-
SQL使用场景解决一对多查询、分页、复杂排名等问题之ROW_NUMBER、DENSE_RANK、RANK用法
期望通过每一次分享,让技术的门槛变低,落地更容易。 —— around
目录
- 1.解决什么问题
- 2.函数介绍及基本语法
- 3.函数总结
- 4.针对性复杂场景应用
前言
昨日同事有个列表查询无法搞定,改了半天一直有BUG,也尝试用了Mybatis的一对多查询依然可能导致分页结果集丢失,遂找到我这,当时正好在写前台页面,简单了解了一下业务需求,提供了sql,总结有了本文。
正文
1.解决什么问题
- 一对多数据列表分页查询,既有父表过滤条件,也有子表过滤条件,导致每次分页结果集可能小于每页最大条数
- 结果集涉及排名问题,甚至只取指定排名,甚至排名需要影响断号
- 结果集涉及多个维度和业务特殊情况进行数据分组筛选
2.函数介绍及基本语法
ROW_NUMBER、DENSE_RANK、RANK三个函数基础语法都一样,后接over(),详细语法示例如下:ROW_NUMBER() OVER(ORDER BY emergency_sign asc, update_time desc) DENSE_RANK() OVER(ORDER BY emergency_sign asc, update_time desc) RANK() OVER (ORDER BY emergency_sign asc, update_time desc) ROW_NUMBER() OVER(partition by userId ORDER BY emergency_sign asc, update_time desc) DENSE_RANK() OVER(partition by userId ORDER BY emergency_sign asc, update_time desc) RANK() OVER (partition by userId ORDER BY emergency_sign asc, update_time desc) #over内可选参数 partition by:表示参与分组的列,同正常sql语法 order by:表示参与排序的列,同正常sql语法 上述over内接的列,都针对自己需要参与排序的数据做排名,也就是说只有参与排名的字段才往里头加,不然别影响你的排名结果序号- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3.函数总结
一图说明三个函数之间的直接情况,三列按顺序为
ROW_NUMBER、DENSE_RANK、RANK:- 灰色:排序号不中断
- 红色:并列排序号出现
- 绿色:较上一个排序号,是否断号
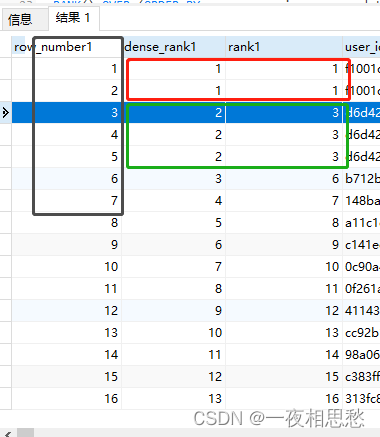
- ROW_NUMBER
对每条结果集产生唯一性编号,不可能重复- 1
- DENSE_RANK
涉及排名,支持并列排名,排序号“不中断”- 1
- RANK
涉及排名,支持并列排名,排序号“中断”- 1
4.针对性场景应用
就不以demo来显示效果了,文字说明博主也省点事,大家来搜解决方案,自己的问题就是最好的例子,我就不举例了。
4.1 一对多数据分页
场景:分页列表查询数据,每页20条,sql为一对多查询,且过滤条件既有父表也有子表字段,可能导致分页结果集受分页条数影响最终查出来的数据小于每页要求的20条
解决方案:
- 1.删除末尾limit语法分页
- 2.一对多sql查询中加入DENSE_RANK函数产生排序号,over内接一个order指明排序即可
- 3.将limit分页语法以where语句实现
简单示例:
select * from ( select DENSE_RANK() OVER(ORDER BY t1.emergency_sign asc, t1.update_time desc) rank, t1.user_id,t1.user_name,t2.position_name,t2.industry_name from user_objective_primary t1 left join user_objective t2 on t1.user_id = t2.user_id left join sys_user t3 on t1.track_id = t3.user_id left join hzrc_organization t4 on t3.organ_id = t4.organ_id -- 此处补充一对多where条件 ) info -- 以下为分页语法,替换为自己的动态传参接入当前页、页码 where (info.rank >= (1-1)*10 + 1) and info.rank <= 1*10 order by info.rank asc- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
上述sql原理是利用
DENSE_RANK函数排名不断号的特点,针对一对多查询,需要将一部分重复标记为同排序号,这样后面再根据排序号做where条件筛选,会将排序号并列的N条记录全部查出来,就不仅仅是分页页码的条数了,这样一对多合并数据也不会丢失。
如:分页页码=10,结果集查出来了14条,并列第一2条,并列第三4条,多出来的4条记录排序号也在10以内,满足where条件分页的结果。4.2 查询每个分组排名第一
场景:查询群消息表中,每个用户最后发的消息
本场景可以理解为N种场景,只要涉及一个维度分组,只要有排序,只要涉及只取某些排序号都符合
解决方案:
- 1.使用
DENSE_RANK或RANK函数均可 - 2.排序根据消息记录最新时间倒序
简单示例:
select id,userId,msg,send_time, RANK() OVER (ORDER BY userId, send_time desc) as rank from hzrc_message where rank = 1- 1
- 2
- 3
- 4
上述sql语法为mysql的,对于检查严格的数据库,需要在外层再套一个查询,将本sql作为结果集,才能用rank=1的条件
更多场景后续再写,不做理论
-
相关阅读:
进程创建&&进程终止&&进程等待
ENVI: 如何进行图像的自动配准?
前端Vue3+element-plus表单输入框实现Cron表达式校验
MySQL学习笔记--innodb锁机制
复习Day16:栈与队列part03:150.逆波兰表达式求值、239.滑动窗口最大值、260. 只出现一次的数字III
std::format 如何实现编译期格式检查
最高月薪17K,只要心中有一片希望的田野,勤奋耕耘将迎来一片翠绿~
java-net-php-python-ssm大学生交互自助平台查重PPT计算机毕业设计程序
如何使用mysql binlog 恢复数据
下雨小雲動畫
- 原文地址:https://blog.csdn.net/visket2008/article/details/126863900