-
采用jieba库的posseg函数对剩余有效文本数据进行词性分析
采用jieba库的posseg函数对剩余有效文本数据进行词性分析
目录
一、实验流程说明 1- 读取原始数据文件 1
- 数据清洗 2
(1) 去停用词 2
(2) 去除特殊符号 2
(3) 去除异常文本 2 - 保存处理后数据并生成tfidf矩阵 2
- 聚类 2
- 层次聚类 2
(1)采用主成分分析方法PCA对tfidf矩阵进行降维; 2
(2)调用AgglomerativeClustering库函数实现对数据的层次聚类; 2
(3)给聚类结果的簇贴标签以描述每个簇对应文本的中心话题; 2
(4)输出聚类结果的二维图像及运行时间。 2 - K-均值聚类 3
(1) 使用PCA方法降维; 3
(2)调用KMeans库函数对降维后数据进行K-均值聚类; 3
(3)给聚类结果的簇贴标签以描述每个簇对应文本的中心话题; 3
(4)调用matplotlib绘制聚类结果二维图像,并确定各类中心点。 3
一、 所用模型与方法 3 - 层次聚类 3
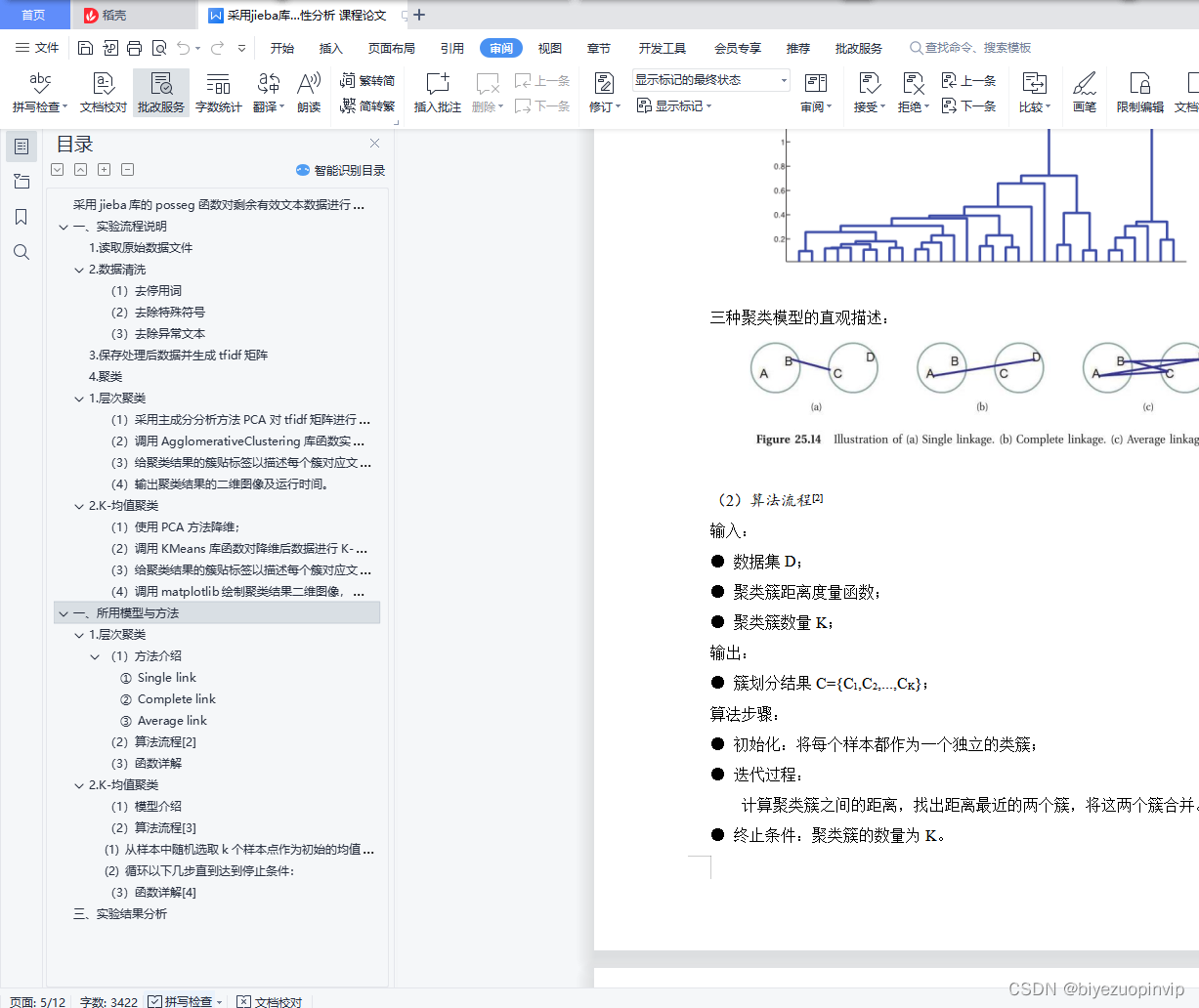
(1)方法介绍 3
(2)算法流程[2] 5
(3)函数详解 5 - K-均值聚类 6
(1) 模型介绍 6
(2) 算法流程[3] 7
(1) 从样本中随机选取k个样本点作为初始的均值向量{μ1,μ2,⋯,μk} 7
(2) 循环以下几步直到达到停止条件: 7
(3) 函数详解[4] 7
三、实验结果分析 8
一、实验流程说明
1.读取原始数据文件
采用pandas库可以直接读取.csv数据文件,并查看数据各方面信息。
2.数据清洗
(1)去停用词
根据网上常用的停用词库,本文转载自http://www.biyezuopin.vip/onews.asp?id=16731使用jieba库中lcut函数分割文本,逐词判断并删除文本中停用词,同时采用jieba库的posseg函数对剩余有效文本数据进行词性分析,进一步筛选文本。
(2)去除特殊符号
调用pandas库函数去掉问题中’?’、标点符号、特殊符号等。
(3)去除异常文本
使用pandas库清理文本中空行、重复数据、仅含字母和数字的文本以及问题中小于三个字的行。
3.保存处理后数据并生成tfidf矩阵
将处理后的文本数据按照初始顺序保存为.txt文件并输出所有统计词语的字典形式;调用sklearn库的TfidfVectorizer函数生成文本数据对应的tfidf矩阵。
4.聚类
本次实验采用两种不同聚类方式,包括层次聚类与K-均值聚类,均可实现文本聚类目标。
1.层次聚类
(1)采用主成分分析方法PCA对tfidf矩阵进行降维;
(2)调用AgglomerativeClustering库函数实现对数据的层次聚类;
(3)给聚类结果的簇贴标签以描述每个簇对应文本的中心话题;
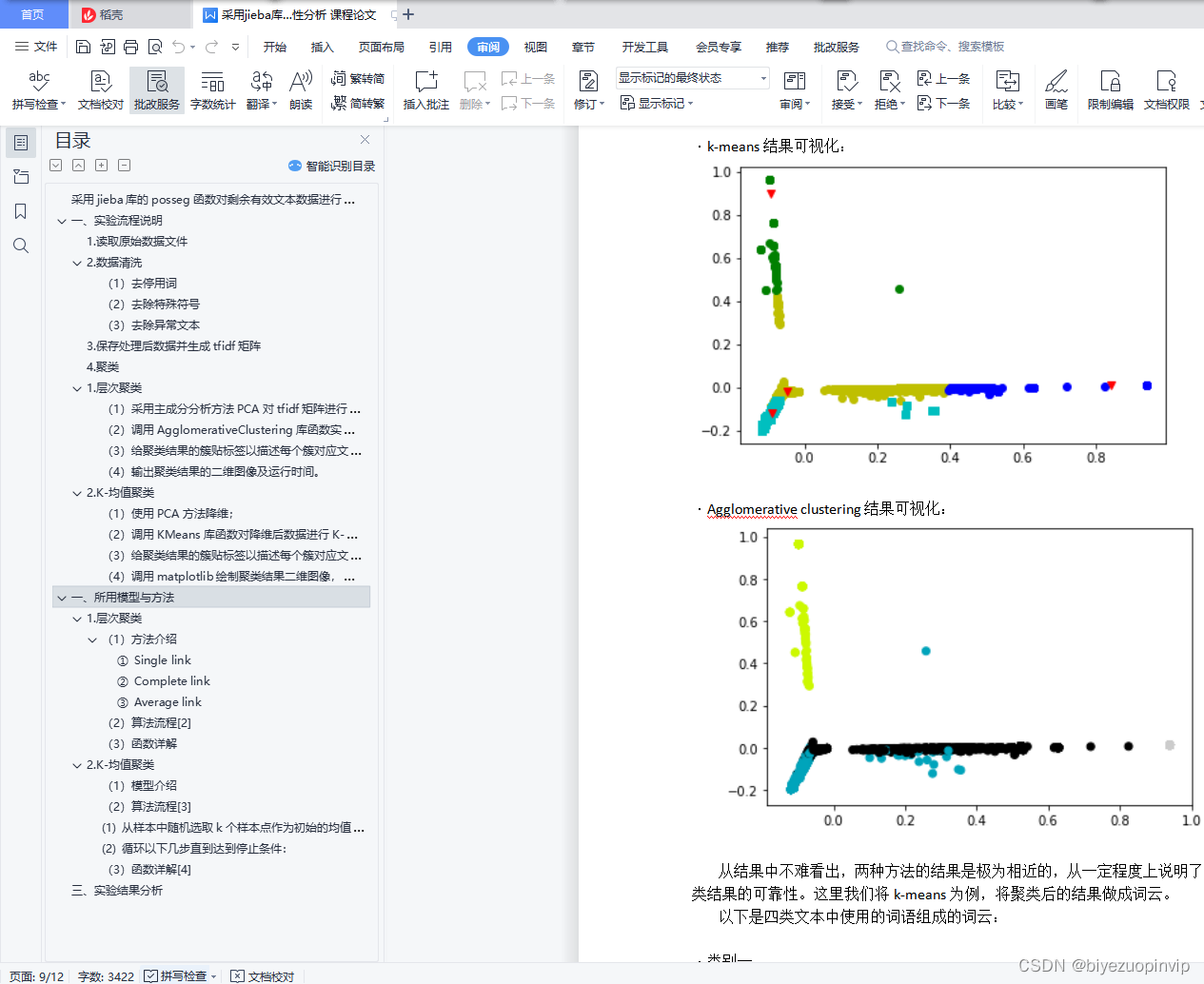
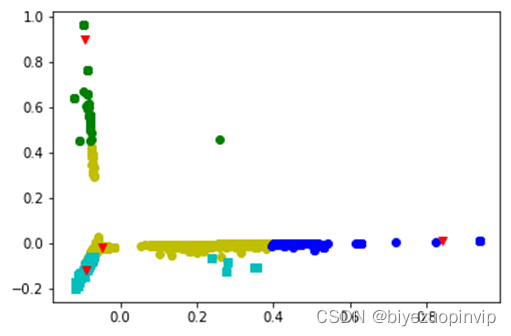
(4)输出聚类结果的二维图像及运行时间。
2.K-均值聚类
(1)使用PCA方法降维;
(2)调用KMeans库函数对降维后数据进行K-均值聚类;
(3)给聚类结果的簇贴标签以描述每个簇对应文本的中心话题;
(4)调用matplotlib绘制聚类结果二维图像,并确定各类中心点。
#!/usr/bin/env python # coding: utf-8 # In[64]: import pandas as pd import numpy as np import matplotlib.pyplot as plt import jieba import jieba.posseg as pseg import glob import random import re import string from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from collections import Counter #from keras import models #from keras import layers #from keras.preprocessing.text import Tokenizer # In[2]: def stopwordslist():#加载停用词表 stopwords = [line.strip() for line in open('stopwords.txt',encoding='utf-8').readlines()] return stopwords # In[3]: def deleteStop(sentence): #去停用词 stopwords = stopwordslist() outstr="" for word in sentence: if word not in stopwords and word!="\n": outstr+=word return outstr # In[4]: def wordcut(Review): Mat=[] for rec in Review: seten=[] rec=re.sub('[%s]'%re.escape(string.punctuation),'',rec) fenci=jieba.lcut(rec) #精准模式分词 stc=deleteStop(fenci) #去停用词 seg_list=pseg.cut(stc) #标注词性 for word,flag in seg_list: if flag not in ["nr","ns","nt","m","f","ul","l","r","t"]: seten.append(word) Mat.append(seten) return Mat # In[5]: df=pd.read_csv('data.csv') df.head() # In[6]: #查看数据形状 df.shape # In[7]: #快速了解数据的结构 df.info() # In[8]: #查看每一列的标题 df.columns # In[9]: df.productId # In[10]: #查看有没有两行完全一样的数据 df.duplicated() # In[11]: #把两行完全一样的数据显示出来 df[df.duplicated()] # In[12]: #查看有没有questionId完全一样的两行 df.duplicated(subset=['questionId']) # In[13]: #把questionId完全一样的两行显示出来 df[df.duplicated(subset=['questionId'])] # In[14]: #查看所有带数字的信息 df.describe().T #查看数据形状 df.shape # In[19]: #把空的信息找出来 df.isnull().sum() # In[20]: #找出questions空信息所在的行 df[df.questions.isnull()].index # In[21]: #把questions空的行删除 df.drop(df[df.questions.isnull()].index,inplace=True) # In[22]: #查看数据形状 df.shape # In[23]: col=df.questions.values # In[24]: #删除questions列的所有空格 df.questions=[x.strip() for x in col] df.questions # In[25]: #查看数据结构 df.info() # In[26]: #查看带有?符号的问题 df[df['questions'].str.contains("\?")] # In[27]: #去除问题中的问号 df['questions'].replace('\?','',regex=True,inplace=True) # In[28]: #查看是否已经去除干净 df[df['questions'].str.contains("\?")] # In[29]: #找出含有♀符号的问题 df[df['questions'].str.contains("♀")] # In[30]: #删除问题中所有♀符号 df['questions'].replace('♀','',regex=True,inplace=True) # In[31]: #删除问题中各种特殊符号 df['questions'].replace('!','',regex=True,inplace=True) df['questions'].replace('@','',regex=True,inplace=True) df['questions'].replace('Q_Q','',regex=True,inplace=True) df['questions'].replace('_','',regex=True,inplace=True) df['questions'].replace('^','',regex=True,inplace=True) df['questions'].replace('你好','',regex=True,inplace=True) df['questions'].replace('在吗','',regex=True,inplace=True) df['questions'].replace('\n','',regex=True,inplace=True) df['questions'].replace('(`н′)','',regex=True,inplace=True) df['questions'].replace('╭(╯3╰)╮','',regex=True,inplace=True) # In[32]: #df[df['questions'].str.len()<4].index #找出问题中全是数字的索引 df[df['questions'].str.isdecimal()].index # In[33]: #删除问题中全是数字的行 df.drop(df[df['questions'].str.isdecimal()].index,inplace=True) # In[34]: #删除问题中小于三个字的行 df.drop(df[df['questions'].str.len()<3].index,inplace=True) # In[35]: #df[df['questions'].str.encode('UTF-8').isalpha()] #查看数据结构 df.shape # In[36]: #去除问题中只有英文字母的行 eeee=df['questions'].apply(lambda x:None if str(x).encode('UTF-8').isalpha()==True else x) # In[37]: df['questions']=eeee # In[38]: df.dropna(inplace=True) # In[39]: #查看数据结构 df.shape # In[40]: #保存文件 df.to_csv(r'C:\Users\D\Desktop\新data.csv',index=None) # In[ ]: # In[41]: #这里出来是questions的集合 def getquestions(data): listquestions=[] for questions in data['questions']: listquestions.append(questions) return listquestions # In[42]: #调用函数 questions=getquestions(df) # In[43]: #分词和去停用词 questionscut=wordcut(questions) # In[44]: print(questionscut) # In[45]: #写入文件 file=open('questionscut.txt','w',encoding='UTF-8') for i in questionscut: file.write(" ".join(i)) file.write('\n') file.close() # In[46]: #把列表合并成一个 abc=[] for i in questionscut: abc+=i print(abc) # In[47]: transformer = TfidfVectorizer() X_train = transformer.fit_transform(abc) # In[62]: word_list = transformer.get_feature_names()#所有统计的词 print(transformer.fit(abc).vocabulary_)#统计词字典形式 # In[48]: #TFIDF权重 weight_train = X_train.toarray() tfidf_matrix = transformer.fit_transform(abc) print(tfidf_matrix.toarray()) # In[49]: #生成TFIDF矩阵 vectorizer=CountVectorizer() X=vectorizer.fit_transform(abc) transform=TfidfTransformer() tfidf=transform.fit_transform(X) weight=tfidf.toarray() # In[50]: transformer = TfidfVectorizer() X_train = transformer.fit_transform(abc) print(X_train) # In[51]: corpus=[] lines=open('questionscut.txt',encoding='UTF-8').readlines() for line in lines: corpus.append(line.strip()) # In[52]: #输出TFIDF权重 vectorizer=CountVectorizer() aaaa=vectorizer.fit_transform(corpus) transform=TfidfTransformer() tfidf=transform.fit_transform(aaaa) weight=tfidf.toarray() print(tfidf) # In[53]: transformer = TfidfVectorizer() X_train = transformer.fit_transform(corpus) space=vectorizer.vocabulary_ print(space) # In[54]: file=open('分词.txt','w',encoding='UTF-8') for i in space: file.write(" ".join(i)) file.write('\n') file.close() # In[78]: mmm=pd.DataFrame(weight) mmm.to_csv('a.txt') # In[82]: #TFIDT矩阵降维 def PCA(weight,dimension): from sklearn.decomposition import PCA pca=PCA(n_components=dimension) x=pca.fit_transform(weight) print(x) return x # In[85]: xyz=PCA(weight,20) # In[86]: #保存矩阵 mmm=pd.DataFrame(xyz) mmm.to_csv('tfidf.txt') # In[63]: #词频统计 abcd=pd.DataFrame(abc,columns=['word']) abcd['cnt']=1 g=abcd.groupby(['word']).agg({'cnt':'count'}).sort_values('cnt',ascending=False) g.head(100) # In[62]: file=open('分词.txt','w',encoding='UTF-8') for i in g: file.write(" ".join(i)) file.write('\n') file.close() # In[66]: #词频统计 counter = Counter(abc) print(counter)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
- 478
- 479
- 480
- 481
- 482
- 483
- 484
- 485
- 486
- 487
- 488
- 489
- 490
- 491
- 492
- 493
- 494
- 495
- 496
- 497
- 498












-
相关阅读:
stack和queue的模拟实现
C#和Python使用C++编译的dll
【QCustomPlot】下载
C Primer Plus(6) 中文版 第9章 函数 9.3 递归
Win10管理员权限怎么获取?Win10取得管理员权限的方法
Qt5开发及实例V2.0-第十四章-Qt多国语言国际化
TempleteJDBC和Mybatis混合使用注意事项
Alad de Qnget
行业专网对比公网,优势在哪儿?能满足什么特定要求?
用DBCC checkcatalog(数据库)检测出结构异常
- 原文地址:https://blog.csdn.net/newlw/article/details/126847144
