-
基于RNN的短期股票预测
1.数据集来源
本文数据集是通过python中tushare模块下载的股票日k线数据,本次数据只用来了其中的开盘价格
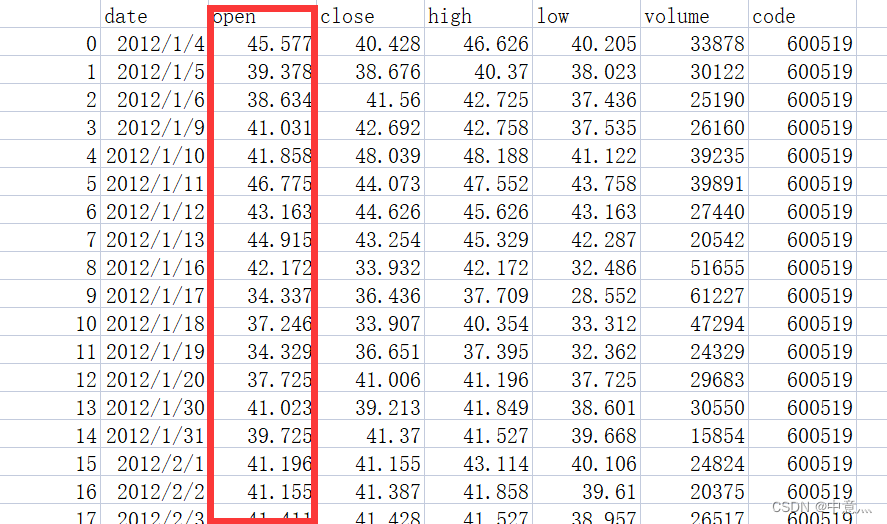
tushare模块简介
导入tushare
import tushare as ts这里注意, tushare版本需大于1.2.10
设置token
ts.set_token('your token here')以上方法只需要在第一次或者token失效后调用,完成调取tushare数据凭证的设置,正常情况下不需要重复设置。也可以忽略此步骤,直接用pro_api('your token')完成初始化,但这里的token需要自己去官网申请(注册即可得到)
初始化pro接口
pro = ts.pro_api()调取数据
ts.get_k_data()get_k_data含义是获取k线数据,所以起了这么一个简单的名称。虽然一贯的不标准,不规范,但主要看气质,主要看数据。 新接口融合了get_hist_data和get_h_data两个接口的功能,即能方便获取日周月的低频数据,也可以获取5、15、30和60分钟相对高频的数据。同时,上市以来的前后复权数据也能在一行代码中轻松获得,当然,您也可以选择不复权。
主要参数说明
- code 证券代码:支持沪深A、B股支持全部指数支持ETF基金
- ktype 数据类型:默认为D日线数据D=日k线 W=周 M=月 5=5分钟 15=15分钟 30=30分钟 60=60分钟
- autype 复权类型:qfq-前复权 hfq-后复权 None-不复权,默认为qfq
- index 是否为指数:默认为False设定为True时认为code为指数代码
- start 开始日期 format:YYYY-MM-DD 为空时取当前日期
- end 结束日期 :format:YYYY-MM-DD
数据属性说明
- date 日期和时间低频数据时为:YYYY-MM-DD高频数为:YYYY-MM-DD HH:MM
- open开盘价 close收盘价
- high最高价
- low最低价
- volume成交量
- code证券代码
2.代码
模型内部参数大家可自己调试,我的参数不一定是最优的
- # -*- coding: utf-8 -*-
- # @Time : 2022/9/13 16:05
- # @Author : 中意灬
- # @QQ NUM : 978593353
- # @FileName: 基于RNN的股票预测.py
- # @Software: PyCharm
- '''第一步:导入相关的库'''
- import os.path
- import tushare as ts
- import numpy as np
- import tensorflow as tf
- from tensorflow.keras.layers import Dense,SimpleRNN,Dropout
- import matplotlib.pyplot as plt
- import pandas as pd
- from tensorflow.keras import Model
- from sklearn.preprocessing import MinMaxScaler
- from sklearn.metrics import mean_squared_error,mean_absolute_error
- import math
- '''第二步:准备数据'''
- datapath='./data.csv'
- if os.path.exists(datapath):
- print('==========load data==========')
- data = pd.read_csv('./data.csv')
- training_set = data.iloc[0:2427 - 300, 2:3].values #前(2427-300=2127)天的开盘价作为训练集,表格从0开始计数,2:3 是提取[2:3)列,前闭后开,故提取出C列开盘价
- test_set = data.iloc[2427 - 300:, 2:3].values #后三百天作为测试集
- else:
- ts.set_token('f9e62b42d9f31fbf0267d9ba52204d37c5fef60f3d6091e9820c40a1') #这儿的token需要自己去turshare注册申请
- df=ts.get_k_data('600519',ktype='D',start='2012-01-01',end='2022-01-01')
- df.to_csv(datapath)
- data = pd.read_csv('./data.csv')
- training_set = data.iloc[0:2427 - 300, 2:3].values
- test_set = data.iloc[2427 - 300:, 2:3].values
- #归一化
- sc=MinMaxScaler(feature_range=(0,1))#定义归一化:归一化到(0-1)之间
- training_set_scaler=sc.fit_transform(training_set)# 求得训练集的最大值,最小值这些训练集固有的属性,并在训练集上进行归一化
- test_set=sc.transform(test_set)# 利用训练集的属性对测试集归一化
- x_train=[]
- x_test=[]
- y_train=[]
- y_test=[]
- #利用for循环,遍历整个训练集,将训练集中连续60天的数据作为训练特征x_train,第61天的数据作为训练标签y_train
- for i in range(60,len(training_set_scaler)):
- x_train.append(training_set_scaler[i-60:i,0])
- y_train.append(training_set_scaler[i,0])
- #将训练特征和标签转换神经网络的输入格式,使x_train符合RNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。
- x_train,y_train=np.array(x_train),np.array(y_train)
- x_train=np.reshape(x_train,(len(x_train),60,1))
- #利用for循环,遍历整个训练集,将测试集中连续60天的数据作为测试特征x_train,第61天的数据作为测试标签y_train
- for i in range(60,len(test_set)):
- x_test.append(test_set[i-60:i,0])
- y_test.append(test_set[i,0])
- #将测试特征和标签转换神经网络的输入格式,使x_test符合RNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。
- x_test,y_test=np.array(x_test),np.array(y_test)
- x_test=np.reshape(x_test,(len(x_test),60,1))
- #对训练集进行打乱
- np.random.seed(3)
- np.random.shuffle(x_train)
- np.random.seed(3)
- np.random.shuffle(y_train)
- """第三步:使用class类搭建神经网络结构"""
- class StockRNN(Model):
- def __init__(self):
- super(StockRNN, self).__init__()
- self.r1=SimpleRNN(256,activation='tanh',return_sequences=True)#因为下一层依然是RNN,所以选择True,将每个时间步的ht都送入下一层
- self.d1=Dropout(0.2)
- self.r2=SimpleRNN(100,activation='tanh',return_sequences=False)
- self.d2=Dropout(0.2)
- self.f1=Dense(1)
- def call(self,x):
- x=self.r1(x)
- x=self.d1(x)
- x=self.r2(x)
- x=self.d2(x)
- x=self.f1(x)
- return x
- model=StockRNN()
- '''第四步:使用model.compile配置网络参数'''
- model.compile(optimizer=tf.keras.optimizers.Adam(0.001),#自己设定adam的学习率,尽量先设置小,大了会收敛过快
- loss='mean_squared_error')#不必观察metrics值,没必要,只用观察loss值就可以
- checkpoint_save_path='./checkpoint/StockRNN.ckpt'
- if os.path.exists(checkpoint_save_path+'.index'):
- print('==========load the model==========')
- model.load_weights(checkpoint_save_path)
- cp_callback=tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
- save_weights_only=True,
- save_best_only=True,
- monitor='val_loss')
- """第五步:使用model.fit训练模型"""
- history=model.fit(x_train,y_train,batch_size=32,epochs=50,validation_data=(x_test,y_test),validation_freq=1,callbacks=[cp_callback])
- #参数提取
- file=open('./weights.txt','w')
- for v in model.trainable_variables:
- file.write(str(v.name)+'\n')
- file.write(str(v.shape)+'\n')
- file.write(str(v.numpy())+'\n')
- '''第六步:使用model.summary打印网络结构'''
- model.summary()
- #绘制loss图像
- plt.figure()
- plt.plot(history.history['loss'],label='loss')
- plt.plot(history.history['val_loss'],label='val_loss')
- plt.title('Train and Validation loss')
- plt.legend()
- plt.show()
- #模型预测
- predict_stock_openprice=model.predict(x_test)
- #对预测数据反归一化
- predict_stock_openprice=sc.inverse_transform(predict_stock_openprice)
- #对真实数据反归一化
- real_stock_openprice=sc.inverse_transform(test_set[60:])
- #可视化
- plt.figure()
- plt.plot(real_stock_openprice,color='r',label='real')
- plt.plot(predict_stock_openprice,color='b',label='predict')
- plt.legend()
- plt.show()
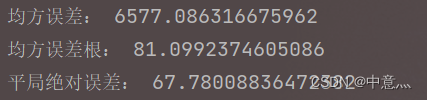
- ##模型预测效果量化,数值越小,效果越好
- #MSE 均方误差-->E[(预测值-真实值)^2]
- mse=mean_squared_error(predict_stock_openprice,real_stock_openprice)
- #RMSE 均方误差根-->sqrt(mse)
- rmse=math.sqrt(mean_squared_error(predict_stock_openprice,real_stock_openprice))
- #MAE 平均绝对误差-->E(|预测值-真实值|)
- mae=mean_absolute_error(predict_stock_openprice,real_stock_openprice)
- print('均方误差:',mse)
- print('均方误差根:',rmse)
- print('平局绝对误差:',mae)
- #对未知数据预测
- preNum=int(input('输入你要预测后多少个数据:'))
- a = test_set[len(test_set) - 60:, 0]
- c=[]#存储预测后的数据
- for i in range(preNum):
- b=np.reshape(a,(1,60,1))
- pre=model.predict(b)
- a=a.tolist()
- del a[0]
- a.extend(pre[0])
- c.extend(pre)
- a=np.array(a)
- test_set=np.array(test_set)
- c=sc.inverse_transform(c)
- plt.figure()
- plt.plot(sc.inverse_transform(test_set[60:]),color='b',label='real')
- x=np.arange(len(test_set[60:]),len(test_set[60:])+preNum)
- plt.plot(x,c,color='r')
- plt.plot(predict_stock_openprice,color='r',label='predict')
- plt.show()



但其实从对未知数据进行预测的结果便能看出,rnn存在一共缺点,就是无法长期预测,我们将预测得到的数据带入模型,对跟后面数据进行预测,会发现时间跨度一大,其预测结果就会变得离谱。
预测后20个数据
 预测后50个数据
预测后50个数据
-
相关阅读:
【BiLSTM-Adaboost预测】基于双向长短期记忆网络的Adaboost时间序列预测研究(matlab代码实现)
Rocky9.2基于http方式搭建局域网yum源
Javascript实现具有验证功能的页面登录
jdk 中的 keytool 的使用,以及提取 jks 文件中的公钥和私钥
前端如何处理后端一次性传来的10w条数据
一种在 Python 中实现更快 OpenCV 视频流的多线程方法
POSIX 真的不适合对象存储吗?
C语言经典面试题目(十四)
基于CS结构的即时通信系统的设计与实现(QT开发)
传智健康_第5章 预约管理-预约设置
- 原文地址:https://blog.csdn.net/qq_55977554/article/details/126849943
