-
如何做一场高质量故障复盘
大家都知道测试是不可穷尽的,有时候遇到项目时间紧、测试时间被压缩,就很容易产生业务场景漏测。如果漏侧场景引起线上故障,是一件非常可怕的事情。前事不忘,后事之师。那么,我们如何对线上故障进行复盘,并有效避免重蹈覆辙呢?今天就给大家分享一下这方面的经验,本文可以作为故障分析的范式,大家可以按照这个模式来做。
有相关经验的同学应该晓得,参与同组或者兄弟团队的线上故障复盘会议,对于不熟悉这块业务的同学来说,作为故障分享者,做好一场高质量故障分析的难点就是如何给“小白”讲懂业务,讲懂根因,这样才能让大家给你一些建议。
下面切入正题,大家可以参考下图,一场高质量故障分析可以采用下面的步骤。
我们以《B站宕机事故复盘》为案例,可以对这个线上故障重新进行分析。
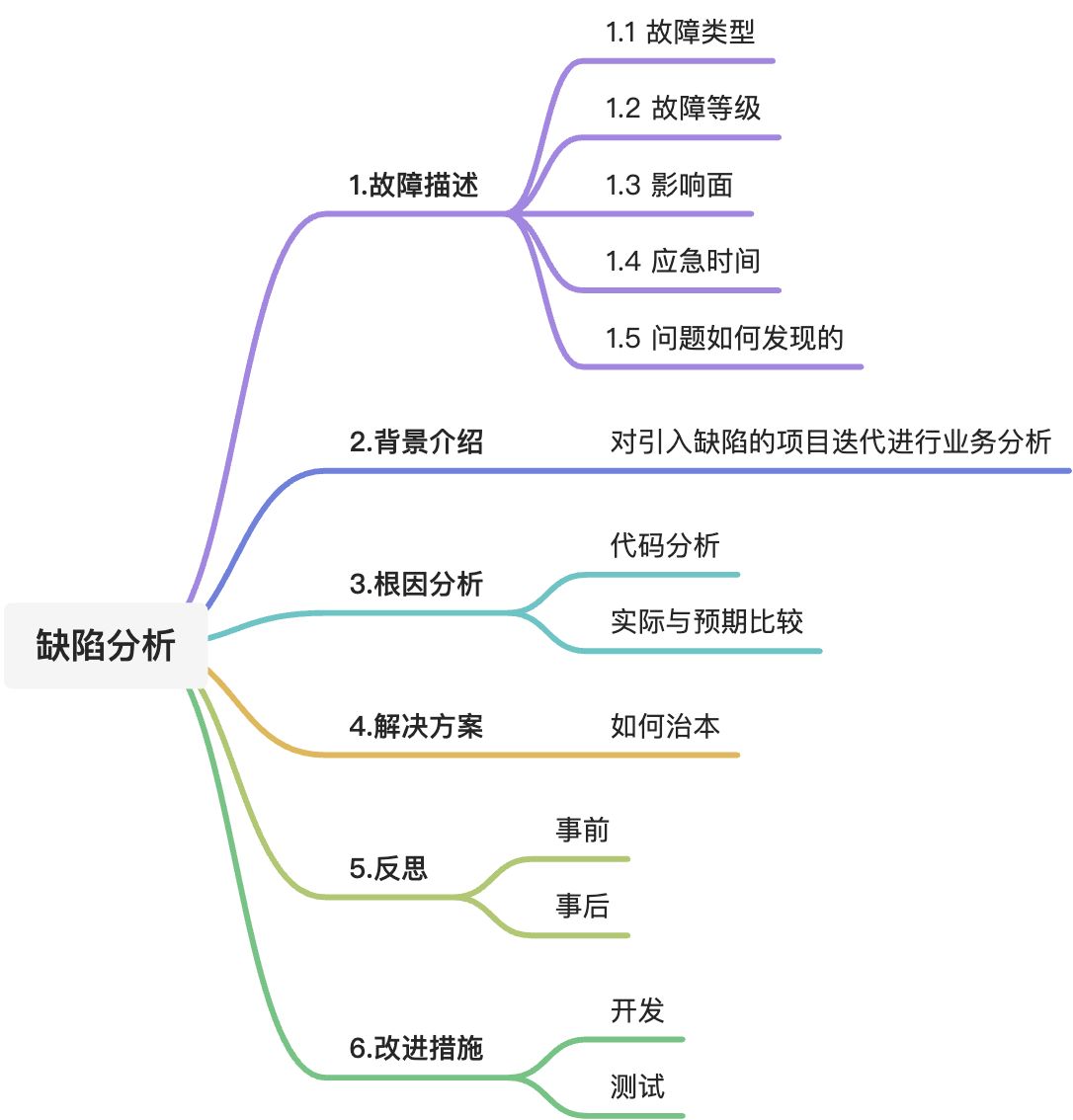
1.故障描述

1.1 故障类型
故障类型可以分为 1、代码错误 2、设计缺陷 3、性能问题 4、配置相关 5、安全相关 等
1.2 故障等级
一般决定故障等级的因素就是对公司核心业务的影响程度,例如本司是做支付的,那么核心业务就是资金的流动,等级可以根据资金损失的多少来制定(当然还会结合其他因素综合评定例如客诉等)。B站的缺陷等级应该和我司的有所不同,我也在网上Google到其故障等级,如下图:

高危漏洞 毫无疑问应该是P0故障了。
1.3 影响面
这个就是说这个故障影响了多少在线用户使用体验,导致了多少资金上面的损失。
这个一般公司会有各种业务指标的大盘,会根据故障发生的这段时间统计出来影响到的流量。(本司的话就是交易量、用户量、资金金额等)
1.4 应急时间
可以理解为故障止损时间,即从开始处理故障到故障处理完成的时间。


1.5 问题如何发现的
首次发现是通过业务告警(系统具备业务告警能力是非常重要的),其次是客诉。
 2.背景介绍
2.背景介绍
这块建议把缺陷引入的迭代与上个迭代进行业务对比来说明。例如这个缺陷引入前的功能是怎样的,然后缺陷引入的迭代是业务是怎样的。通过对比可以分析但业务影响点。
3.根因分析


对于互联网产品来说,问题根源基本上是代码逻辑的问题。这块的分析重点肯定就是代码逻辑,可以重点分析问题代码引入前后两个线上版本的差异。
4.解决方案

应急策略一般是临时打补丁(治标不治本),而解决方案则是治本的。
5.反思
反思是故障分析的核心,可以从 事前事后 出发。以B站这个问题为例,它主要分析故障发生后的一些反思。但我认为二者同等重要。
事前
- 当时测试这块功能的用例是怎样的?用例覆盖的业务全面吗?
- 为什么当时测试没发现呢?(线上为何没发现。。)
事后
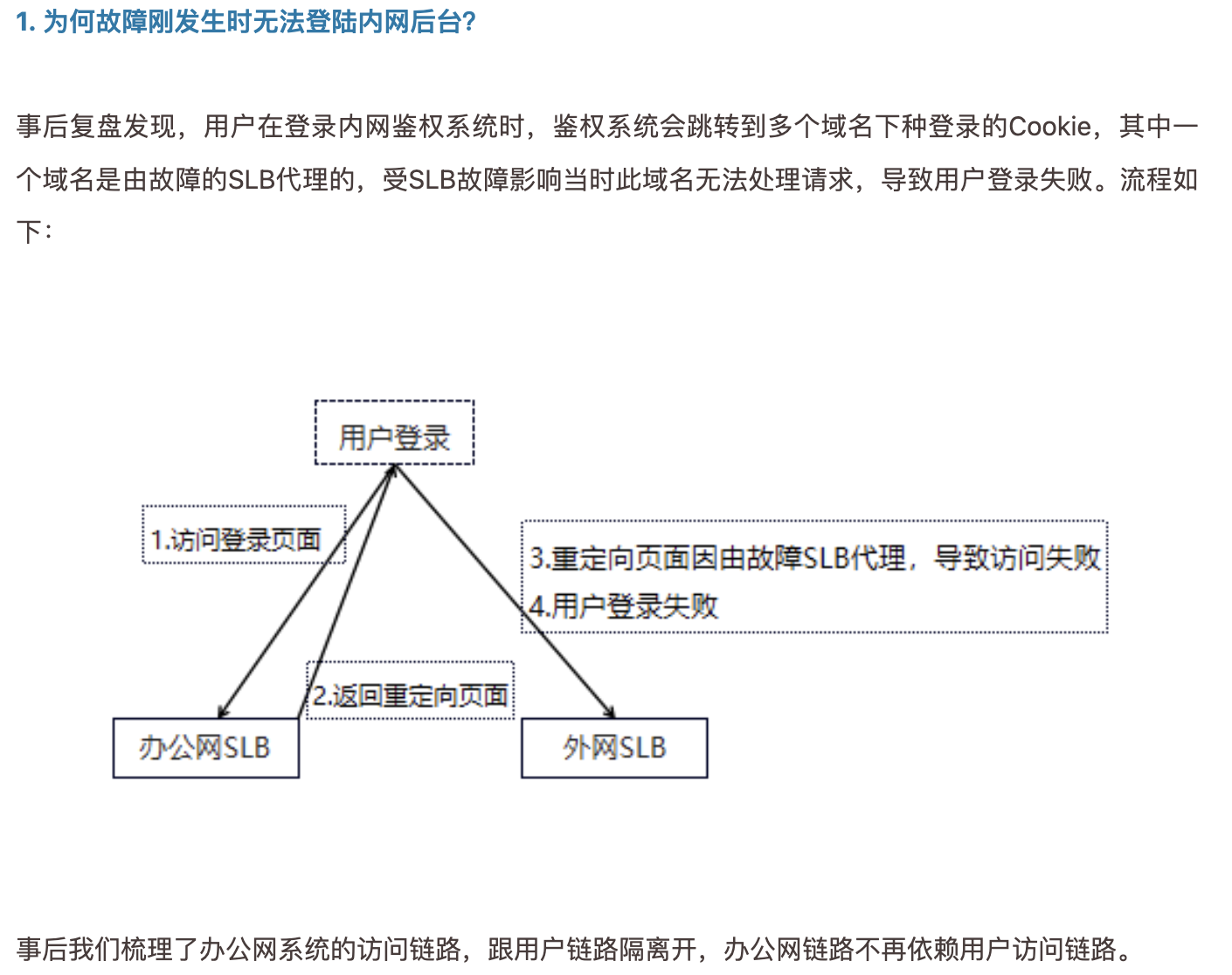
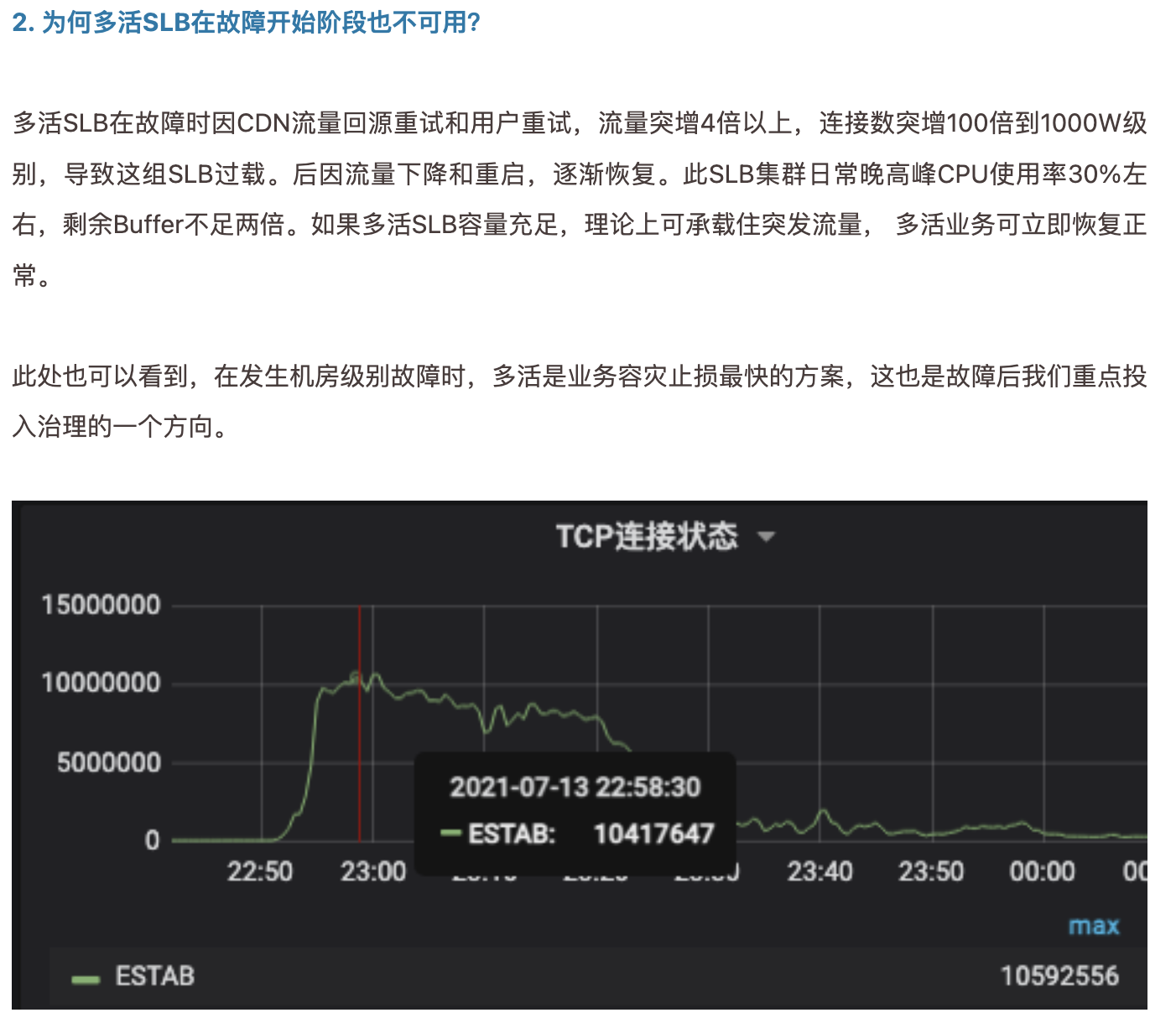

6.改进措施
首先明白一点,线上问题的锅不能只让测试来背(不容置疑,很多小公司的作风就是这样的,测试就是背锅侠),改进措施也需要从开发、测试的角度出发。


-
相关阅读:
报修工单系统如何提升维修维保工作效率?
MAXScript实现简单的碰撞检测教程
一个程序员的职业生涯到底该怎么规划?
android studio项目实例-基于Uniapp+Springboot实现的患者服药提醒APP
ts文件引入外部资源报错问题
[第七届蓝帽杯全国大学生网络安全技能大赛 蓝帽杯 2023]——Web方向部分题 详细Writeup
【阿卡乐谱】【日常分享】超级强大的简谱-大海啊,故乡
NLP模型(三)——FastText介绍
【开源】SpringBoot框架开发房屋出售出租系统
[翻译].NET 8 的原生AOT及高性能Web开发中的应用[附性能测试结果]
- 原文地址:https://blog.csdn.net/csd11311/article/details/126878764