-
【Python零基础入门篇 · 37】:正则基础
正则基础
导入模块:import re
math方法匹配
res = re.match(正则表达式,要匹配的字符串)
- re.match()从字符串的开始位置进行匹配,配对成功返回match对象。,没有匹配成功返回None
- 匹配到数据,使用group方法获取数据
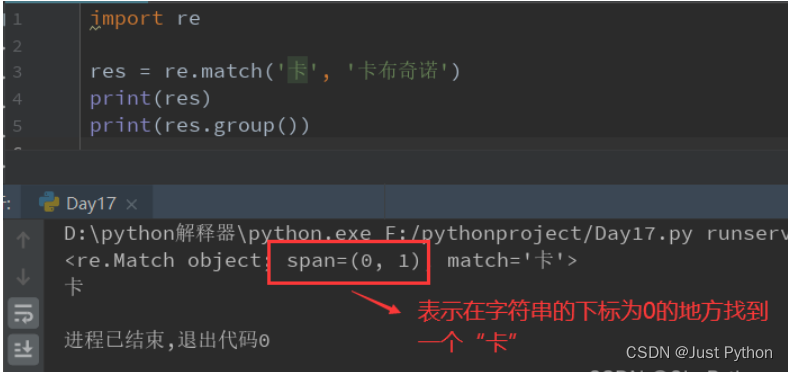
匹配单个字符
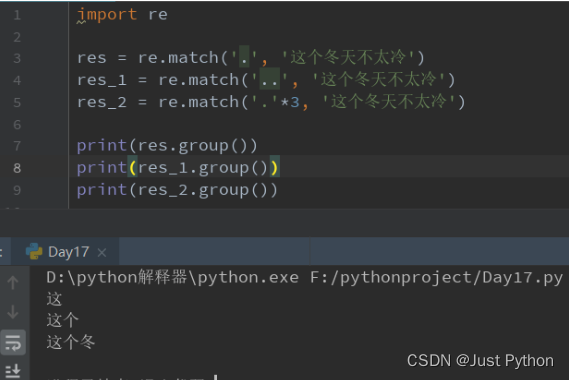
“.”——匹配任意一个字符(除了\n之外)
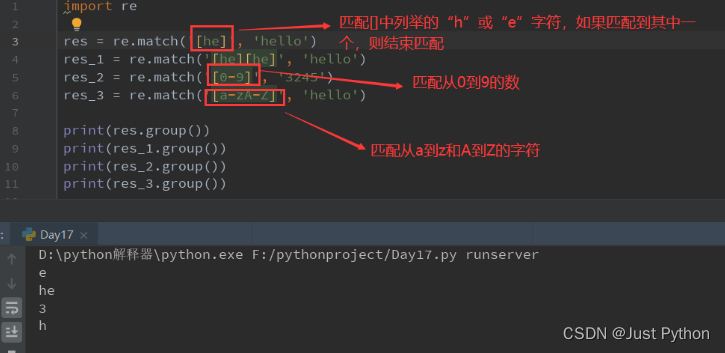
“[]”——匹配[]中列举的字符
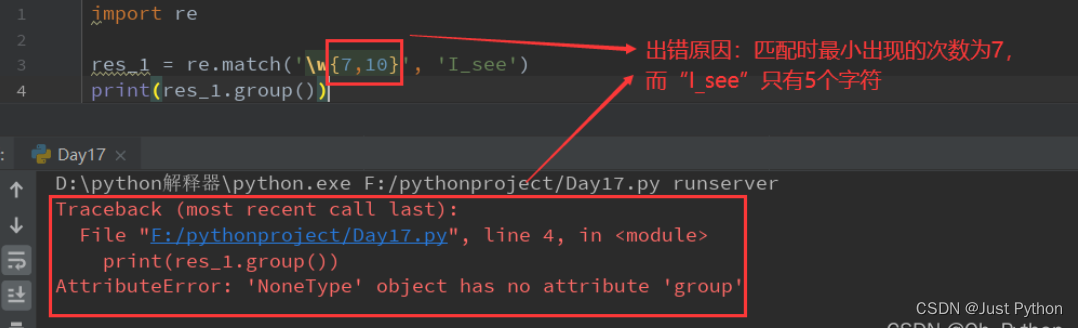
- 下图报错原因:由于没有匹配到元素,之后又调用了group()方法造成的。
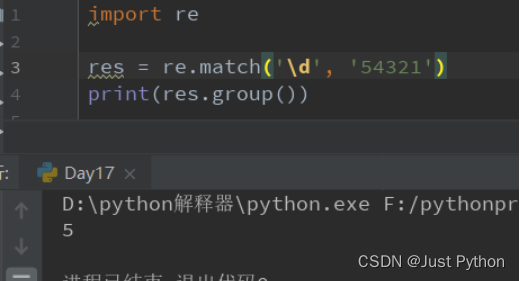
“\d”——匹配数字
0,1,2,3,4,5,6,7,8,9
“\D”——匹配非数字,即不是数字

“\s”——匹配空白,即空格和tab键

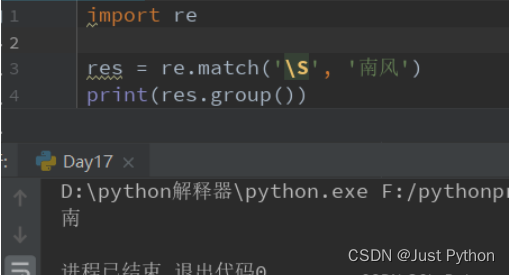
“\S”——匹配非空白
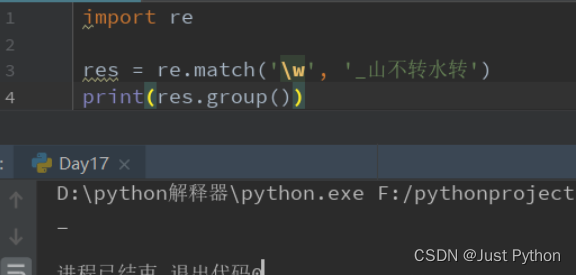
“\w”——匹配单词字符
a-z,A-Z,0-9,_(下划线),汉字
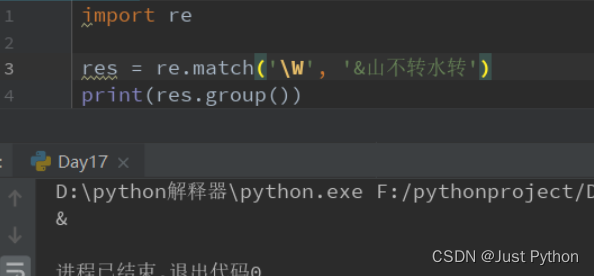
“\W”——匹配非单词字符
匹配多个字符
“ * ” ——匹配前一个字符出现0次或无限次

“ + ” ——匹配前一个字符出现一次或无限次
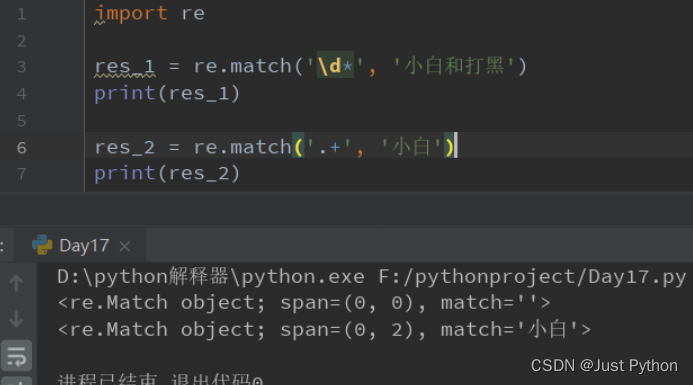
“ ?” ——匹配前一个字符出现一次或0次,即要么有一次,要么没有

“{m}” ——匹配前一个字符出现m次

“{m,n}”——匹配前一个字符出现从m次到n次(m
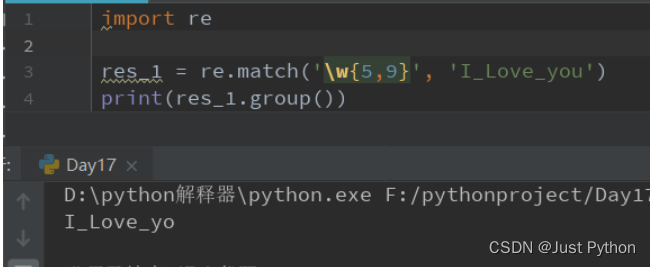
匹配开头结尾
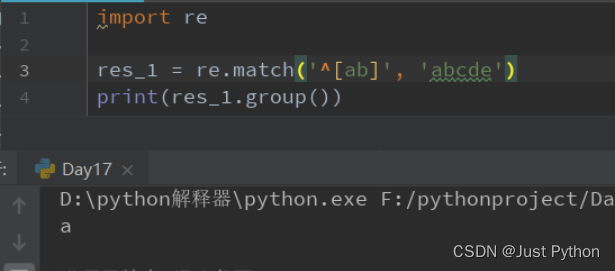
“ ^ ” ——匹配字符串开头
^表示以什么开头,表示对什么取反。

^在[]外表示由[]中的各个字符开头就匹配成功
^[ab] :表示以’a’或’b’开头就匹配成功
“ $ ” ——匹配字符串结尾
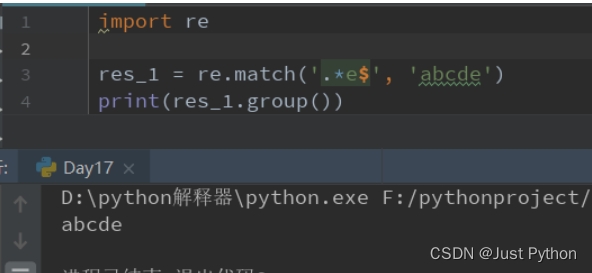


不匹配
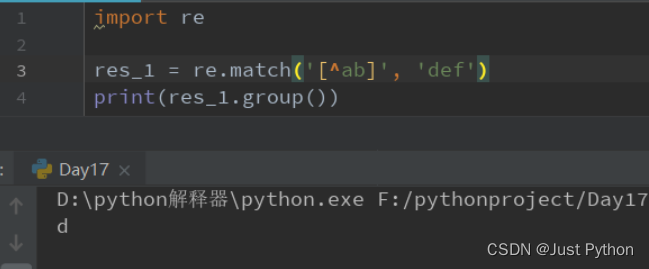
^在[]中表示不匹配
总结
- ‘abc’:表示字符串开头有abc就匹配成功
- ‘[abc]’:表示以字符串开头有’a’或’b’或’c’就匹配成功
- ‘^[abc]’:表示由’a’或’b’或’c’开头就匹配成功
- ‘[^abc]’:表示匹配除了’a’、‘b’、‘c’之外的字符
匹配分组
“ | ”——匹配左右任意一个表达式(从左到右进行匹配)

(ab)——括号中字符作为一个分组
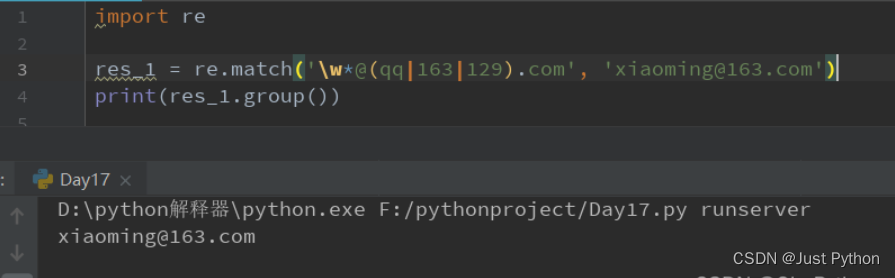
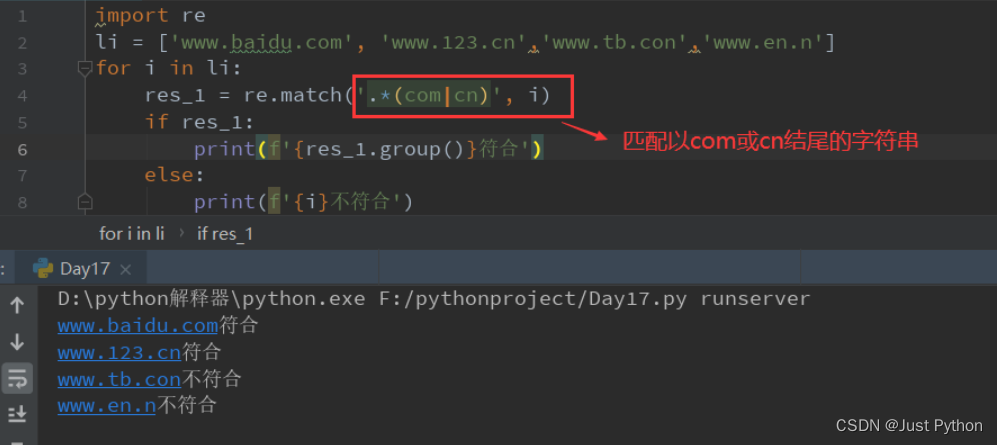
\num——引用分组num匹配到的字符串
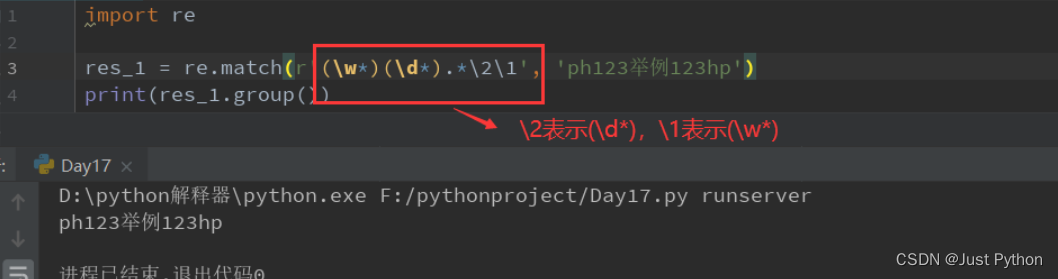
(?P
)分组起别名 (?P=name)引用别名为name分组匹配到的字符串

-
相关阅读:
视觉检测系统可以检测太阳能电池片哪些方面的缺陷?
【AWS】实操-保护 Amazon S3 VPC 终端节点通信
18个数据结构的作业
88Q2110 通过C22方式访问C45 phy地址
Java项目:ssm校园在线点餐系统源码
多输入多输出 | MATLAB实现PSO-BP粒子群优化BP神经网络多输入多输出
Jenkins自动化部署前后端分离项目 (svn + Springboot + Vue + maven)有图详解
JVM 参数及调优
第十七章:Java连接数据库jdbc(java和myql数据库连接)
ubuntu未开启ssh
- 原文地址:https://blog.csdn.net/Oh_Python/article/details/126813598