-
Spark连接ES实现kerberos认证
1、jar包
org.apache.spark spark-core_${scala.version} ${spark.version} org.apache.spark spark-sql_${scala.version} ${spark.version} org.elasticsearch elasticsearch-hadoop 6.8.21 org.apache.hadoop hadoop-common 2.8.3
2、代码
- package study
- import org.apache.spark.SparkConf
- import org.apache.spark.sql.types._
- import org.apache.spark.sql.{Row, SaveMode, SparkSession}
- import org.elasticsearch.spark.sql.DefaultSource15
- import scala.collection.mutable
- object SparkToEs {
- def main(args: Array[String]): Unit = {
- initEsProperties(false)
- }
- def initEsProperties(useKerberos: Boolean): Unit = {
- // 构建spark上下文
- val conf = new SparkConf().setAppName("df").setMaster("local[2]")
- val spark = SparkSession.builder()
- .config(conf)
- .getOrCreate()
- val DOC_ID = "a1"
- val esConfig = new mutable.HashMap[String, String]
- var host = ""
- esConfig += ("es.resource" -> "cool_es_test/cool_es_test_tb")
- esConfig += ("es.write.operation" -> "index")
- val httpUrls = "http://192.168.1.151:9200"
- if (httpUrls.contains(",")) {
- esConfig += ("es.nodes.wan.only" -> "true")
- esConfig += ("es.nodes" -> httpUrls)
- host = httpUrls.split(":")(1).substring(2)
- } else {
- esConfig += ("es.nodes.wan.only" -> "true")
- esConfig += ("es.nodes" -> httpUrls.split(":")(1).substring(2))
- esConfig += ("es.port" -> httpUrls.split(":")(2).replace("/", ""))
- host = httpUrls.split(":")(1).substring(2)
- }
- esConfig += ("es.mapping.id" -> DOC_ID)
- if (useKerberos) {
- val KEYTAB = "D:\\workspace\\demo\\src\\main\\resources\\kerberos\\XXXXX.keytab"
- val PRINCIPAL = "XXXXX"
- val KRB5CONF = "D:\\workspace\\demo\\src\\main\\resources\\kerberos\\krb5.conf"
- var es_principal = "HTTP/" + host + "@EXAMPLE.COM"
- esConfig += ("es.security.authencation" -> "kerberos")
- esConfig += ("es.net.spnego.auth.elasticsearch.principal" -> es_principal)
- esConfig += ("es.security.user.provider.class" -> "com.cool.kerberos.OHadoopUserProvider")
- esConfig += ("es.spark.principal" -> PRINCIPAL)
- esConfig += ("es.spark.keytab" -> KEYTAB)
- spark.sparkContext.addFile(KEYTAB)
- System.setProperty("http.auth.preference", "Kerberos")
- System.setProperty("java.security.krb5.conf", KRB5CONF)
- System.setProperty("sun.security.krb5.debug", "false")
- System.setProperty("sun.security.spnego.debug", "false")
- }
- val ds: DefaultSource15 = new DefaultSource15
- val someData = Seq(Row("2022-06-23 11:", 6, 10.6, "2022-10-27", "13:11:22", "2021-10-27T14:33:33"))
- val someSchema = List(
- StructField("a1", StringType, true),
- StructField("a2", IntegerType, true),
- StructField("a3", DoubleType, true),
- StructField("a4", StringType, true),
- StructField("a5", StringType, true),
- StructField("a6", StringType, true)
- )
- val df = spark.createDataFrame(spark.sparkContext.parallelize(someData), StructType(someSchema))
- df.show()
- val writeModeMap = Map("append" -> SaveMode.Append, "overwrite" -> SaveMode.Overwrite)
- ds.createRelation(spark.sqlContext, writeModeMap.getOrElse("append", SaveMode.Append), esConfig.toMap, df)
- }
- }
3、spark连接es,需要保证每个executor都有对应凭证连接ES
- package com.cool.kerberos;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.security.UserGroupInformation;
- import org.apache.spark.SparkFiles;
- import org.elasticsearch.hadoop.EsHadoopException;
- import org.elasticsearch.hadoop.cfg.ConfigurationOptions;
- import org.elasticsearch.hadoop.cfg.Settings;
- import org.elasticsearch.hadoop.mr.security.HadoopUser;
- import org.elasticsearch.hadoop.security.User;
- import org.elasticsearch.hadoop.security.UserProvider;
- import java.io.File;
- import java.io.IOException;
- /**
- * 重写了HadoopUserProvider类
- *
- * 修改内容: 在获取ugi的时候,判断是否登录,如果没有就自动登录,并返回ugi,这样在每个executor节点中都会自动登录
- * 用法: esConifg中配置 es.security.user.provider.class
- * esConfig.put(ConfigurationOptions.ES_SECURITY_USER_PROVIDER_CLASS -> "com.cool.kerberos.KHadoopUserProvider"
- *
- *
- */
- public class OHadoopUserProvider extends UserProvider {
- public static final String SPARK_ES_PRINCIPAL = "es.spark.principal";
- public static final String SPARK_ES_KEYTAB = "es.spark.keytab";
- public KHadoopUserProvider() {
- super();
- }
- public static KHadoopUserProvider create(Settings settings) {
- KHadoopUserProvider provider = new KHadoopUserProvider();
- provider.setSettings(settings);
- return provider;
- }
- @Override
- public User getUser() {
- try {
- UserGroupInformation ugi = UserGroupInformation.getLoginUser();
- if (ugi == null || !ugi.hasKerberosCredentials()) {
- ugi = doLogin(settings);
- }
- return new HadoopUser(ugi, getSettings());
- } catch (IOException e) {
- throw new EsHadoopException("Could not retrieve the current user", e);
- }
- }
- private UserGroupInformation doLogin(Settings settings) throws IOException {
- Configuration krb_conf = new Configuration();
- krb_conf.set("hadoop.security.authentication", "kerberos");
- krb_conf.set(ConfigurationOptions.ES_SECURITY_AUTHENTICATION, "kerberos");
- String keytab = settings.getProperty(SPARK_ES_KEYTAB);
- String principal = settings.getProperty(SPARK_ES_PRINCIPAL);
- System.out.println("keytab: " + keytab + "; principal: " + principal);
- if (principal == null || keytab == null) {
- throw new RuntimeException("principal or keytabPath 参数不存在, 请配置 " + SPARK_ES_KEYTAB + " and " + SPARK_ES_PRINCIPAL);
- }
- String keytabPath = SparkFiles.get(keytab);
- // 判断文件是否存在
- if (!new File(keytabPath).exists()) {
- throw new RuntimeException("executor端登陆失败, keytab文件(" + keytabPath + ")不存在, 请通过sparkContext.addFile将文件添加入executor节点");
- }
- System.setProperty("java.security.krb5.conf", "/etc/krb5.conf");
- if (!new File("/etc/krb5.conf").exists()) {
- throw new RuntimeException("executor登录失败, /etc/krb5.conf 文件不存在");
- }
- UserGroupInformation.setConfiguration(krb_conf);
- UserGroupInformation ugi = UserGroupInformation.loginUserFromKeytabAndReturnUGI(principal, keytabPath);
- UserGroupInformation.setLoginUser(ugi);
- return ugi;
- }
- }
4、kerberos认证过程中出现的问题以及处理方案
问题1:
Caused by: GSSException: No valid credentials provided (Mechanism level: No valid credentials provided (Mechanism level: Server not found in Kerberos database (7) - LOOKING_UP_SERVER)解决1:_HOST 写死成ES 主机名,局限是:host 只能配置一台ip
问题2:
- org.elasticsearch.hadoop.rest.EsHadooptransportException : Missing required negotiation token
- org.elasticsearch.hadoop.rest.EsHadoopNodesLeftException: Connection error (check network and/or proxy settings) - all nodes failed; tried[[hostname]]
解决2: 使用官方推荐配置,HTTP/_HOST@REALM.NAME.HERE
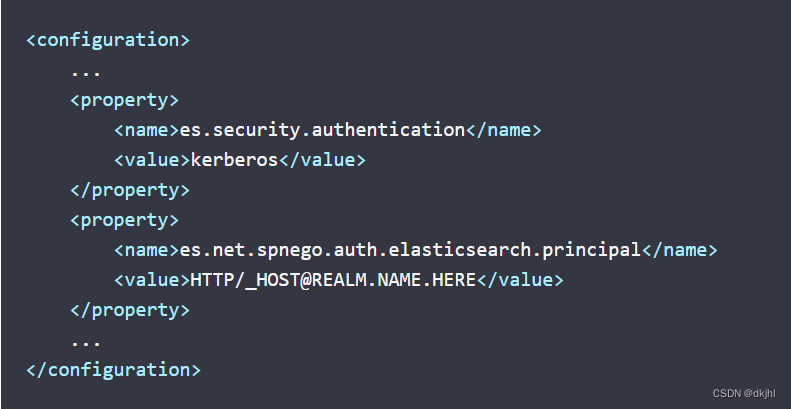
问题3:时钟同步问题;Java连接ES有时候也会出现同样错误
- Caused by: org.elasticsearch.client.ResponseException: method [POST],host[http://test.com:9200],URI[/_bulk?timeout=1m],status line[HTTP/1.1 401 Unauthorized]
- Caused by: ElasticsearchException[Elasticsearch exception [type=g_s_s_excpetion,reason=Failure unspecified at GSS-API level (Mechanism level: Request is a replay (34))]]; nested: ElasticsearchException[Elasticsearch exception [type=krb_ap_err_exception, reason=Request is a replay (34)]]
解决3: es的JVM 增加一个参数 -Dsun.security.krb5.rcache=none
5、参考文章
Kerberos | Elasticsearch for Apache Hadoop [master] | Elastic
https://web.mit.edu/kerberos/krb5-devel/doc/basic/rcache_def.html
-
相关阅读:
STM32读保护的解除和出现的原因,使用串口和ST-LINK Utility解除读保护
Linux - make命令 和 makefile
【TCP】滑动窗口、流量控制 以及拥塞控制
《设计模式》之迭代器模式
单细胞组学简介
【Redis学习笔记】redis-trib.rb命令详解
新移科技发布基于联发科MT8390(Genio 700)平台的物联网 AI 核心板
【算法】动态规划
Python jupyter notebook Katex|Latex
Linux内核设计与实现 第十章 内核同步
- 原文地址:https://blog.csdn.net/dkjhl/article/details/126871880
