-
Nifi01概念
Nifi概念
1.1 Nifi介绍
Apache Nifi是Apache基金会的顶级项目之一,是一个易于使用,功能强大且可靠的处理和分发数据的系统。使用Nifi可以自动化管理系统间的数据,支持从多种数据源拉取数据。
Nifi是基于Java的,使用maven支持包的构建管理。Nifi基于web方式工作,后台在服务器进行调度,Nifi具有数据处理引擎、任务调度等组件。简单来说,Nifi就是为了解决不同系统之间数据自动流通等问题而建立。
Dataflow是Nifi中一个重要的术语,在这里我们用来表示可以管理的信息流。Dataflow对企业至关重要,因此对数据流的合规性、隐私性和安全性也做了严格的要求。
Dataflow处理中存在的挑战:
-
Systems fail
网络故障、磁盘故障、软件崩溃等
-
Data access exceeds capacity to consumer
数据访问环节超出消耗能力。某一个环节需要处理的数据超出了他的处理能力,而当一个环节出现问题后,会影响整个流程。
-
Boundary coditions are mere suggestions
超出边界问题,会导致得到不一致的数据问题。
-
What is noise one day becomes signal the next
业务需求变更频繁情况下,要迅速修改或设计新的流程。
-
Systems evolve at different rates
给定的系统所使用的协议或数据格式可能随时改变,而且常常跟周围的其他系统无关。Dataflow的存在就是为了连接这种大规模分布的,松散的,甚至根本不是用来设计用来一期工作的组件系统。
-
Compliance and security
法律、法规以及政策的变化,企业对企业协议的比那花,系统到系统和系统到用户的交互必须是安全的、可信的、负责任的。
-
Continuous improvement occurs in production
通常不可能在测试环境中完全模拟生产环境。
1.2 NIFI核心概念
-
FlowFile
FlowFile表示在系统中移动的每个对象,对于每个FlowFile,Nifi都会记录它的一个属性键值对和零个或多个字节内容(FlowFile有attribute和content两者选择)
-
FlowFile Processor
处理器可以访问给定FlowFilw的属性及内容。处理器可以给定工作单元中的零个火多个流文件进行操作,并提交该工作或回滚该工作。
-
Connection
Connection用来连接处理器。充当队列并允许各种进程以不同的速率进行交互。这些队列可以动态的进行优先级排序,并且可以在负载上设置上限,从而启用背压。
-
Flow Controller
流控制器维护流程如何连接,并管理和分配所有流程使用的线程。流控制器充当代理,促进处理器之间流文件的交换。
-
Process Group
进程组里是一组特定的流程和连接,可以通过输入端口接收数据并通过输出端口发送数据,这样我们在进程组里简单的组合组件,就可以得到一个全新功能的组件(Process Group)。
此设计模型也类似于seda(分阶段),带来了很多好处,有助于NiFi成为非常有效的、构建功能强大且可扩展的数据流的平台。其中一些好处包括:
- 有助于处理器有向图的可视化创建和管理
- 本质上是异步的,允许非常高的吞吐量和足够的自然缓冲
- 提供高并发的模型,开发人员不必担心并发的复杂性
- 促进内聚和松散耦合组件的开发,然后可以在其他环境中重复使用并方便单元测试
- 资源受限的连接(流程中可配置connections)使得背压和压力释放等关键功能非常自然和直观
- 错误处理变得像基本逻辑一样自然,而不是粗粒度的全部捕获(catch-all)
- 数据进入和退出系统的点,以及它是如何流动的,都是容易理解和跟踪的。
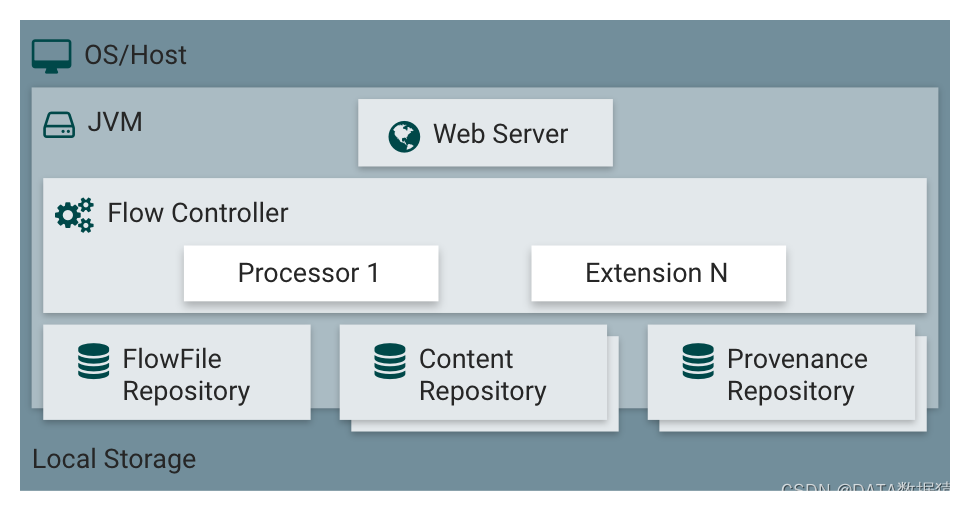
1.3 NiFi架构
-
Web Server(网络服务器)
Web服务器的目的是承载Nifi基于Http的命令和控制api。
-
Flow Controller(流控制器)
是整个操作的核心,为将要运行的组件提供线程,管理调度。
-
Extensions(扩展)
有各种类型的Nifi扩展,这些扩展在其他文档中进行了描述。这里的关键是Nifi扩展在JVM中操作和执行。
-
FlowFile Repository(流文件存储库)
对于给定一个流中正在活动的FlowFile、FlowFile Repository就是Nifi保持跟踪这个FlowFile状态的地方。
-
Content Repository(内容存储库)
Content Repository是给定FlowFile的实际内容字节存储的地方。Content Repository的实现是可插拔的。默认方法是一种相当简单的机制,它将数据块存储在文件系统中。可以指定多个文件系统存储位置,以便获得不同的物理分区以减少任何单个卷上的争用。
-
Provenance Repository(源头存储库)
Provenance Repository是存储所有事件数据的地方。Provenance Repository的实现是可插拔的,默认实现是使用一个或多个物理磁盘卷。在每个位置内的事件数据都是被索引并可搜索的。
NiFi集群内运行

Cluster Coordinator:集群协调器,用来进行管理节点添加和删除的操作逻辑。
Primary Node:主节点,用来运行一些不适合在集群中运行的组件。
Zookeeper Client:zk节点。
从Nifi 1.0版本开始,Nifi集群采用了Zero-Master Clustering模式。Nifi集群中每个节点对数据执行相同的任务,但是每个节点都在不同的数据集上运行。Apache Zookeeper选择单个节点作为集群协调器,Zookeeper自动处理故障转移。所有集群节点都会向集群协调器发送心跳报告和状态信息。集群协调器负责断开和连接节点。此外,每个集群都要有一个主节点,主节点也是由Zookeeper选举产生。我们可以通过任何系欸按的用户界面与Nifi集群进行交互,并且我们所做的任何更改都将复制到集群中的所有节点上。
1.4 NIFI的性能
NIFI的设计目的是充分利用其运行的底层主机系统的能力。这种资源的最大化在CPU和磁盘方面尤其明显。
-
For IO
系统配置不同,效果不同。鉴于大多数Nifi子系统都有可插拔的实现方式,所以性能取决于实现。但是,对于一些具体和广泛适用的地方,可以考虑默认的方式实现。这些实现都是持久的,有保证的让数据流传递,并且是使用本地磁盘实现。因此,保守点说,假设在典型服务器中的普通磁盘活RAID卷上每秒读写速率大约50MB,那么对于大型数据流,nifi应该可以达到每秒100MB或者更多的吞吐量。这是因为预期添加到nifi的每个物理分区和content repository都会出现线性增长。
-
For CPU
Flow Controller充当引擎的角色,指示特定处理器何时可以被分配到线程去执行。编译处理器并在执行任务后立即释放线程。可以为Flow Controller提供一个配置值,该值指示它维护的各种线程池的可用线程。理想的线程数取决于主机系统内核数量,系统中是否正在运行其他服务,以及流程中要处理的流的性质。对于典型的IO大流量,合理的做法是让多线程可用。
-
For RAM
Nifi在JVM中运行,因此受限于JVM提供的内存。JVM垃圾回收成为限制实际堆总大小以及优化应用程序运行的一个非常重要的因素。Nifi作业在定期读取相同内容时可能会占用大量IO。可以配置足够大的内存和磁盘以优化性能。
1.5 NIFI关键特性
流管理
-
保证交付
Nifi的核心理念是,即使在非常高的规模下,也必须保证交付。这是通过有效的使用专门构建的write-aheadlog和content respository来实现的。他们一起被设计成具备允许非常高的事物速率、有效的负载分布、写实复制和能发挥传统磁盘读写的优势。
-
数据缓冲 背压和压力释放
Nifi支持缓冲所有排队的数据,以及在这些队列达到指定限制的时候提供背压能力(背压对象阈值和背压数据大小阈值),或在数据达到指定期限(其值已经失效)时丢弃数据的能力。
-
队列优先级
Nifi允许设置一个或多个优先级方案,用于如何从队列中检索数据。默认情况是先进先出,但有时应该首先提取最新的数据(后进先出)、最大的数据先出或制定其他方案。
-
特殊流质量 (延迟和吞吐量)
可能在数据流的某些节点上至关重要,不容有失,并且在某些时刻这些数据需要在几秒钟就处理完毕传向下一节点才会有意义。对于这些方面Nifi也可以做细粒度的配置。
易用性
-
可视化流程
数据流的处理逻辑和过程可能非常复杂,而通过可视化的流程可以很大的帮助用户降低复杂度,并且可以较为明确的了解哪个地方需要简化。Nifi对数据流的更改,会立即生效,这些更改是细粒度的和组件隔离的。用户不需要为了特定的修改而停止整个流程。
-
流模版
FlowFile处理是高度模式化的,虽然可以使用多种方法来解决问题,但是通过定义模板,可以较为方便、快速的处理相似问题。
-
数据起源跟踪
在数据流经系统时,输入、输出、转换过程,Nifi都会自动记录,并提供可用的源数据。这些信息在支持法规遵从性、故障排除、优化以及其他方案中变得极其关键。
-
可以记录和重放的细粒度历史记录缓冲区
Nifi的content repository可以充当历史数据的滚动缓冲区。数据仅在content repository老化或者空间需要释放时才被删除。content repository与data provenance能力相结合,为对象生命周期中特定点并可以查看内容,内容下载和重放等功能提供非常有用的基础。
灵活的缩放模型
-
水平扩展 (Clustering)
Nifi的设计是可集群、可横向扩展的。如果配置单个节点并将其配置为每秒处理百MB数据,那么可以相应的将集群配置为每秒处理GB级数据。但这也带来了Nifi与其获取数据的系统之间的负载均衡和故障转移的调整。采用基础异步排队的协议,例如:消息队列,可以提供帮助解决这些问题。
-
扩展和缩小
Nifi还可以非常灵活的扩展和缩小。从Nifi框架的角度来看,在增加吞吐量方面,可以在配置时增加"调度"选项,合理的应对处理器上的并发任务数。允许更多线程同时执行,从而提高更高的吞吐量。另一方面,可以完美的将Nifi缩小到适合边缘设备上允许。如果是硬件资源有限的情况下,可以使用MiniNifi,需要占用的空间很小。
-
-
相关阅读:
【软考 系统架构设计师】数据库系统① 数据库系统的体系结构
一文学会线程池、任务调度的使用
布隆过滤器说明
postgresql分组取每组排序后最大最小的两条数据
实战真知 | 金融企业如何深度融合云原生技术?
linux 时间和北京时间对不上
ShardingSphere-JDBC分库分表快速入门实战
化合物纯度、溶剂溶解度检测
shell脚本知识点梳理
客户说:可视化大屏设计的不够高级,该如何破?
- 原文地址:https://blog.csdn.net/m0_51197424/article/details/126858454