-
【运维/安装】Flink + MinIO:实现light-weighting思路下的集群(集群、高可用&&POC、快速搭建)
一. 概述
先看下flink 的几种部署模式和适用场景

本文通过使用flink+MinIO安装实现flink standalone的集群模式,实现“轻量化集群”
- flink集群本身作为计算资源,去执行flink job
- Minio 用于存储Flink job产生checkpoint和savepoint、以及存储flink HA的一些信息,也就是作为分布式存储系统。
二. Flink配置MinIO实现Checkpoint和Savepoint
1. 配置s3文件系统
Apache Flink 1.12 Documentation: Amazon S3
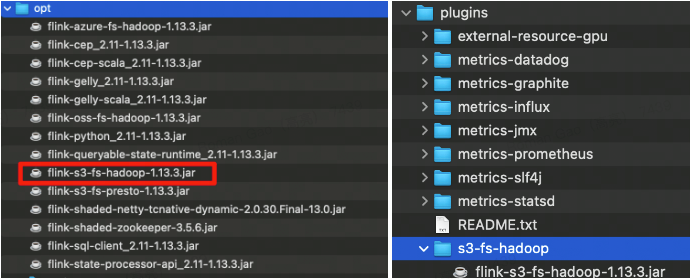
[Apache Flink]: Where is flink-s3-fs-hadoop plugin?将opt的文件复制到plugins下,如下图
2. 配置checkpoint和savepoint
flink-conf.yaml配置文件修改
fs.allowed-fallback-filesystems: s3 state.backend: filesystem state.checkpoints.dir: s3://state/checkpoint state.savepoints.dir: s3://state/savepoint s3.endpoint: http://10.0.16.220:9000 s3.path.style.access: true s3.access-key: minio s3.secret-key: minio123- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
配置checkpoint目录时minio上要提前创建好bucket,并且不能使用bucket作为checkpoint根路径。否则不能实例化jobmanager。本文是state。
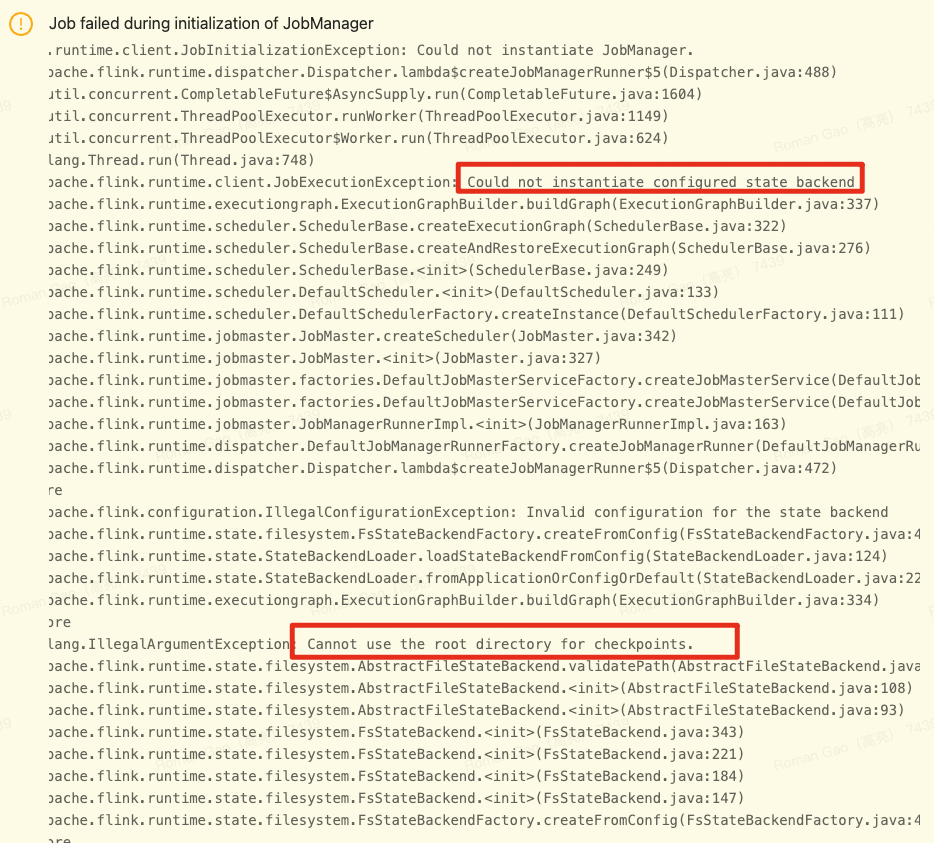
3. 提交一个flink job到flink集群上
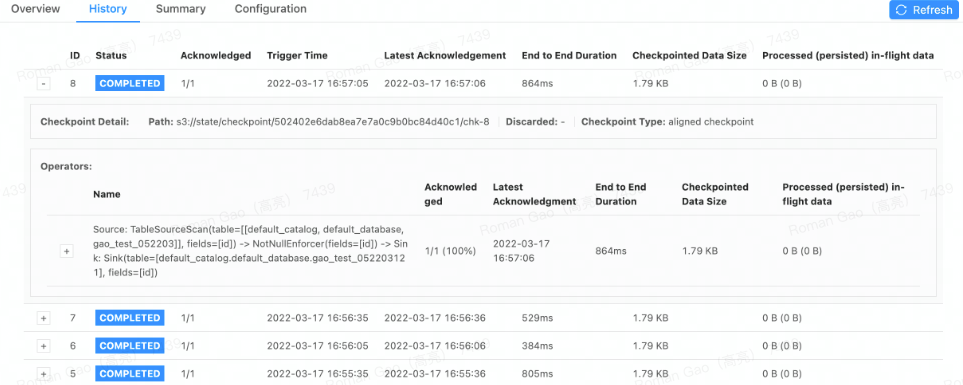
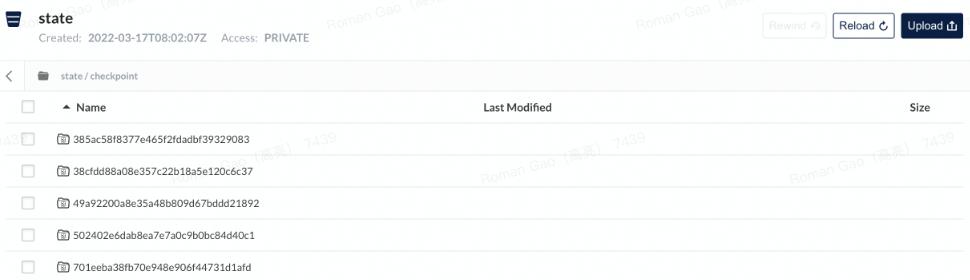
三. minio的安装
1.单节点安装
#新建minio文件夹 mkdir minio cd minio #新建存数据的文件夹 mkdir data #下载minio 如果链接失效访问mino官网获取最新下载地址 wget https://dl.min.io/server/minio/release/linux-amd64/minio #加权限 chmod +x minio #自定义账号密码 export MINIO_ACCESS_KEY=minio export MINIO_SECRET_KEY=minio123- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
后台启动
nohup /data/a 2pp/minio/minio server /data/app/minio/data > /data/log/minio/minio.log 2>&1 &- 1
前端访问
ip:9000- 1

2.多节点安装
多节点minio安装 ing
配置tegine
为了不将所有的读写请求都落到一个节点,造成读写压力,通过利用tengine的反向代理实现负载均衡
#配置minio的upstream主要实现集群的反向代理,和请求转发 cd /data/app/tengine/conf/vhost vim http_minio.proxy.conf #重新启动tegine bash /data/app/tengine/scripts/tengine restart # 配置 http_minio.proxy.conf # Minio 主备 配置 upstream minio { server 10.0.16.214:18125 weight=1; server 10.0.16.231:28125 weight=1; server 10.0.16.220:18125 weight=1; server 10.0.16.247:18125 weight=1; check interval=1000 rise=2 fall=5 timeout=1000 type=http; check_http_send "GET /minio/health/live HTTP/1.0\r\n\r\n"; check_http_expect_alive http_2xx http_3xx; } # Minio Server 域 server { # tegine 监听minio请求的端口和tegine的ip listen 18095; server_name 10.0.16.214; ignore_invalid_headers off; client_max_body_size 0; proxy_buffering off; location / { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header Host $http_host; proxy_http_version 1.1; proxy_set_header Connection ""; proxy_connect_timeout 300; proxy_pass http://minio/; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
三. flink的高可用安装
设置三个节点的flink,实现高可用。集群角色分布如下:
flink-ip1:jobmanager taskmanager
flink-ip2:jobmanager taskmanager
flink-ip3:jobmanager taskmanager1. 配置flink-conf.yaml
#============================================================================== # 1. Common 配置 #============================================================================== # The external address of the host on which the JobManager runs and can be # reached by the TaskManagers and any clients which want to connect. This setting # is only used in Standalone mode and may be overwritten on the JobManager side # by specifying the --hostparameter of the bin/jobmanager.sh executable. # In high availability mode, if you use the bin/start-cluster.sh script and setup # the conf/masters file, this will be taken care of automatically. Yarn/Mesos # automatically configure the host name based on the hostname of the node where the # JobManager runs. # 指定所在节点的ip jobmanager.rpc.address: 10.2.3.155 # The RPC port where the JobManager is reachable. jobmanager.rpc.port: 18550 jobmanager.rpc.bind-port: 18550 # The total process memory size for the JobManager. # # Note this accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead. jobmanager.memory.process.size: 1600m # The total process memory size for the TaskManager. # # Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead. taskmanager.memory.process.size: 1728m # To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'. # It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory. # # taskmanager.memory.flink.size: 1280m # The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline. taskmanager.numberOfTaskSlots: 8 # The parallelism used for programs that did not specify and other parallelism. parallelism.default: 1 #============================================================================== # 2. High Availability # 以下配置在standalone模式下打开 #============================================================================== # ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes # It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE) # The default value is "open" and it can be changed to "creator" if ZK security is enabled # # high-availability.zookeeper.client.acl: open high-availability: zookeeper high-availability.storageDir: s3://flink/ha/ high-availability.zookeeper.quorum: 10.2.3.59:127,10.2.3.156:18127,10.2.3.155:18127 high-availability.zookeeper.client.acl: open ### 3. 设置checkpoint 和savepoint fs.allowed-fallback-filesystems: s3 state.backend: filesystem state.checkpoints.dir: s3://state/checkpoint state.savepoints.dir: s3://state/savepoint s3.endpoint: http://xxx:18095/ s3.path.style.access: true s3.access-key: admin s3.secret-key: MINIO@minio_123 #============================================================================== # 4. Fault tolerance and checkpointing #============================================================================== # The backend that will be used to store operator state checkpoints if # checkpointing is enabled. jobmanager.execution.failover-strategy: region #============================================================================== # Rest & web frontend #============================================================================== # The port to which the REST client connects to. If rest.bind-port has # not been specified, then the server will bind to this port as well. # rest.port: 18551 # The address to which the REST client will connect to # #rest.address: 0.0.0.0 # Port range for the REST and web server to bind to. # rest.bind-port: 18551-18590 # The address that the REST & web server binds to # #rest.bind-address: 0.0.0.0 # Flag to specify whether job submission is enabled from the web-based # runtime monitor. Uncomment to disable. web.submit.enable: true #============================================================================== # Advanced #============================================================================== #flink的ssh参数 env.ssh.opts: -p 36000 ##flink日志路径 env.log.dir: /data/logs/flink ## 监控设置 metrics.reporter.promgateway.password: Push$777 metrics.reporter.promgateway.metric.only.report.names: flink_jobmanager_job_lastCheckpointSize,flink_jobmanager_job_lastCheckpointDuration,flink_jobmanager_job_numberOfFailedCheckpoints,flink_jobmanager_Status_JVM_CPU_Load,flink_jobmanager_Status_JVM_Memory_Heap_Used,flink_jobmanager_Status_JVM_GarbageCollector_PS_MarkSweep_Count,flink_jobmanager_Status_JVM_GarbageCollector_MarkSweepCompact_Count,flink_jobmanager_Status_JVM_GarbageCollector_PS_MarkSweep_Time,flink_jobmanager_Status_JVM_GarbageCollector_MarkSweepCompact_Time,flink_taskmanager_Status_JVM_CPU_Load,flink_taskmanager_Status_JVM_Memory_Heap_Used,flink_taskmanager_Status_JVM_GarbageCollector_MarkSweepCompact_Count,flink_taskmanager_Status_JVM_GarbageCollector_G1_Old_Generation_Count,flink_taskmanager_Status_JVM_GarbageCollector_PS_MarkSweep_Count,flink_taskmanager_Status_JVM_GarbageCollector_MarkSweepCompact_Time,flink_taskmanager_Status_JVM_GarbageCollector_G1_Old_Generation_Time,flink_taskmanager_Status_JVM_GarbageCollector_PS_MarkSweep_Time,flink_taskmanager_job_task_Shuffle_Netty_Output_Buffers_outPoolUsage,flink_taskmanager_job_task_Shuffle_Netty_Input_Buffers_inPoolUsage,flink_taskmanager_job_task_Shuffle_Netty_Output_Buffers_outputQueueLength,flink_taskmanager_job_task_Shuffle_Netty_Input_Buffers_inputQueueLength,flink_taskmanager_job_task_currentInputWatermark,flink_jobmanager_job_downtime,flink_taskmanager_job_task_numBytesIn,flink_taskmanager_job_task_numBytesOut,flink_taskmanager_job_task_numRecordsIn,flink_taskmanager_job_task_numRecordsOut internal.yarn.log-config-file: /data/app/flink/conf/log4j.properties metrics.reporter.promgateway.host: promgateway-ip metrics.reporter.promgateway.username: admin metrics.reporter.promgateway.deleteOnShutdown: false metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.CustomedPrometheusPushGatewayReporter metrics.reporter.promgateway.groupingKey: mode=2;id=100000153;account_id=110;instance= metrics.reporter.promgateway.jobName: myJob metrics.reporter.promgateway.port: 18165 metrics.reporter.promgateway.interval: 15 SECONDS- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
注意:省略zookeeper的安装
2. Masters 和workers设置
masters代表三个节点都有jobmanager角色,对于高可用来说其中两个jobmanager挂掉,flink集群仍然可以运行。
[root@10-101-1-48 conf]# cat masters flink-ip1:18551 flink-ip2:18551 flink-ip3:18551 [root@10-101-1-48 conf]# cat workers flink-ip1 flink-ip2 flink-ip3- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3. 文件分发并修改
scp -P 36000 /data/app/flink/conf/masters user@flink-ip:/data/app/flink/conf scp -P 36000 /data/app/flink/conf/workers user@flink-ip:/data/app/flink/conf scp -P 36000 /data/app/flink/conf/flink-conf.yaml user@flink-ip:/data/app/flink/conf- 1
- 2
- 3
修改flink-conf.yaml下的
# 指定所在节点的ip jobmanager.rpc.address: ip- 1
- 2
4. 启动
三个节点分别执行
bash /data/app/flink/bin/jobmanager.sh start && bash /data/app/flink/bin/taskmanager.sh start- 1
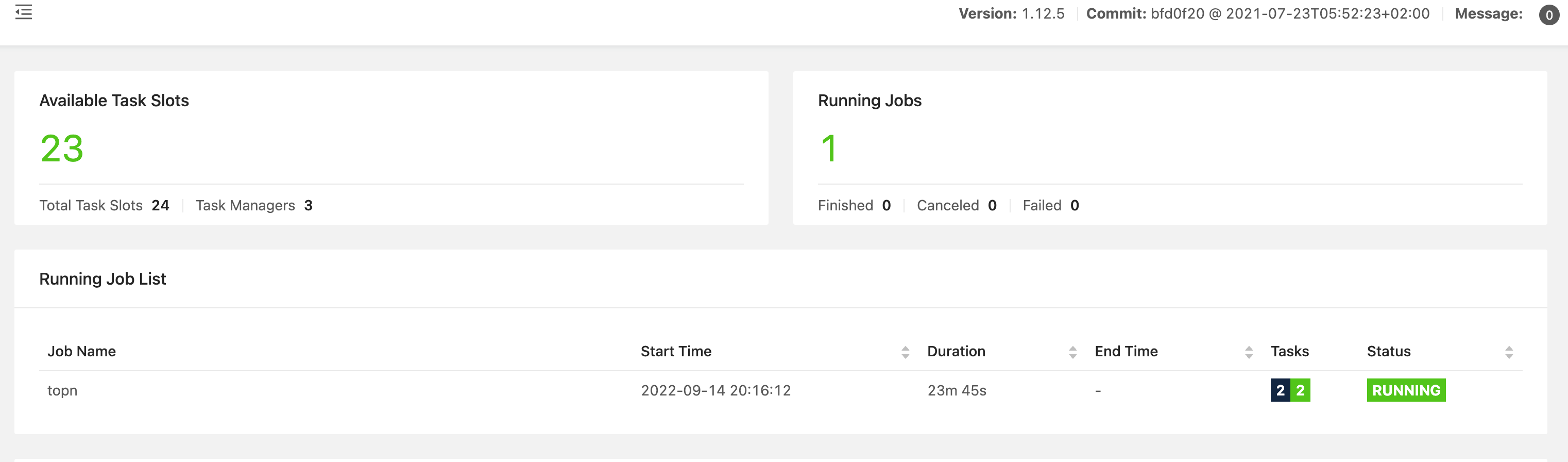
-
相关阅读:
SM2密码算法数据结构
JSP汽车维修服务管理系统myeclipse开发SqlServer数据库bs框架java编程web网页结构
【数据结构】海量数据处理
NOIP2023模拟12联测33 游戏
Unity 使用StateMachineBehaviour让动画控制器状态自动关闭跳出
[项目管理-4]:软硬件项目管理 - 人月神话:项目时间管理(时间)- 概述
激活码问题解疑【点盾云】
Linux系统OpenSSH_9.7p1升级详细步骤
Day10:图形用户界面和游戏开发
分享一下微信小程序里的预约链接怎么做
- 原文地址:https://blog.csdn.net/hiliang521/article/details/126860098