-
ELK专栏之ES索引-04
ELK专栏之ES索引-04
索引Index入门
为什么我们要手动创建索引?
● 在生产上,我们需要自己手动建立索引和映射,是为了更好的管理索引,就像数据库的建表数据一样。
索引管理
创建索引
● 创建索引的语法:
PUT /index { "settings":{...}, "mappings":{ "properties":{ ... } }, "aliases":{ "default_index":{} } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
示例:
● 创建索引:
PUT /my_index { "settings": { "number_of_shards": 1, "number_of_replicas": 1 }, "mappings": { "properties": { "field1":{ "type": "text" }, "field2":{ "type": "text" } } }, "aliases": { "default_index": {} } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
插入数据:
PUT /my_index/_doc/1 { "field1":"java", "field2":"js" }- 1
- 2
- 3
- 4
- 5
查询数据:
GET /my_index/_doc/1- 1
GET /default_index/_doc/1- 1
查询索引
语法:查询索引:
GET /index- 1
语法:查询索引中的映射信息
GET /index/_mapping- 1
示例:
GET /my_index- 1
GET /my_index/_mapping- 1
GET /my_index/_settings- 1
修改索引
语法:
PUT /index/_settings { "index" : { "number_of_replicas" : 5 } }- 1
- 2
- 3
- 4
- 5
- 6
示例:修改副本分片数
PUT /my_index/_settings { "index" : { "number_of_replicas" : 5 } }- 1
- 2
- 3
- 4
- 5
- 6
删除索引
语法:删除索引
DELETE /index- 1
语法:删除多个索引
DELETE /index1,index2- 1
DELETE /index*- 1
语法:删除全部索引(危险)
DELETE /_all- 1
示例:删除索引
DELETE /book- 1
示例:删除多个索引
DELETE /book,my_index- 1
示例:
DELETE /book*- 1
示例:删除所有索引
DELETE /_all- 1
为了安全起见,防止恶意删除索引,删除的时候必须指定索引名,我们可以在elasticsearch.yml中配置action.destructive_requires_name: true。
定制分词器
默认分词器
● 分词器有三个组件,分别为:character filter,tokenizer和token filter。
● 默认的分词器是:standard 分词器。
● standard tokenizer:以单词边界进行切分。
● standard token filter:什么都不做。
● lowercase token filter:将所有字母都转换为小写。
● stop token filter(默认被禁用):移除停用词,比如a、the、it等等。
修改分词器的位置
● 启用english停用词token filter:
PUT /my_index { "settings": { "analysis": { "analyzer": { "es_std":{ "type":"standard", "stopwords":"_english_" } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
使用标准分词器测试分词:
GET /my_index/_analyze { "analyzer": "standard", "text": "a dog is in the house" }- 1
- 2
- 3
- 4
- 5

使用english停用词测试分词:
GET /my_index/_analyze { "analyzer": "es_std", "text":"a dog is in the house" }- 1
- 2
- 3
- 4
- 5

定制自己的分词器
● 定制自己的分词器:
PUT /my_index { "settings": { "analysis": { "char_filter": { //&替换为and "&_to_and": { "type": "mapping", "mappings": ["&=> and"] } }, "filter": { //停用词--遇到这些词语会忽略分词 "my_stopwords": { "type": "stop", "stopwords": ["the", "a"] } }, "analyzer": { //自定义分词器 "my_analyzer": { "type": "custom", //字符过滤器 "char_filter": ["html_strip", "&_to_and"], //以单词边界进行切分 "tokenizer": "standard", //再进行过滤 "filter": ["lowercase", "my_stopwords"] } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
测试自定义分词器:
GET /my_index/_analyze { "analyzer": "my_analyzer", "text": "tom&jerry are a friend in the house, , HAHA!!" }- 1
- 2
- 3
- 4
- 5

设置字段使用自定义分词器:
PUT /my_index/_mapping/ { "properties": { "content": { "type": "text", "analyzer": "my_analyzer" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
type底层结构及弃用原因
type是什么?
● type是一个Index中用来区分类似的数据的。这些类似的数据,可能有不同的fields,而且有不同的属性来控制索引和分词器的建立。
● field的value,在底层的Lucene中建立索引的时候,全都是opaque bytes类型,是不区分类型的。
● Lucene是没有type的概念的,在document(文档)中,实际上是将type作为document(文档)的field来存储的,即_type,ES通过_type来进行type的过滤和筛选。
ES中不同的type存储机制
● 一个Index中的多个type,实际上是放在一起存储的,因此同一个Index下,不能有多个type重名,因为那样是无法处理的。
● 比如:创建索引:
{ "goods": { "mappings": { "electronic_goods": { "properties": { "name": { "type": "string", }, "price": { "type": "double" }, "service_period": { "type": "string" } } }, "fresh_goods": { "properties": { "name": { "type": "string", }, "price": { "type": "double" }, "eat_period": { "type": "string" } } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
插入数据:
PUT /goods/electronic_goods/1 { "name": "小米空调", "price": 1999.0, "service_period": "one year" }- 1
- 2
- 3
- 4
- 5
- 6
PUT /goods/fresh_goods/1 { "name": "澳洲龙虾", "price": 199.0, "eat_period": "one week" }- 1
- 2
- 3
- 4
- 5
- 6
ES文档在底层的存储是这个样子的:
{ "goods": { "mappings": { "_type": { "type": "text", "index": "false" }, "name": { "type": "text" } "price": { "type": "double" } "service_period": { "type": "text" }, "eat_period": { "type": "text" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
那么插入的数据在底层的数据存储格式:
{ "_type": "electronic_goods", "name": "小米空调", "price": 1999.0, "service_period": "one year", "eat_period": "" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
{ "_type": "fresh_goods", "name": "澳洲龙虾", "price": 199.0, "service_period": "", "eat_period": "one week" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
type弃用的原因
● 同一个索引下,不同type的数据存储其他type的field的大量空值,会造成资源浪费。
● 所以,不同类型的数据,要放在不同的索引中。
● ES9中,将彻底删除type。
定制动态映射(dynamic mapping)
定制动态映射(dynamic mapping)策略
语法:
PUT /index { "settings": {...}, "mappings": { "dynamic": "xxx", "properties": { "filed1": { "type": "" }, "filed2": { "type": "", "dynamic": "xxx" }, ... } }, "aliases": { "default_index": {} } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
dynamic:
- true,遇到陌生字段,就进行dynamic mapping,会自动帮助我们创建映射。
- false:新检测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但仍将出现在返回的源字段中。这些字段不会添加到映射中,必须显示的添加新字段。
- strict:遇到陌生字段,就报错。
● 示例:
● 创建索引
PUT /my_index { "mappings": { "dynamic": "strict", "properties": { "title": { "type": "text" }, "address": { "type": "object", "dynamic": "true" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
测试插入数据
PUT /my_index/_doc/1 { "title": "my article", "content": "this is my article", "address": { "province": "guangdong", "city": "guangzhou" } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

如果是false情况下,content陌生字段不会被索引,我们在进行全局搜索时,不会搜索到content字段,但是如果搜索别的字段,搜索到该条记录时,还是会携带返回content字段的。
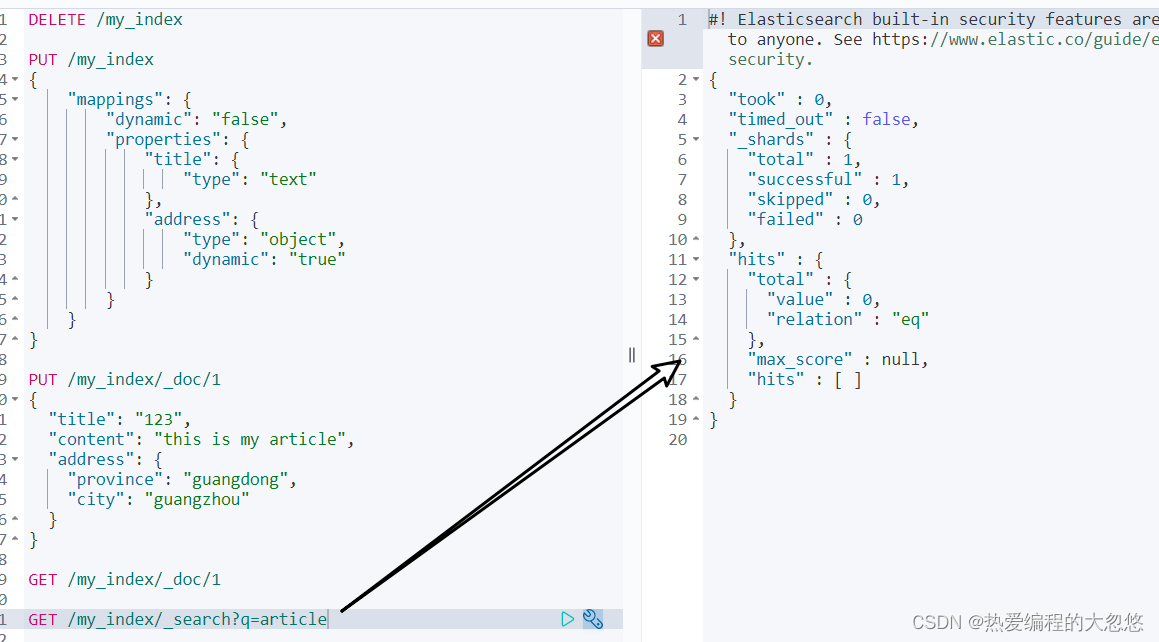
查询my_index的底层mapping映射,也可以发现其中并没有为content字段建立映射。GET /my_index/_mapping- 1
{ "my_index" : { "mappings" : { "dynamic" : "false", "properties" : { "address" : { "dynamic" : "true", "properties" : { "city" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "province" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } }, "title" : { "type" : "text" } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
自定义动态映射(dynamic mapping)策略
- ES会根据传入的值,自动推断类型。
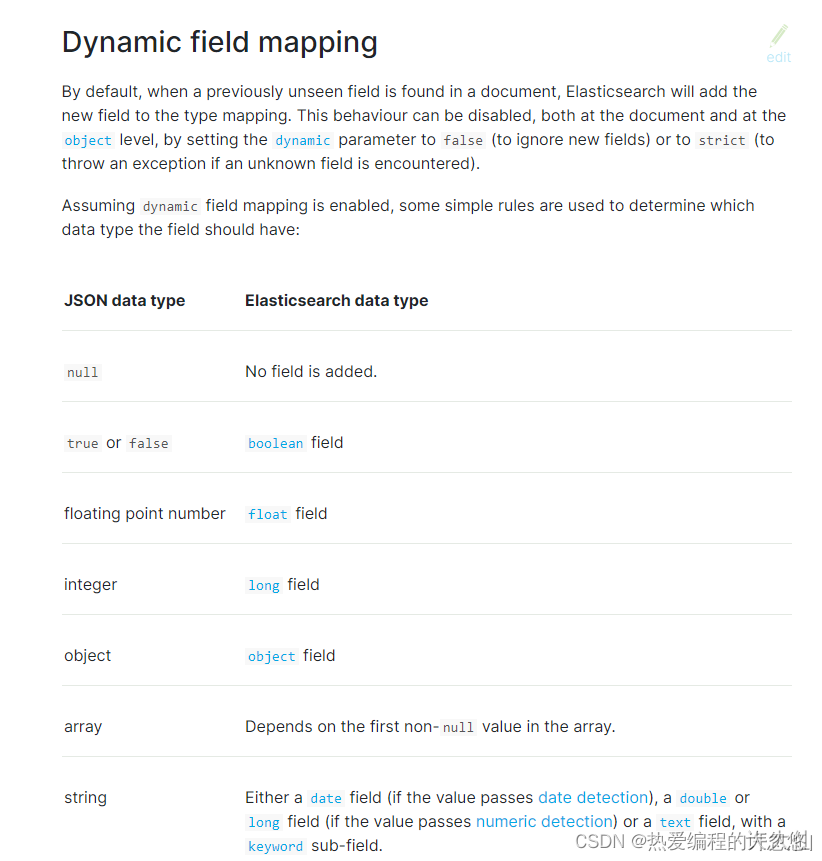
● 日期探测(Date Detection):默认会按照一定格式识别date,比如yyyy-MM-dd,但是如果某个field先过来一个"2019-11-11"的值,就会自动被dynamic mapping识别成date,后面如果在过来一个"hello world"之类的值,就会报错。可以手动关闭某个type的date detection,如果有需要,自己手动指定某个field为date类型。
● 语法:
PUT /index { "mappings": { "date_detection": false, "properties": { "filed1": { "type": "" }, "filed2": { "type": "" }, ... } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
示例:关闭日期探测
PUT /my_index { "mappings": { "date_detection": false, "properties": { "title": { "type": "text" }, "address": { "type": "object", "dynamic": "true" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
测试插入数据:
PUT /my_index/_doc/1 { "title": "my article", "content": "this is my article", "address": { "province": "guangdong", "city": "guangzhou" }, "post_date":"2019-09-10" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
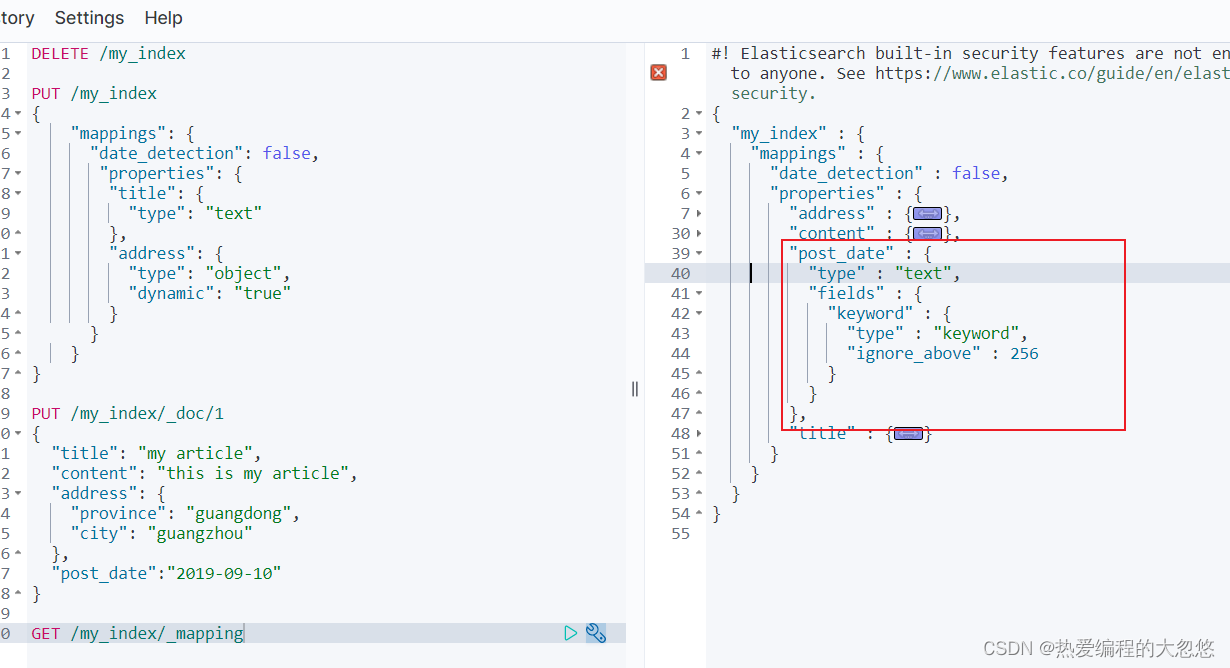
● 自定义日期格式:dynamic_date_formats可以定制自己的格式。● 语法:
PUT /index { "mappings": { "dynamic_date_formats": ["MM/dd/yyyy"], "properties": { "filed1": { "type": "" }, "filed2": { "type": "" }, ... } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
示例:自定义日期格式
PUT /my_index { "mappings": { "dynamic_date_formats": ["MM/dd/yyyy"] } }- 1
- 2
- 3
- 4
- 5
- 6
测试插入数据:
PUT /my_index/_doc/1 { "create_date": "09/25/2019" }- 1
- 2
- 3
- 4

● 数字探测(Numeric Detection):虽然JSON支持本机浮点和整数数据类型,但是某些应用程序或语言有时候可能将数字呈现为字符串。通常正确的解决方案是显示的映射这些字段,那么就可以启用数字检测(默认情况下禁用)来自动完成这些操作。
● 语法:
PUT /index { "mappings": { "numeric_detection": true, "properties": { "filed1": { "type": "" }, "filed2": { "type": "" }, ... } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
示例:开启数字探测
PUT /my_index { "mappings": { "numeric_detection": true } }- 1
- 2
- 3
- 4
- 5
- 6
测试插入数据:
PUT /my_index/_doc/1 { "my_float": "1.0", "my_integer": "1" }- 1
- 2
- 3
- 4
- 5
定义自己的dynamic mapping template(动态映射模板)
● 动态映射模板允许我们自定义映射,这些映射可以应用到动态添加的字段。
● 语法:
PUT index { "mappings": { "dynamic_templates": [ { "template_name": { ... match conditions ... "mapping": { ... } } }, ... ] } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- template_name:模板名称可以是任何字符串。
- match conditions:匹配条件,包括match_mapping_type、match、match_pattern、unmatch、path_match、path_unmatch。
- mapping:匹配字段应该使用的映射。
● 示例:
● 定制自己的映射模块:
PUT /my_index { "mappings": { "dynamic_templates": [ { "en": { "match": "*_en", "match_mapping_type": "string", "mapping": { "type": "text", "analyzer": "english" } } } ] } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
插入数据:
PUT /my_index/_doc/1 { "title": "this is my first article" }- 1
- 2
- 3
- 4
PUT /my_index/_doc/2 { "title_en": "this is my first article" }- 1
- 2
- 3
- 4
搜索:
GET /my_index/_search?q=article- 1
GET /my_index/_search?q=is- 1
title没有匹配到任何的动态模块,默认就是standard分词器,不会过滤掉停用词,像is会进入到倒排索引,用is来搜索是可以搜索到的。
title_en匹配到了动态模块,就是english分词器,会过滤掉停用词,is这种停用词会被过滤掉,用is来搜索是搜索不到的。
模板写法:
PUT my_index { "mappings": { "dynamic_templates": [ { "integers": { "match_mapping_type": "long", "mapping": { "type": "integer" } } }, { "strings": { "match_mapping_type": "string", "mapping": { "type": "text", "fields": { "raw": { "type": "keyword", "ignore_above": 256 } } } } } ] } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
模板参数:
"match": "long_*",- 1
"unmatch": "*_text",- 1
"match_mapping_type": "string",- 1
"path_match": "name.*",- 1
"path_unmatch": "*.middle",- 1
"match_pattern": "regex",- 1
"match": "^profit_\d+$"- 1
● 动态模块的应用场景:
● ①结构化搜索:
○ 默认情况下,ElasticSearch将字符串字段映射为带有子关键字字段的文本字段。但是,如果只对结构化内容进行索引,而对全文检索不感兴趣,则可以仅将字段映射为关键字。注意:为了能够搜索这些字段,必须搜索索引的时候用完全相同的值。
{ "strings_as_keywords": { "match_mapping_type": "string", "mapping": { "type": "keyword" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
● ②仅搜索:
○ 如果只关系字符串字段的全文检索,并且不打算对字符串字段进行聚合、排序或精确搜索,可以将其映射为文本字段。
{ "strings_as_text": { "match_mapping_type": "string", "mapping": { "type": "text" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
● ③norms :不关心评分。
○ norms是指标时间的评分因素。如果不关心评分,比如:不按评分对文档进行排序,则可以在索引中禁用这些评分因子的存储以便节省一些空间。
{ "strings_as_keywords": { "match_mapping_type": "string", "mapping": { "type": "text", "norms": false, "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
零停机重建索引
● 场景:index被确定以后,一个field的设置是不能被修改的,如果要修改一个field,应该重新按照新的mapping,建立新的index,并将数据批量查询出来,重新用bulk api写入到index中。
● 批量查询的时候,建议采用scroll api,并且采用多线程并发的方式来重建索引数据,每次scroll就查询执行日期的一段数据,交给一个线程即可。
示例:
①一开始,依据动态映射(dynamic mapping)插入数据,但是不小心有些数据是诸如"2019-11-11"之类的日期
格式,所以会被映射为date类型,实际上它是string类型。PUT /my_index/_doc/1 { "title": "2019-11-11" }- 1
- 2
- 3
- 4
PUT /my_index/_doc/2 { "title": "2019-11-12" }- 1
- 2
- 3
- 4
②当后期向索引中插入string类型的title值的时候,会报错。
PUT /my_index/_doc/3 { "title": "this is my first article" }- 1
- 2
- 3
- 4
报错:
{ "error" : { "root_cause" : [ { "type" : "mapper_parsing_exception", "reason" : "failed to parse field [title] of type [date] in document with id '3'. Preview of field's value: 'this is my first article'" } ], "type" : "mapper_parsing_exception", "reason" : "failed to parse field [title] of type [date] in document with id '3'. Preview of field's value: 'this is my first article'", "caused_by" : { "type" : "illegal_argument_exception", "reason" : "failed to parse date field [this is my first article] with format [strict_date_optional_time||epoch_millis]", "caused_by" : { "type" : "date_time_parse_exception", "reason" : "Failed to parse with all enclosed parsers" } } }, "status" : 400 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
③此时,想修改title的类型,是不可能的:
PUT /my_index/_mapping { "properties":{ "title":{ "type":"text" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
报错:
{ "error" : { "root_cause" : [ { "type" : "illegal_argument_exception", "reason" : "mapper [title] cannot be changed from type [date] to [text]" } ], "type" : "illegal_argument_exception", "reason" : "mapper [title] cannot be changed from type [date] to [text]" }, "status" : 400 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
④此时,唯一的办法,就是重建索引,即重新建立一个新的索引,将旧索引的数据查询出来,再导入新的索引。
⑤如果说就索引的名字是old_index,新索引的名字是new_index。终端Java应用已经在使用old_index操作了,难道我们需要停止Java应用,修改使用的index为new_index,再重新启动Java应用?这个过程中,必然会导致Java应用停机,可用性也降低。
⑥给索引起一个别名,Java应用指向这个别名,那么此时Java应用指向的是旧索引。
PUT /my_index/_alias/prod_index- 1
⑦创建新的Index,调整title的类型为string:
PUT /my_index_new { "mappings": { "properties": { "title": { "type": "text" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
⑧使用scroll api将数据批量查询出来:
GET /my_index/_search?scroll=1m { "query": { "match_all": {} }, "size": 1 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
返回:
{ "_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFnRRN1doOHVhUktXQllGZGlHRjN3bFEAAAAAAAANOhZzenoyWWlMd1I2T1kyMWtzMDExYVl3", "took" : 0, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "my_index", "_type" : "_doc", "_id" : "1", "_score" : 1.0, "_source" : { "title" : "2019-11-11" } } ] } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
⑨采用bulk api将scoll查出来的一批数据,批量写入新索引:
POST /_bulk { "index": { "_index": "my_index_new", "_id": "1" }} { "title": "2019-11-11" }- 1
- 2
- 3
⑩反复循环8~9,查询一批批数据出现,采用bulk api将每一批数据批量写入到新索引。
⑪将prod_index这个alias切换到my_index_new上,Java应用会直接通过index别名使用新的索引中的数据,Java应用程序不需要停机,高可用。
POST /_aliases { "actions": [ { "remove": { "index": "my_index", "alias": "prod_index" }}, { "add": { "index": "my_index_new", "alias": "prod_index" }} ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
⑫直接通过pro_index别名查询:
GET /prod_index/_search- 1
生产实践,基于alias对client透明切换index
对索引进行别名操作:
PUT /my_index_v1/_alias/my_index- 1
● Java客户端对别名(my_index)进行操作。
● 重建索引后,切换v1到v2:
POST /_aliases { "actions": [ { "remove": { "index": "my_index_v1", "alias": "my_index" }}, { "add": { "index": "my_index_v2", "alias": "my_index" }} ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
相关阅读:
Spark SQL
护网攻防演练-内网横向移动总结
【I2C】熟悉I2C的传输时序。根据I2C的时序图,标出每段时序对应的含义
常见的数据结构及应用
模型可视化工具Netron手把手教学
初识Java
2011-2019年全国30省绿色经济发展指数和子指数数据
Web Vue VI
wxpython使用中出现的内存泄露问题
踩着节日的小尾巴
- 原文地址:https://blog.csdn.net/m0_53157173/article/details/126862543
