-
SpringBatch(9):ItemReader详解
文章目录
前言
SpringBatch用于数据的批处理,那么它包含数据的输入ItemReader,处理ItemProcessor,输出ItemWriter。
第一节 ItemReader
ItemReader提供了多种数据输入的方式。包含文件读取, xml读取,db读取,mq读取,jms读取等一系列的操作方式。

第二节 简单的ItemReader入门
- 实现ItemReader接口,从传入的list逐个遍历
package com.it2.springbootspringbatch01.itemreader; import org.springframework.batch.item.ItemReader; import org.springframework.batch.item.NonTransientResourceException; import org.springframework.batch.item.ParseException; import org.springframework.batch.item.UnexpectedInputException; import java.util.Iterator; import java.util.List; public class MyItemReader implements ItemReader<String> { private Iterator<String> iterator; public MyItemReader(List<String> list) { this.iterator = list.iterator(); } @Override public String read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException { //一条一条读取 if (iterator.hasNext()) { String str= iterator.next(); System.out.println("获取到数据:"+str); return str; } return null; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 使用自定义的ItemReader读取数据并打印
package com.it2.springbootspringbatch01.itemreader; import lombok.extern.slf4j.Slf4j; import org.springframework.batch.core.Job; import org.springframework.batch.core.Step; import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.item.ItemReader; import org.springframework.batch.item.ItemWriter; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import java.util.Arrays; import java.util.List; @Configuration @EnableBatchProcessing @Slf4j public class ItemReaderDemo { //注入任务对象工厂 @Autowired private JobBuilderFactory jobBuilderFactory; //任务的执行由Step决定,注入step对象的factory @Autowired private StepBuilderFactory stepBuilderFactory; //创建Job对象 @Bean public Job jobDemo12() { return jobBuilderFactory.get("jobDemo12") .start(step12()) .build(); } //创建Step对象 @Bean public Step step12() { return stepBuilderFactory.get("step12") .<String,String>chunk(2) .reader(dataReader()) .writer(new ItemWriter<String>() { @Override public void write(List<? extends String> list) throws Exception { System.out.println("输出list"); for(String s:list){ System.out.println(s); } } }) .build(); } @Bean public ItemReader<String> dataReader() { List<String> list= Arrays.asList("a1","b2","c3","d4","e5"); return new MyItemReader(list); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 启动服务器执行,可以看到ItemReader逐条获取数据的日志。

第三节 JdbcPagingItemReader从数据库中读取数据
1. 准备数据
首先在数据库中创建user表,并插入数据

2. 查询数据
- 编写实体类(我们需要最终将数据转换成User)
package com.it2.springbootspringbatch01.itemreaderdb; import lombok.Data; @Data public class User { private int id; private String name; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 读取数据
package com.it2.springbootspringbatch01.itemreaderdb; import com.alibaba.fastjson.JSONObject; import com.it2.springbootspringbatch01.itemreader.MyItemReader; import lombok.extern.slf4j.Slf4j; import org.springframework.batch.core.Job; import org.springframework.batch.core.Step; import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.item.ItemReader; import org.springframework.batch.item.ItemWriter; import org.springframework.batch.item.database.JdbcPagingItemReader; import org.springframework.batch.item.database.Order; import org.springframework.batch.item.database.support.MySqlPagingQueryProvider; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.jdbc.core.RowMapper; import javax.sql.DataSource; import java.sql.ResultSet; import java.sql.SQLException; import java.util.Arrays; import java.util.HashMap; import java.util.List; import java.util.Map; @Configuration @EnableBatchProcessing @Slf4j public class ItemReaderDbDemo { //注入任务对象工厂 @Autowired private JobBuilderFactory jobBuilderFactory; //任务的执行由Step决定,注入step对象的factory @Autowired private StepBuilderFactory stepBuilderFactory; @Autowired private DataSource dataSource; //创建Job对象 @Bean public Job jobDemodb() { return jobBuilderFactory.get("jobDemodb") .start(step_db()) .build(); } //创建Step对象 @Bean public Step step_db() { return stepBuilderFactory.get("step_db") .<User,User>chunk(2) .reader(jdbcReader()) .writer(new ItemWriter<User>() { @Override public void write(List<? extends User> list) throws Exception { System.out.println("输出list"); for(User user:list){ System.out.println(JSONObject.toJSONString(user)); } } }) .build(); } @Bean public JdbcPagingItemReader<User> jdbcReader() { JdbcPagingItemReader<User> reader=new JdbcPagingItemReader<>(); reader.setDataSource(dataSource);//设置数据源 reader.setFetchSize(3); //设置每次抓取的数量(分页的大小) reader.setRowMapper(new RowMapper<User>() { //转换器,将ResultSet 转换为User对象 @Override public User mapRow(ResultSet rs, int rowNum) throws SQLException { User user=new User(); user.setId(rs.getInt("id")); user.setName(rs.getString("name")); return user; } }); MySqlPagingQueryProvider provider=new MySqlPagingQueryProvider(); provider.setSelectClause("id,name");//需要返回的字段 provider.setFromClause("from user"); //从什么表查 provider.setWhereClause("where id >3"); //条件 Map<String, Order> sort=new HashMap<>(); //排序 sort.put("id", Order.DESCENDING);//设置降序 provider.setSortKeys(sort); reader.setQueryProvider(provider);//设置sql查询相关信息 return reader; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
这里jdbcReader()是我们的核心,利用JdbcPagingItemReader读取数据
3. 启动服务器测试,可以看到控制台输出,从数据库中获取数据并打印出来。

第四节 FlatFileItemReader从文件中读取数据
1. 准备数据
这里在resources目录下存放了一个user.txt文件,里面包含5条用户信息。

id,name 1,xiaowang 2,xiaoli 3,xiaoming 4,kk 5,momo- 1
- 2
- 3
- 4
- 5
- 6
2. 读取数据
- 使用FlatFileItemReader读取数据
package com.it2.springbootspringbatch01.itemreaderfile; import com.alibaba.fastjson.JSONObject; import com.it2.springbootspringbatch01.itemreaderdb.User; import lombok.extern.slf4j.Slf4j; import org.springframework.batch.core.Job; import org.springframework.batch.core.Step; import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepScope; import org.springframework.batch.item.ItemReader; import org.springframework.batch.item.ItemWriter; import org.springframework.batch.item.file.FlatFileItemReader; import org.springframework.batch.item.file.builder.FlatFileItemReaderBuilder; import org.springframework.batch.item.file.mapping.DefaultLineMapper; import org.springframework.batch.item.file.mapping.FieldSetMapper; import org.springframework.batch.item.file.transform.DelimitedLineTokenizer; import org.springframework.batch.item.file.transform.FieldSet; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.io.ClassPathResource; import org.springframework.core.io.Resource; import org.springframework.validation.BindException; import javax.sql.DataSource; import java.util.List; @Configuration @EnableBatchProcessing @Slf4j public class ItemReaderFileDemo { //注入任务对象工厂 @Autowired private JobBuilderFactory jobBuilderFactory; //任务的执行由Step决定,注入step对象的factory @Autowired private StepBuilderFactory stepBuilderFactory; //创建Job对象 @Bean public Job jobDemofile() { return jobBuilderFactory.get("jobDemofile") .start(step_file()) .build(); } //创建Step对象 @Bean public Step step_file() { return stepBuilderFactory.get("step_file") .<User,User>chunk(2) .reader(fileReader2()) .writer(new ItemWriter<User>() { @Override public void write(List<? extends User> list) throws Exception { System.out.println("输出list"); for(User user:list){ System.out.println(JSONObject.toJSONString(user)); } } }) .build(); } @Bean @StepScope public FlatFileItemReader<User> fileReader2() { FlatFileItemReader reader=new FlatFileItemReader(); reader.setResource(new ClassPathResource("user.txt"));//设置要读取的文件位置 reader.setLinesToSkip(1);//跳过第一行,这里第一行是表头 //数据解析 DelimitedLineTokenizer tokenizer=new DelimitedLineTokenizer(); tokenizer.setNames(new String[]{"id","name"});//按照位置与文件中的字段对应 // tokenizer.setDelimiter(",");//设置分割字符串,默认是英文逗号,可以设置其它字符 //把解析的数据映射为对象 DefaultLineMapper<User> mapper=new DefaultLineMapper<>(); mapper.setLineTokenizer(tokenizer); mapper.setFieldSetMapper(new FieldSetMapper<User>() { @Override public User mapFieldSet(FieldSet fieldSet) throws BindException { User user=new User(); user.setId(fieldSet.readInt("id")); user.setName(fieldSet.readString("name")); return user; } }); mapper.afterPropertiesSet(); reader.setLineMapper(mapper);//行转换器 return reader; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 启动服务器,可以看到从user.txt读取到的数据,并进行了打印。

3. 分割符问题
默认分割符是英文逗号,如果被读取的文件的分割符号不是英文逗号,可以单独设定
tokenizer.setDelimiter("|");//将分割符号设定为|- 1

第五节 StaxEventItemReader从xml中读取数据
1. 准备数据

<users> <user> <id>1id> <name>xiaomingname> user> <user> <id>2id> <name>xiaoliname> user> <user> <id>3id> <name>xiaomingname> user> <user> <id>4id> <name>kkname> user> <user> <id>5id> <name>momoname> user> users>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2. 读取数据
- 引入依赖,需要要使用XStreamMarshaller做转换器
<dependency> <groupId>org.springframeworkgroupId> <artifactId>spring-oxmartifactId> dependency> <dependency> <groupId>com.thoughtworks.xstreamgroupId> <artifactId>xstreamartifactId> <version>1.4.11.1version> dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 编写实现
package com.it2.springbootspringbatch01.itemreaderxml; import com.alibaba.fastjson.JSONObject; import com.it2.springbootspringbatch01.itemreaderdb.User; import lombok.extern.slf4j.Slf4j; import org.springframework.batch.core.Job; import org.springframework.batch.core.Step; import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.item.ItemReader; import org.springframework.batch.item.ItemWriter; import org.springframework.batch.item.xml.StaxEventItemReader; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.io.ClassPathResource; import org.springframework.oxm.xstream.XStreamMarshaller; import java.util.HashMap; import java.util.List; import java.util.Map; @Configuration @EnableBatchProcessing @Slf4j public class ItemReaderXmlDemo { //注入任务对象工厂 @Autowired private JobBuilderFactory jobBuilderFactory; //任务的执行由Step决定,注入step对象的factory @Autowired private StepBuilderFactory stepBuilderFactory; //创建Job对象 @Bean public Job jobDemoxml() { return jobBuilderFactory.get("jobDemoxml") .start(step_xml()) .build(); } //创建Step对象 @Bean public Step step_xml() { return stepBuilderFactory.get("step_xml") .<User,User>chunk(2) .reader(xmlreader()) .writer(new ItemWriter<User>() { @Override public void write(List<? extends User> list) throws Exception { System.out.println("输出list"); for(User user:list){ System.out.println(JSONObject.toJSONString(user)); } } }) .build(); } @Bean public StaxEventItemReader<User> xmlreader() { StaxEventItemReader reader=new StaxEventItemReader(); reader.setResource(new ClassPathResource("user.xml")); reader.setFragmentRootElementName("user");//设置根标签,指的是数据标签XStreamMarshaller xStreamMarshaller=new XStreamMarshaller();//将xml转对象 Map<String,Class> map=new HashMap<>(); map.put("user",User.class); xStreamMarshaller.setAliases(map); reader.setUnmarshaller(xStreamMarshaller);//xml的转换器 return reader; } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 启动服务器,可以看到从xml中读取出来的数据。

第六节 多文件的读取MultiResourceItemReader
1. 准备数据

2. 读取文件
多文件的读取只是聚合了多个文件,但是实质也是按照顺序一个一个文件进行读取。
package com.it2.springbootspringbatch01.itemreadermultfile; import com.alibaba.fastjson.JSONObject; import com.it2.springbootspringbatch01.itemreaderdb.User; import lombok.extern.slf4j.Slf4j; import org.springframework.batch.core.Job; import org.springframework.batch.core.Step; import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepScope; import org.springframework.batch.item.ItemWriter; import org.springframework.batch.item.file.FlatFileItemReader; import org.springframework.batch.item.file.MultiResourceItemReader; import org.springframework.batch.item.file.mapping.DefaultLineMapper; import org.springframework.batch.item.file.mapping.FieldSetMapper; import org.springframework.batch.item.file.transform.DelimitedLineTokenizer; import org.springframework.batch.item.file.transform.FieldSet; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.io.ClassPathResource; import org.springframework.core.io.Resource; import org.springframework.validation.BindException; import java.util.List; @Configuration @EnableBatchProcessing @Slf4j public class ItemReaderMultFilerDemo { //注入任务对象工厂 @Autowired private JobBuilderFactory jobBuilderFactory; //任务的执行由Step决定,注入step对象的factory @Autowired private StepBuilderFactory stepBuilderFactory; @Value("classpath:/user_*.txt") //注入文件路径user_1.txt,user_2.txt private Resource[] resources; //创建Job对象 @Bean public Job jobDemoMultfile() { return jobBuilderFactory.get("jobDemoMultfile") .start(step_multfile()) .build(); } //创建Step对象 @Bean public Step step_multfile() { return stepBuilderFactory.get("step_multfile") .<User,User>chunk(2) .reader(multFileReader()) //指定文件读取器 .writer(new ItemWriter<User>() { @Override public void write(List<? extends User> list) throws Exception { System.out.println("输出list"); for(User user:list){ System.out.println(JSONObject.toJSONString(user)); } } }) .build(); } @Bean public MultiResourceItemReader<User> multFileReader(){ //聚合的读取器 MultiResourceItemReader<User> reader=new MultiResourceItemReader(); reader.setDelegate(fileReader()); //指定单个文件的读取方法 reader.setResources(resources); //指定资源,需要被读取的文件 return reader; } @Bean @StepScope public FlatFileItemReader<User> fileReader() { FlatFileItemReader reader=new FlatFileItemReader(); // reader.setResource(new ClassPathResource("user.txt"));//设置要读取的文件位置 reader.setLinesToSkip(1);//跳过第一行,这里第一行是表头 //数据解析 DelimitedLineTokenizer tokenizer=new DelimitedLineTokenizer(); tokenizer.setNames(new String[]{"id","name"});//按照位置与文件中的字段对应 // tokenizer.setDelimiter(",");//设置分割字符串,默认是英文逗号,可以设置其它字符 //把解析的数据映射为对象 DefaultLineMapper<User> mapper=new DefaultLineMapper<>(); mapper.setLineTokenizer(tokenizer); mapper.setFieldSetMapper(new FieldSetMapper<User>() { @Override public User mapFieldSet(FieldSet fieldSet) throws BindException { User user=new User(); user.setId(fieldSet.readInt("id")); user.setName(fieldSet.readString("name")); return user; } }); mapper.afterPropertiesSet(); reader.setLineMapper(mapper);//行转换器 return reader; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
启动服务器执行,可以看到user_1.txt和user_2.txt被读取了。

第七节 异常处理和重启
1. ItemStreamReader异常处理和重启
当进行批量读取的时候,可能处理到中间某个数据的时候出现异常,利用ItemStreamReader的处理机制,我们可以从发生问题的那一批数据重新开始处理,而不是重启之后再次从开头进行处理。
user.txt
id,name 1,xiaowang 2,xiaoli 3,xiaoming 4,kk 5,momo 6,liuliu 7,xiaohuang 8,mingming 9,xiaoxiao 10,dudu- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 下面我们读取user.txt,让自定义的Reader实现ItemStreamReader
package com.it2.springbootspringbatch01.restart; import com.it2.springbootspringbatch01.itemreaderdb.User; import org.springframework.batch.item.*; import org.springframework.batch.item.file.FlatFileItemReader; import org.springframework.batch.item.file.mapping.DefaultLineMapper; import org.springframework.batch.item.file.mapping.FieldSetMapper; import org.springframework.batch.item.file.transform.DelimitedLineTokenizer; import org.springframework.batch.item.file.transform.FieldSet; import org.springframework.core.io.ClassPathResource; import org.springframework.stereotype.Component; import org.springframework.validation.BindException; @Component public class RestartReader implements ItemStreamReader<User> { private FlatFileItemReader<User> reader = new FlatFileItemReader<>(); private Long curLine = 0L; private boolean restart = false; private ExecutionContext executionContext; public RestartReader() { reader.setResource(new ClassPathResource("user.txt"));//设置要读取的文件位置 reader.setLinesToSkip(1);//跳过第一行,这里第一行是表头 //数据解析 DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer(); tokenizer.setNames(new String[]{"id", "name"});//按照位置与文件中的字段对应 //把解析的数据映射为对象 DefaultLineMapper<User> mapper = new DefaultLineMapper<>(); mapper.setLineTokenizer(tokenizer); mapper.setFieldSetMapper(new FieldSetMapper<User>() { @Override public User mapFieldSet(FieldSet fieldSet) throws BindException { User user = new User(); user.setId(fieldSet.readInt("id")); user.setName(fieldSet.readString("name")); return user; } }); mapper.afterPropertiesSet(); reader.setLineMapper(mapper);//行转换器 } @Override public User read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException { User user = null; this.curLine++; if (restart) { reader.setLinesToSkip(this.curLine.intValue()); // reader.setLinesToSkip(this.curLine.intValue()-1);//如果没有表头则需要-1 restart = false; System.out.println("Start reading from line:" + this.curLine); } reader.open(this.executionContext); user = reader.read(); /** * 制造一个异常 */ if (null != user && user.getName().equals("liuliu")) { throw new RuntimeException("error .reader user id:" + user.getId()); } return user; } @Override public void open(ExecutionContext executionContext) throws ItemStreamException { this.executionContext = executionContext; if(executionContext.containsKey("curLine")){ this.curLine=executionContext.getLong("curLine"); this.restart=true; System.out.println("open Start reading from line :"+this.curLine); }else{ this.curLine=0L; executionContext.put("curLine",this.curLine); System.out.println("open Start reading from line :"+this.curLine+1); } } @Override public void update(ExecutionContext executionContext) throws ItemStreamException { executionContext.put("curLine", this.curLine); System.out.println("curLine:" + this.curLine); } @Override public void close() throws ItemStreamException { System.out.println("close curLine:" + curLine); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 定义Job和Step,将刚刚自定义的Reader注入进来。
package com.it2.springbootspringbatch01.restart; import com.alibaba.fastjson.JSONObject; import com.it2.springbootspringbatch01.itemreaderdb.User; import lombok.extern.slf4j.Slf4j; import org.springframework.batch.core.Job; import org.springframework.batch.core.Step; import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.item.ItemWriter; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import java.util.List; @Configuration @EnableBatchProcessing @Slf4j public class ItemReaderFileErrorDemo { //注入任务对象工厂 @Autowired private JobBuilderFactory jobBuilderFactory; //任务的执行由Step决定,注入step对象的factory @Autowired private StepBuilderFactory stepBuilderFactory; @Autowired private RestartReader restartReader; //创建Job对象 @Bean public Job jobDemofile_error() { return jobBuilderFactory.get("jobDemofile_error") .start(step_file_error()) .build(); } //创建Step对象 @Bean public Step step_file_error() { return stepBuilderFactory.get("step_file_error") .<User,User>chunk(4) .reader(restartReader) .writer(new ItemWriter<User>() { @Override public void write(List<? extends User> list) throws Exception { System.out.println("输出list"); for(User user:list){ System.out.println(JSONObject.toJSONString(user)); } } }) .build(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
通过观察我们发现,在处理第二批数据时会抛出异常,并停止。

- 启动服务器,观察以下运行日志,可以看到第1个chunk有输出打印,而第2个chunk读取到id为6的记录时,抛出了异常并停止。通过观察数据库batch_step_execution_context(step的上下文对象),我们发现curLine=4,处理进度已经持久化到数据库了。


- 修改数据,不让其抛出异常
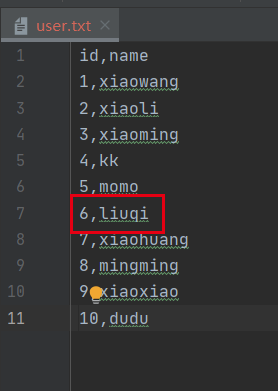
- 当我们改变了数据之后,异常将不会发生,此时再次启动服务器,可以看到它读取的数据是接着上一次的,而不是从头再读取一遍。

查看数据库,进度已经更新到11,那么下次读取就可以从此位置继续任务。

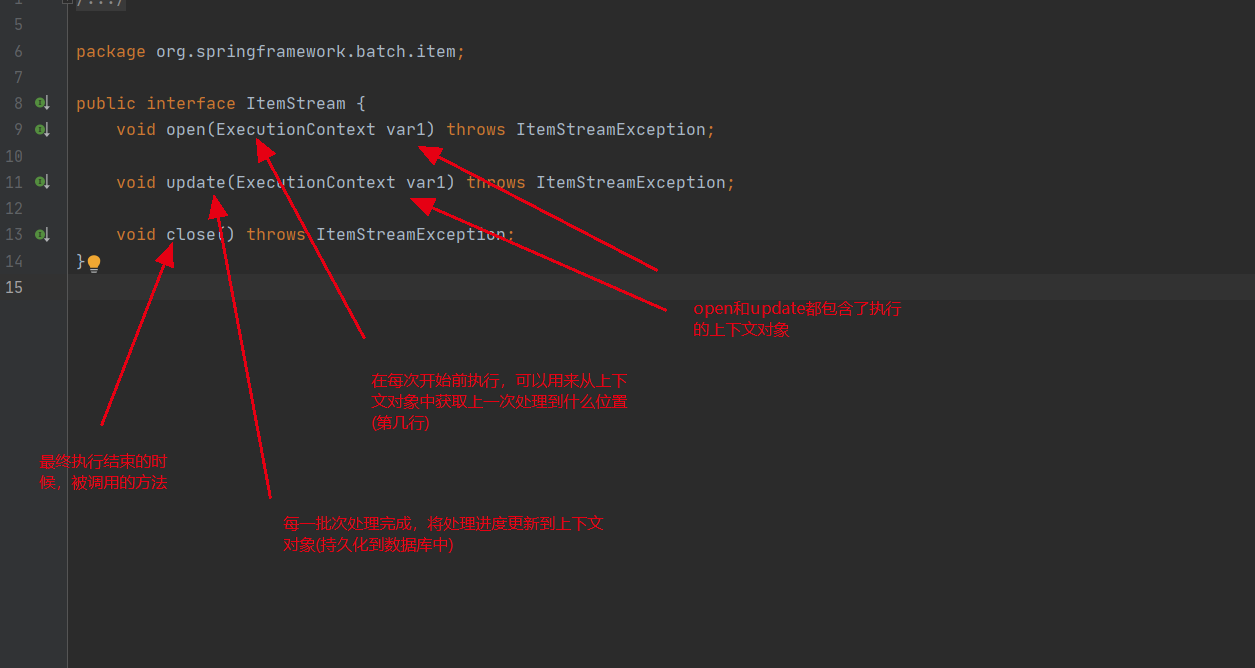
2. ItemStreamReader源码解读
ItemStreamReader继承了两个接口ItemStream, ItemReader,而ItemReader就是之前我们的读取数据用的。它只提供了一个reader方法。


那么重点就是ItemStream这个接口,update是按照一个chunk为一个单位的调用,当一个chunk处理结束,执行update(ExecutionContext),把进度储存到ExecutionContext之中,那么假设下一chunk read失败,当再次执行(open)时,可以通过ExecutionContext中记录的进度,接着之前的任务进行处理,而不是从0开始,再重复之前的任务。
第八节 ItemReader的庞大家族
ItemReader的子类很庞大,它还提供了处理MQ,JSON,DB,JMS等相关的Reader。当然它的MQ相关的Reader类并不能覆盖所有的MQ中间件,我们可以按照它已经有的实现类,类比写出对应的XXXItemReader。

-
相关阅读:
通过流量安全分析发现主机异常
Android 固定WIFI热点路由IP
检测docker内存状态脚本
【元宇宙】数字孪生,为智能社会赋能
WPF 属性触发器示例
Mysql为何不推荐写多表SQL
Hi3861 业务代码编写框架
k8s-服务网格实战-入门Istio
储能领域 / 通讯协议 / 技术栈 等专有名字集锦——主要收集一些储能领域的专有名词,以及相关的名词
AI爆文变现脚本:0基础小白的保姆级操作教程-更新迭代
- 原文地址:https://blog.csdn.net/u011628753/article/details/126841825