-
《基础知识》BOW(Bag-Of-Words)
《基础知识》BOW(Bag-Of-Words)
前提:信息检索特点:忽略文档中的单词顺序、语法和语句等要素核心:文档中的任意一个单词都是可以独立选择,不受文档语意影响举例:文档包含两个句子:
John likes to watch movies. Mary likes too.
John also likes to watch football games.
从上述两句话可以得到一个字典:
{“John”: 1, “likes”: 2, “to”: 3, “watch”: 4, “movies”: 5, “also”: 6, “football”: 7, “games”: 8, “Mary”: 9, “too”: 10}
该文档中一共包含10个词,每一个词都有唯一的索引与之对应,可以建立该文档中每一个句子的向量【向量长度为字典中词的个数】
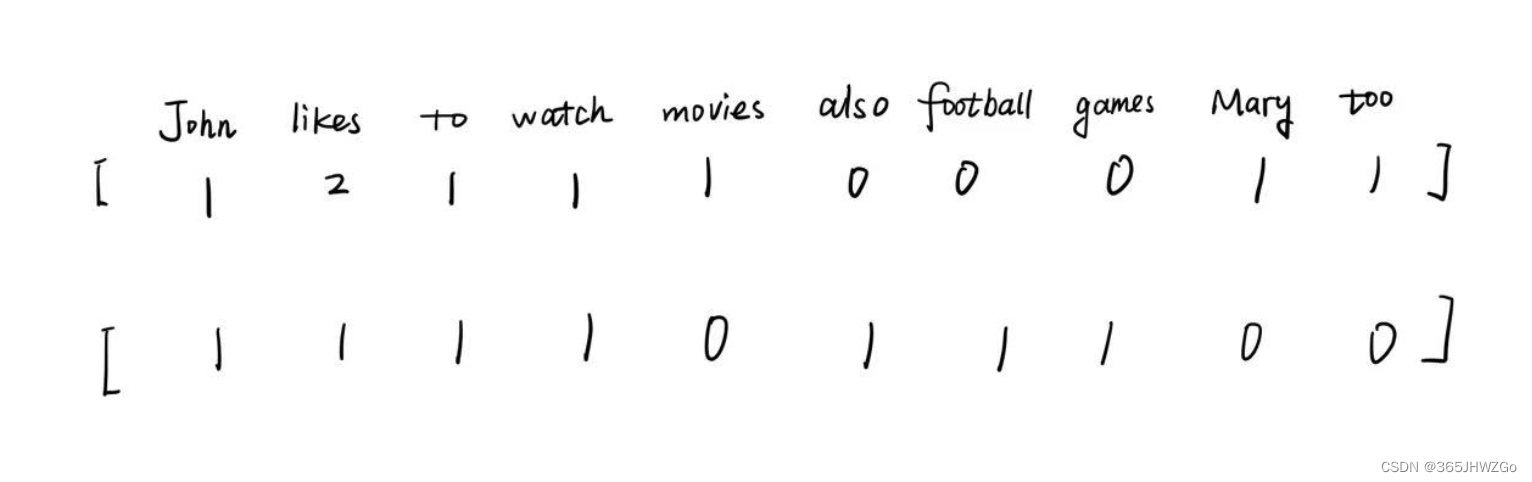
bow的作用就是记录了每一个句子中第i个单词在句子中出现的次数。
缺点:-
当词典中单词个数庞大时,会导致出现一个稀疏表示的向量。
-
这样表示出来的向量丢失了文档句子中原本含有的信息,如顺序信息。
-
不是所有的单词都用来建立词表:
(1)相似的词常用一个单词来表示,如walks、walking、walk,都统一用walk表示
(2)像一些常见的冠词a、the和an等,由于每一篇文档中都含有很高的频率,所以通常在建立词表时不被使用
-
-
相关阅读:
java计算机毕业设计交通非现场执法系统源码+mysql数据库+系统+lw文档+部署
数据血缘分析-Python代码的智能解析
【ZZULIOJ】1080: a+b(多实例测试3)(Java)
IDEA如何拉取gitee项目?
C++独立编译和命名空间
入门Echarts数据可视化:从基础到实践
《每日一题》NO.43:如何使用CG(clock gating) cell?
JAVA基础(四十四)——集合之Collection的Set接口
Jenkins+Docker+Gitee+SpringBoot自动化部署
Yolov5的类激活图
- 原文地址:https://blog.csdn.net/qq_44833392/article/details/126879230