, Integer age) { List<ShardingUser> list = new ArrayList<>(); List<ShardingVideo> videos = new ArrayList<>(); Calendar c = Calendar.getInstance(); for (int i = 0; i < 10; i++) { ShardingUser user = new ShardingUser(); int month = new Random().nextInt(12); user.setId(generateKey()); user.setUserName(name + i); user.setAge(20+i); c.set(2022, month, new Random().nextInt(29)); user.setCreateTime(c.getTime()); list.add(user); for (int j = 0; j < 5; j++) { ShardingVideo video = new ShardingVideo(); video.setUserId(user.getId()); c.set(2022, new Random().nextInt(12), new Random().nextInt(29)); video.setCreateTime(c.getTime()); videos.add(video); } } //案例不做事务处理 shardingUserService.saveBatch(list); videoService.saveBatch(videos); return R.success("成功"); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
插入10个用户 每个用户5条视频数据 m1库user1的用户对应的视频保存在m1库的video1 ,
测试查询
查询用户id对应的视频数据 在m1库中有userId = 1060647147919970306,查询它的视频数据@GetMapping("/shardingQuery") @ApiOperation(value = "测试分库分表查询") @ApiOperationSupport(order = 10, author = "lsx") public R shardingQuery(String id) { QueryWrapper<ShardingVideo> query = new QueryWrapper<>(); query.eq("user_id",Long.valueOf(id)); List<ShardingVideo> list = videoService.list(query); return R.data(list); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9


查询视频的时候就会从 m1库的video1 去查。这样成功了。
那如果是join 联查查呢,通过userId查询视频数据并带有用户信息。@Select("select * from sharding_video as v left join sharding_user as u on v.user_id = u.id" + " where user_id = #{id}") List<Map<String,Object>> selectVideo(Long userId);- 1
- 2
- 3
比如执行上述sql

可以看出除了搜索user1还搜索了user2。这就不是我们想要的,因为video1对应用户只在user1 所以只搜索user1就好了,并且返回的数据也不是我们想要的,之前插入是每个用户5个视频,那么根据userId搜索到也应该是5条记录,但是实际上

返回了十条。
那么怎么解决呢 通过绑定表关联。案例七:绑定表解决join查询问题
上一个案例在join查询的时候出现问题。现在通过绑定表来解决这个问题。
首先代码都不需要变,配置文件加上绑定关系shardingsphere: props: # 开启sql打印 sql: show: true datasource: # 配置逻辑库名 names: m1,m2 m1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/sharding_test?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true username: root password: root m2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://xxx/xmkf_zt?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true&rewriteBatchedStatements=true username: xxx password: xxx sharding: # 分库分表配置 tables: # 配置逻辑表名 sharding_user: actual-data-nodes: # 逻辑库逻辑表对应真实库、表的关系 m$->{1..2}.sharding_user$->{1..2} # 分库策略 database-strategy: standard: # 分片键 sharding-column: id # 分片算法 precise-algorithm-class-name: org.springblade.common.shardingJDBC.MyDbMonthPreciseSharding table-strategy: standard: # 分片键 sharding-column: id # 分片算法 precise-algorithm-class-name: org.springblade.common.shardingJDBC.MyTableMonthPreciseSharding sharding_video: actual-data-nodes: # 逻辑库逻辑表对应真实库、表的关系 m$->{1..2}.sharding_video$->{1..2} # 配置主键生成策略 key-generator: column: id type: SNOWFLAKE props: worker: id: 1 # 分库策略 database-strategy: standard: # 分片键 sharding-column: user_id # 分片算法 precise-algorithm-class-name: org.springblade.common.shardingJDBC.MyDbMonthPreciseSharding # 分表策略 table-strategy: standard: # 分片键 sharding-column: user_id # 分片算法 precise-algorithm-class-name: org.springblade.common.shardingJDBC.MyTableMonthPreciseSharding # 增加绑定关系 该属性是一个数组 binding-tables: - sharding_video,sharding_user- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
在执行之前的sql


这样sql就是正常了,没有查询多余的表
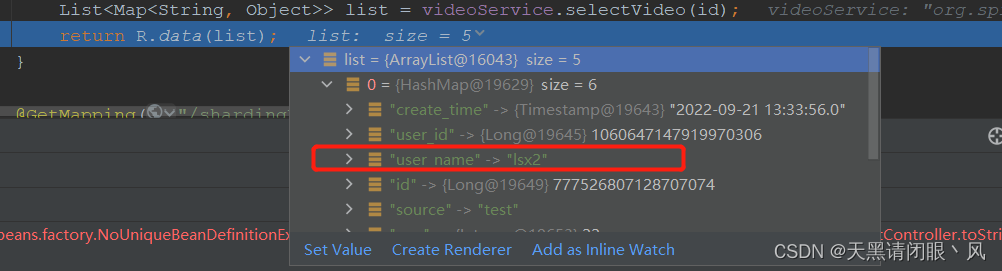
并且返回的数据也是正常的。 -
相关阅读:
股票价格预测 | Python实现基于LSTM与Transfomer的股票预测模型(pytorch)
MySQL数据库——SQL优化(2)-order by 优化、group by 优化
linux 进程组和会话和线程
Spring Security—OAuth 2.0 资源服务器的多租户
C#实现批量生成二维码
C# PDF转HTML字符串
React函数组件和类组件生命周期比较
零基础Linux_7(进程)冯诺依曼结构+操作系统原理+进程的概念和基本操作
C++编程练习系列(1)C++和标准库速成
vue3打包报错: “@charset“ must be the first rule in the file“
- 原文地址:https://blog.csdn.net/admin522043032/article/details/126883704
