-
第六章 机器学习技巧——参数的更新&权重的初始值&Batch Normalization&正则化&超参数的验证
1.参数的更新
*神经网络的学习目的是找到使损失函数的值尽可能小的参数,这是寻找最优参数的问题,解决这个问题的过程称为最优化
(1)SGD(随机梯度下降法)



(2)Momentum

v对应物理上的速度,表示了物体在梯度方向上受力,在这个力的作用下,物体的速度增加

(3)AdaGrad
AdaGrad会为参数的每个元素适当的调整学习率

h保存了以前的所有梯度值的平方和,
 表示对应矩阵元素的乘法。在更新参数时,参数的元素中变动较大的元素的学习率将变小
表示对应矩阵元素的乘法。在更新参数时,参数的元素中变动较大的元素的学习率将变小
(4)Adam
Momentum参照小球在碗中滚动的物理规则进行移动,AdaGrad为参数的每个元素适当的调整更新步伐,Adam组合二者的优点,将二者进行融合
2.权重的初始值
*权重的初始值不能设置成一样的值
*权重的初始值对神经网络的学习至关重要
3.Batch Normalization
*Batch Normalization的算法:
Batch Norm的思路是调整各层的激活值分布使其拥有适当的广度,为此要向神经网络中插入对数据分布进行正规化的层,即Batch Norm层,具体而言,就是进行使数据分布的均值为0,方差为1的正规化

其中
 是一个微小值,防止出现除数等于0
是一个微小值,防止出现除数等于0接着,Batch Norm层会对正规化后的数据进行缩放和平移的变换

这里,
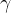 和
和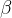 是参数,一开始为1和0,然后在通过学习调整到合适的值
是参数,一开始为1和0,然后在通过学习调整到合适的值*Batch Norm的计算图:

4.正则化
*机器学习的问题中,过拟合是一个很常见的问题,过拟合指的是只能拟合训练数据,但不能很好的拟合不包含在训练数据中的其他数据的状态
*过拟合发生的原因主要有两个:模型拥有大量参数,表现力强;训练数据少
*抑制过拟合的方法:
(1)权值衰减
权值衰减是一直以来经常被使用的一种抑制过拟合的方法,该方法通过在学习的过程中对大的权重进行惩罚来抑制过拟合,例如为损失函数加上权重的L2范数,如果将权重记为W,L2范数的权值衰减就是
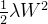
(2)Dropout
如果网络的模型变得很复杂,只用权值衰减则难以应对,在这种情况下,则经常使用Dropout方法

Dropout是一种在学习过程中随机删除神经元的方法,训练时随机选出隐藏的神经元,然后将其删除,被删除的神经元不再进行信号的传递,训练时每传递一次数据,就会随机选择要删除的神经元,测试时虽然会传递所有的神经元信号,但是对于各个神经元的输出,要乘上训练时的删除比例再输出
机器学习中经常使用集成学习,所谓集成学习,就是让多个模型单独进行学习,推理时再取多个模型的输出的平均值,用神经网络的语境来说,比如准备5个结构相同的网络分别进行学习,测试时,以这5个网络的输出的平均值作为答案。实验表明,通过进行集成学习,神经网络的识别精度可以提升好几个百分点。可以将Dropout理解为,通过在学习过程中随机删除神经元,从而每一次都让不同的模型进行学习,并且在推理时,通过对神经元的输出乘以删除比例,可以取得模型的平均值。也就是说,可以理解成Dropout将集成学习的效果通过一个网络实现了。
5.超参数的验证
*超参数是指,比如各层的神经元数量、batch大小、参数更新时的学习率或权值衰减等
*调整超参数时,必须使用超参数专用的确认数据,一般称为验证数据
*训练数据用于参数的学习;验证数据用于超参数的性能评估;最后使用测试数据验证泛化能力
*超参数的优化步骤:
步骤0:设定超参数的范围
步骤1:从设定的超参数范围中随机采样
步骤2:使用步骤1中采样到的超参数的值进行学习,通过验证数据评估识别精度
步骤3:重复步骤1和步骤2,根据识别精度的结果,缩小超参数的范围
-
相关阅读:
软件工程国考总结——选择题
ABC254 F - Rectangle GCD( 数据结构&&gcd)
价格战打响!阿里云服务器和腾讯云服务器价格对比
小白都不知道的互联网行业黑化大全
Vant可靠的移动端组件库
为什么 0.1+0.2 不等于 0.3
【JS】常用正则表达式
Helloworld 驱动模块加载
Mysql高级——日志
自己搭设开源密码管理工具 bitwarden
- 原文地址:https://blog.csdn.net/weixin_47687315/article/details/126890424