-
机器学习中常用的分类算法总结
分类算法
分类算法和回归算法是对真实世界不同建模的方法。分类模型是认为模型的输出是离散的,例如大自然的生物被划分为不同的种类,是离散的。回归模型的输出是连续的,例如人的身高变化过程是一个连续过程,而不是离散的。
因此,在实际建模过程时,采用分类模型还是回归模型,取决于你对任务(真实世界)的分析和理解。
1、 常用分类算法的优缺点?
接下来我们介绍常用分类算法的优缺点,如表2-1所示。
表2-1 常用分类算法的优缺点
算法 优点 缺点 Bayes 贝叶斯分类法 1)所需估计的参数少,对于缺失数据不敏感。
2)有着坚实的数学基础,以及稳定的分类效率。1)需要假设属性之间相互独立,这往往并不成立。(喜欢吃番茄、鸡蛋,却不喜欢吃番茄炒蛋)。
2)需要知道先验概率。
3)分类决策存在错误率。Decision Tree决策树 1)不需要任何领域知识或参数假设。
2)适合高维数据。
3)简单易于理解。
4)短时间内处理大量数据,得到可行且效果较好的结果。
5)能够同时处理数据型和常规性属性。1)对于各类别样本数量不一致数据,信息增益偏向于那些具有更多数值的特征。
2)易于过拟合。
3)忽略属性之间的相关性。
4)不支持在线学习。SVM支持向量机 1)可以解决小样本下机器学习的问题。
2)提高泛化性能。
3)可以解决高维、非线性问题。超高维文本分类仍受欢迎。
4)避免神经网络结构选择和局部极小的问题。1)对缺失数据敏感。
2)内存消耗大,难以解释。
3)运行和调参略烦人。KNN K近邻 1)思想简单,理论成熟,既可以用来做分类也可以用来做回归;
2)可用于非线性分类;
3)训练时间复杂度为O(n);
4)准确度高,对数据没有假设,对outlier不敏感;1)计算量太大。
2)对于样本分类不均衡的问题,会产生误判。
3)需要大量的内存。
4)输出的可解释性不强。Logistic Regression逻辑回归 1)速度快。
2)简单易于理解,直接看到各个特征的权重。
3)能容易地更新模型吸收新的数据。
4)如果想要一个概率框架,动态调整分类阀值。特征处理复杂。需要归一化和较多的特征工程。 Neural Network 神经网络 1)分类准确率高。
2)并行处理能力强。
3)分布式存储和学习能力强。
4)鲁棒性较强,不易受噪声影响。1)需要大量参数(网络拓扑、阀值、阈值)。
2)结果难以解释。
3)训练时间过长。Adaboosting 1)adaboost是一种有很高精度的分类器。
2)可以使用各种方法构建子分类器,Adaboost算法提供的是框架。
3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单。
4)简单,不用做特征筛选。
5)不用担心overfitting。对outlier比较敏感 2、分类算法的评估方法
分类评估方法主要功能是用来评估分类算法的好坏,而评估一个分类器算法的好坏又包括许多项指标。了解各种评估方法,在实际应用中选择正确的评估方法是十分重要的。
-
几个常用术语 这里首先介绍几个常见的模型评价术语,现在假设我们的分类目标只有两类,计为正例(positive)和负例(negative)分别是:
- True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数;
- False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
- False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
- True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
四个术语的混淆矩阵
-

表是这四个术语的混淆矩阵,做以下说明:
1)P=TP+FN表示实际为正例的样本个数。
2)True、False描述的是分类器是否判断正确。
3)Positive、Negative是分类器的分类结果,如果正例计为1、负例计为-1,即positive=1、negative=-1。用1表示True,-1表示False,那么实际的类标=TF*PN,TF为true或false,PN为positive或negative。
4)例如True positives(TP)的实际类标=1*1=1为正例,False positives(FP)的实际类标=(-1)*1=-1为负例,False negatives(FN)的实际类标=(-1)*(-1)=1为正例,True negatives(TN)的实际类标=1*(-1)=-1为负例。
-
评价指标
-
正确率(accuracy) 正确率是我们最常见的评价指标,accuracy = (TP+TN)/(P+N),正确率是被分对的样本数在所有样本数中的占比,通常来说,正确率越高,分类器越好。
-
错误率(error rate) 错误率则与正确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(P+N),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate。
-
灵敏度(sensitivity) sensitivity = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。
-
特异性(specificity) specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。
-
精度(precision) precision=TP/(TP+FP),精度是精确性的度量,表示被分为正例的示例中实际为正例的比例。
-
召回率(recall) 召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitivity,可以看到召回率与灵敏度是一样的。
-
其他评价指标 计算速度:分类器训练和预测需要的时间; 鲁棒性:处理缺失值和异常值的能力; 可扩展性:处理大数据集的能力; 可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。
-
精度和召回率反映了分类器分类性能的两个方面。如果综合考虑查准率与查全率,可以得到新的评价指标F1-score,也称为综合分类率:$F1=\frac{2 \times precision \times recall}{precision + recall}$。
为了综合多个类别的分类情况,评测系统整体性能,经常采用的还有微平均F1(micro-averaging)和宏平均F1(macro-averaging )两种指标。
(1)宏平均F1与微平均F1是以两种不同的平均方式求的全局F1指标。
(2)宏平均F1的计算方法先对每个类别单独计算F1值,再取这些F1值的算术平均值作为全局指标。
(3)微平均F1的计算方法是先累加计算各个类别的a、b、c、d的值,再由这些值求出F1值。
(4)由两种平均F1的计算方式不难看出,宏平均F1平等对待每一个类别,所以它的值主要受到稀有类别的影响,而微平均F1平等考虑文档集中的每一个文档,所以它的值受到常见类别的影响比较大。
-
-
ROC曲线和PR曲线
-
如图,ROC曲线是(Receiver Operating Characteristic Curve,受试者工作特征曲线)的简称,是以灵敏度(真阳性率)为纵坐标,以1减去特异性(假阳性率)为横坐标绘制的性能评价曲线。可以将不同模型对同一数据集的ROC曲线绘制在同一笛卡尔坐标系中,ROC曲线越靠近左上角,说明其对应模型越可靠。也可以通过ROC曲线下面的面积(Area Under Curve, AUC)来评价模型,AUC越大,模型越可靠。
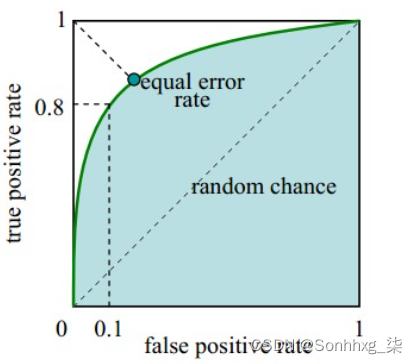
ROC曲线
PR曲线是Precision Recall Curve的简称,描述的是precision和recall之间的关系,以recall为横坐标,precision为纵坐标绘制的曲线。该曲线的所对应的面积AUC实际上是目标检测中常用的评价指标平均精度(Average Precision, AP)。AP越高,说明模型性能越好。
3 、正确率能很好的评估分类算法吗
不同算法有不同特点,在不同数据集上有不同的表现效果,根据特定的任务选择不同的算法。如何评价分类算法的好坏,要做具体任务具体分析。对于决策树,主要用正确率去评估,但是其他算法,只用正确率能很好的评估吗? 答案是否定的。 正确率确实是一个很直观很好的评价指标,但是有时候正确率高并不能完全代表一个算法就好。比如对某个地区进行地震预测,地震分类属性分为0:不发生地震、1发生地震。我们都知道,不发生的概率是极大的,对于分类器而言,如果分类器不加思考,对每一个测试样例的类别都划分为0,达到99%的正确率,但是,问题来了,如果真的发生地震时,这个分类器毫无察觉,那带来的后果将是巨大的。很显然,99%正确率的分类器并不是我们想要的。出现这种现象的原因主要是数据分布不均衡,类别为1的数据太少,错分了类别1但达到了很高的正确率缺忽视了研究者本身最为关注的情况。
4 、什么样的分类器是最好的
对某一个任务,某个具体的分类器不可能同时满足或提高所有上面介绍的指标。 如果一个分类器能正确分对所有的实例,那么各项指标都已经达到最优,但这样的分类器往往不存在。比如之前说的地震预测,既然不能百分百预测地震的发生,但实际情况中能容忍一定程度的误报。假设在1000次预测中,共有5次预测发生了地震,真实情况中有一次发生了地震,其他4次则为误报。正确率由原来的999/1000=99.9下降为996/1000=99.6。召回率由0/1=0%上升为1/1=100%。对此解释为,虽然预测失误了4次,但真的地震发生前,分类器能预测对,没有错过,这样的分类器实际意义更为重大,正是我们想要的。在这种情况下,在一定正确率前提下,要求分类器的召回率尽量高。
-
-
相关阅读:
人工智能产业应用--具身智能
Python数据分析学习路线
数据结构(单链表)
HTML 对象
如何优雅的写 Controller 层代码?
SOLIDWORKS功能布局实用技巧之保存实体技术
PEX装机
[Linux]----文件操作(复习C语言+文件描述符)
【数据结构与算法】环形队列的介绍、用数组实现环形数组
AI全流程开发难题破解之钥
- 原文地址:https://blog.csdn.net/sikh_0529/article/details/126883792