-
汇编 --- 用户程序的结构 和 程序加载
处理器工作时,要获取指令或者访问数据,都需要按“段地址:偏移地址”的方式进行。所以段地址的访问就很重要。
一个规范的程序在它加载到内存之前就应该分好段了,程序员需要安排好代码段,数据段,附加段和堆栈段分别放在内存中哪个位置。SECTION 或 SEGMENT定义段
SECTION伪指令用于定义一个段:
SECTION SEG_NAME SEG_NAME是段名称 可以是任何名字 只要不混淆 定义后就可以通过段名称去引用这个段 SEGMENT SEG_NAME- 1
- 2
- 3
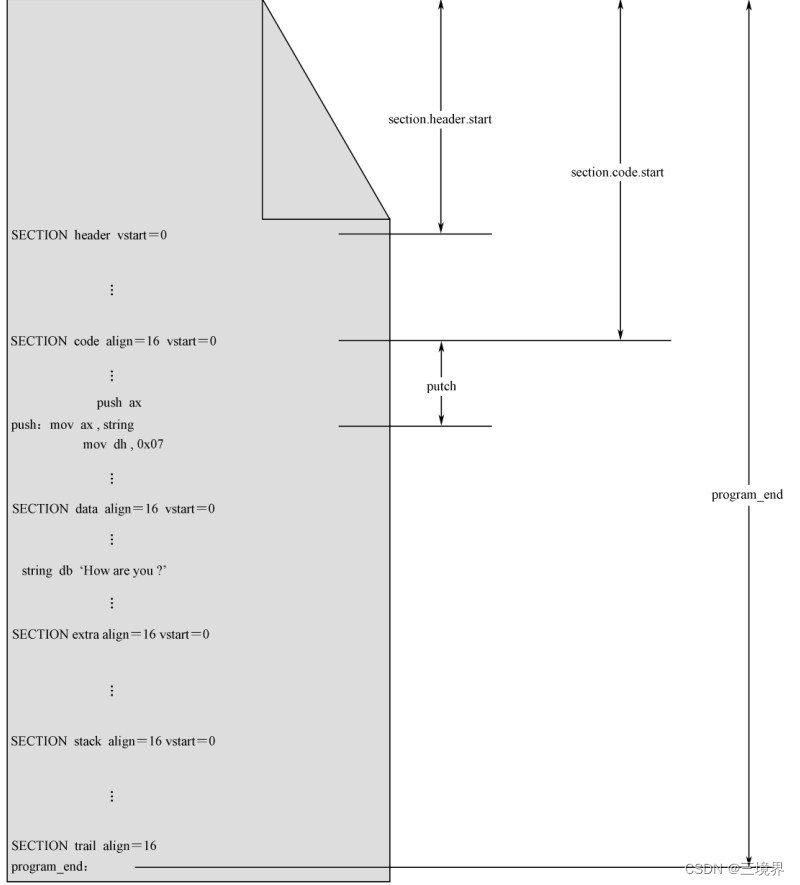
上图就有6个段,分别是:
header code data extra stack trailIntel处理器对段在内存中的放置位置是有要求的,段在内存中的起始物理地址必须是16字节对齐,详情见这篇文章:
intel段在内存中的要求所以我们在放置段时需要指定他们的对齐方式,也就是图中align指令在做的事情:
align = 16 子句指定这个段的汇编地址以16字节对齐相邻段之间的距离由这个对齐方式所确定,如果前一个段的内容不足以填满这个距离,那么剩下的空间必须以0填充到下一个段的起始地址之前
对已经定义好的段,想要引用它,可以用以下格式的命令:
section.段名称.start- 1
这个表达式就表示引用了某个段所在的地址相对0地址的偏移(0地址是整个程序的开头)。
header段相对于整个程序开头偏移为0,所以section.header.start=0
段定义语句里还包含了 vstart= 子句
vstart=表示 在跨段引用这个段里的标号时,标号所代表的汇编地址要从何处算起(header 和 code段里的标号从他们的段开头算起)
vstart=0 表示要从这个段的起始开始算起
没有vstart= 子句,就会从整个程序开头算起(trail段里的progra_end标号则是从程序开头算起)程序加载
加载器程序要把用户程序放到内存,必须知道一些信息,比方说程序的总长度,程序的入口点,段重定义表项数 ,段重定位表等
这些东西都是他们事先约定好的,你想被我加载到内存那必须提供这些信息,放在一个位置等我加载前去那儿取。加载器觉得最方便的地方,当然是程序头部了,所以图中单独定义了一个header段。
header段要包含的信息:
① 用户程序的尺寸,即以字节为单位的大小。这对加载器来说是很重要的,加载器需要根据这一信息来决定读取多少个逻辑扇区。
程序中定义的program_end标号就起作用了,它所在的段没有vstart语句,所以他的汇编地址在数值上是相对于程序起始地址的偏移,也就是整个程序的长度
② 应用程序的入口点,包括段地址和偏移地址。③ 段重定位表 以及 表项数目
-
相关阅读:
算法竞赛进阶指南 关押罪犯
SQL零基础入门教程,贼拉详细!贼拉简单! 速通数据库期末考!(七)
Packet Tracer - 综合技能练习(配置 VLAN 间路由、配置静态路由以及默认路由)
母婴店怎么在微信小程序卖东西
基于C++和QT实现的房贷计算器设计
【MindSpore入门教程】 02 自动微分
git stash 暂存当前修改
【藏经阁一起读】(68)__《ECS技术实战指南》
thinkphp6 入门(5)-- 模型是什么 怎么用
前端vue实现国际化
- 原文地址:https://blog.csdn.net/weixin_43604927/article/details/126855730