-
MySQL索引
索引对于数据库查询是非常重要的,能提高查询效率。在面试中也是经常被问到相关问题,所以了解并掌握它是非常必要的。
一、索引概述
1.简介:
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引
2.优缺点
优点:
1.提高数据检索的效率,降低数据库的IO成本。
2.通过索引列对数据进行排序,降低数据的排序成本,降低CPU的调度
缺点:
1.索引列会占用一定的内存空间
2.索引大大提高了查询效率,同时也降低更新表的速度,因为更新表数据的时候,也需要更新索引中记录。二、索引分类
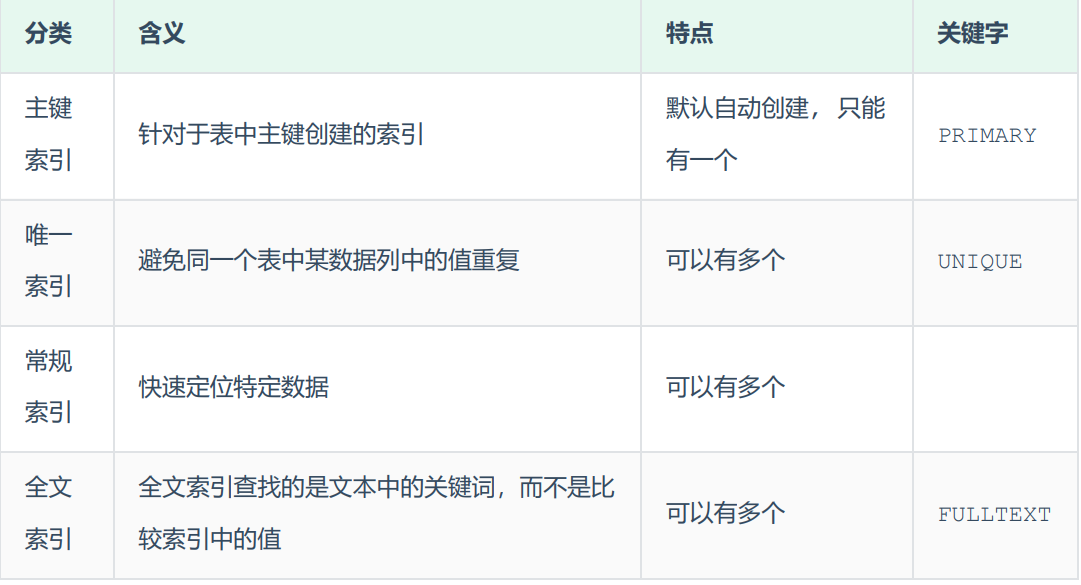
1.常规分类
在MySQL数据库,将索引的具体类型主要分为以下几类:主键索引、唯一索引、常规索引、全文索引。
2.存储方式分类
在InnoDB存储引擎中给,根据索引的存储形式,又可以分为以下两种:
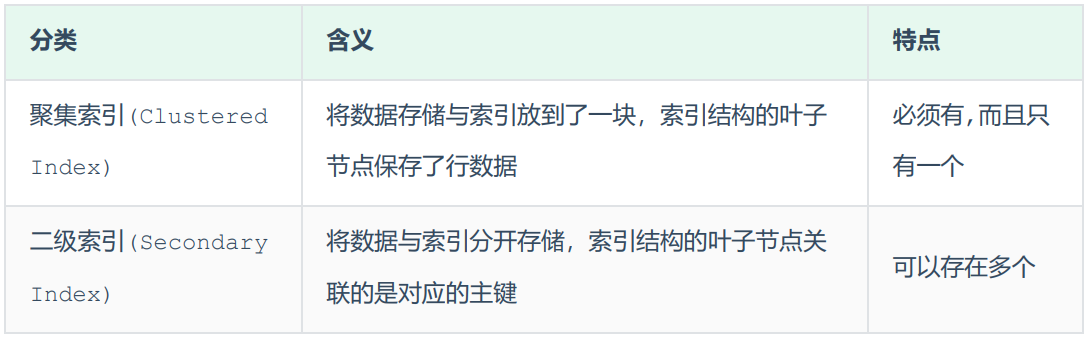
聚集索引选取规则:
a. 如果存在主键,主键索引就是聚集索引
b. 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引
c. 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生产一个rowid作为隐藏的聚集索引三、索引结构
1.概述
索引结构就是索引按哪种数据结构来构建的。MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的索引结构,主要包含以下几种:
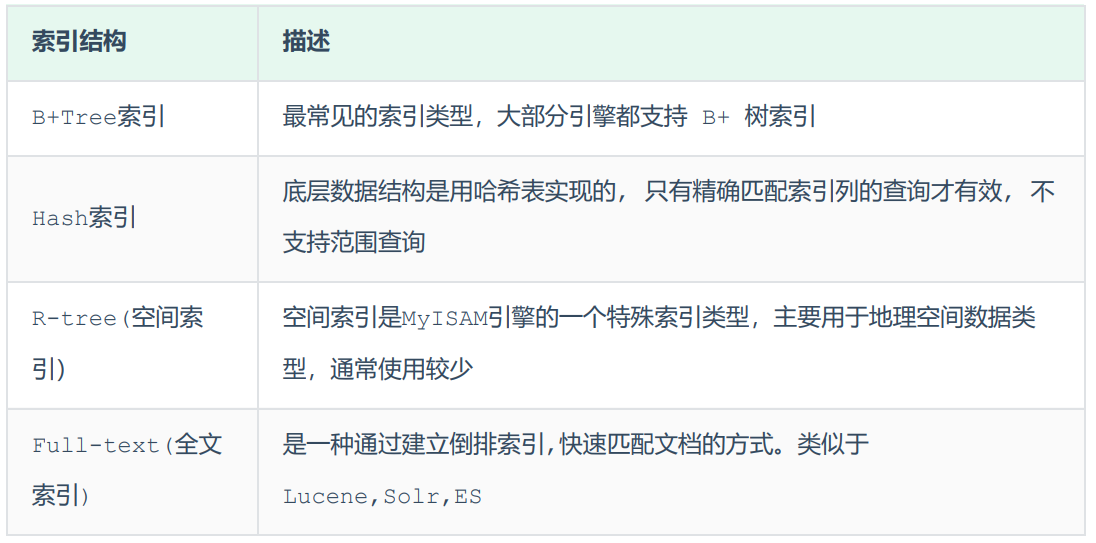
具体的各索引结构的特点,在本文细说的话就会占用很大的篇幅,就不进行详细说明了,大家可以去查阅相关数据结构进行深入了解2.思考:为什么大部分存储引擎采用B+树索引结构?
Ⅰ.对比二叉树
二叉树的顺序插入会形成链表,链表的搜索效率低。而B+树层级更少,搜索效率高。
下面以插入一段数字 ( 5 , 8 , 12 , 17 , 19 , 23 ) (5,8,12,17,19,23) (5,8,12,17,19,23)为例,观察两棵树的不同: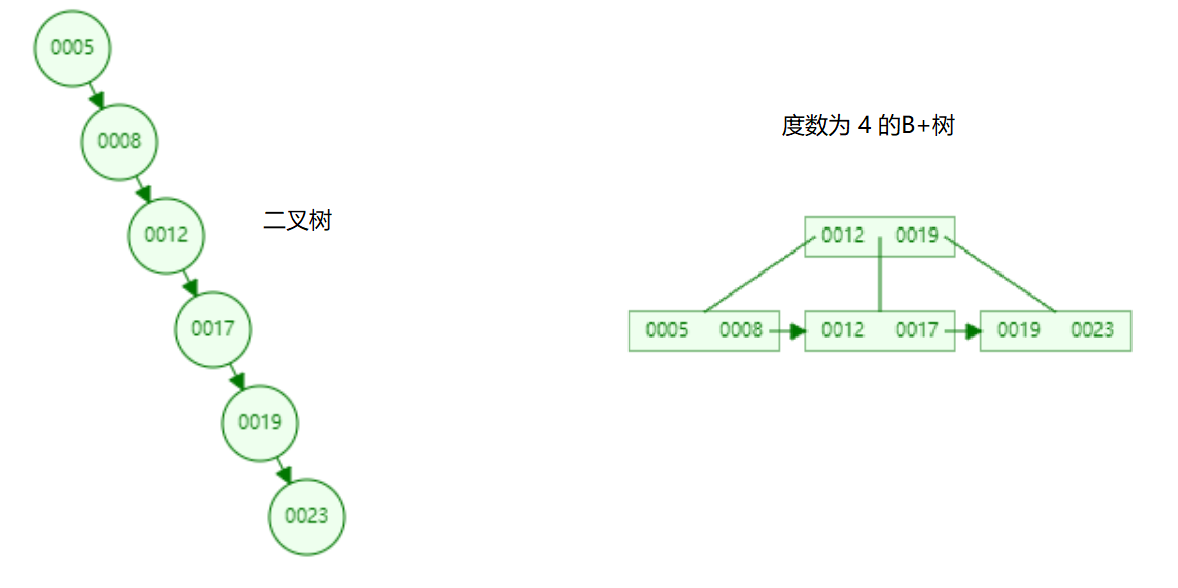
(B+树的插入过程可以在这个 链接 查看)
上图B+树高度为2,明显低于二叉树。Ⅱ.对比B树
对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低
插入数字 ( 5 , 7 , 9 , 11 , 12 , 14 , 17 , 20 , 25 , 31 , 33 , 35 , 38 , 40 , 52 ) (5,7,9,11,12,14,17,20,25,31,33,35,38,40,52) (5,7,9,11,12,14,17,20,25,31,33,35,38,40,52),观察两棵树的不同:
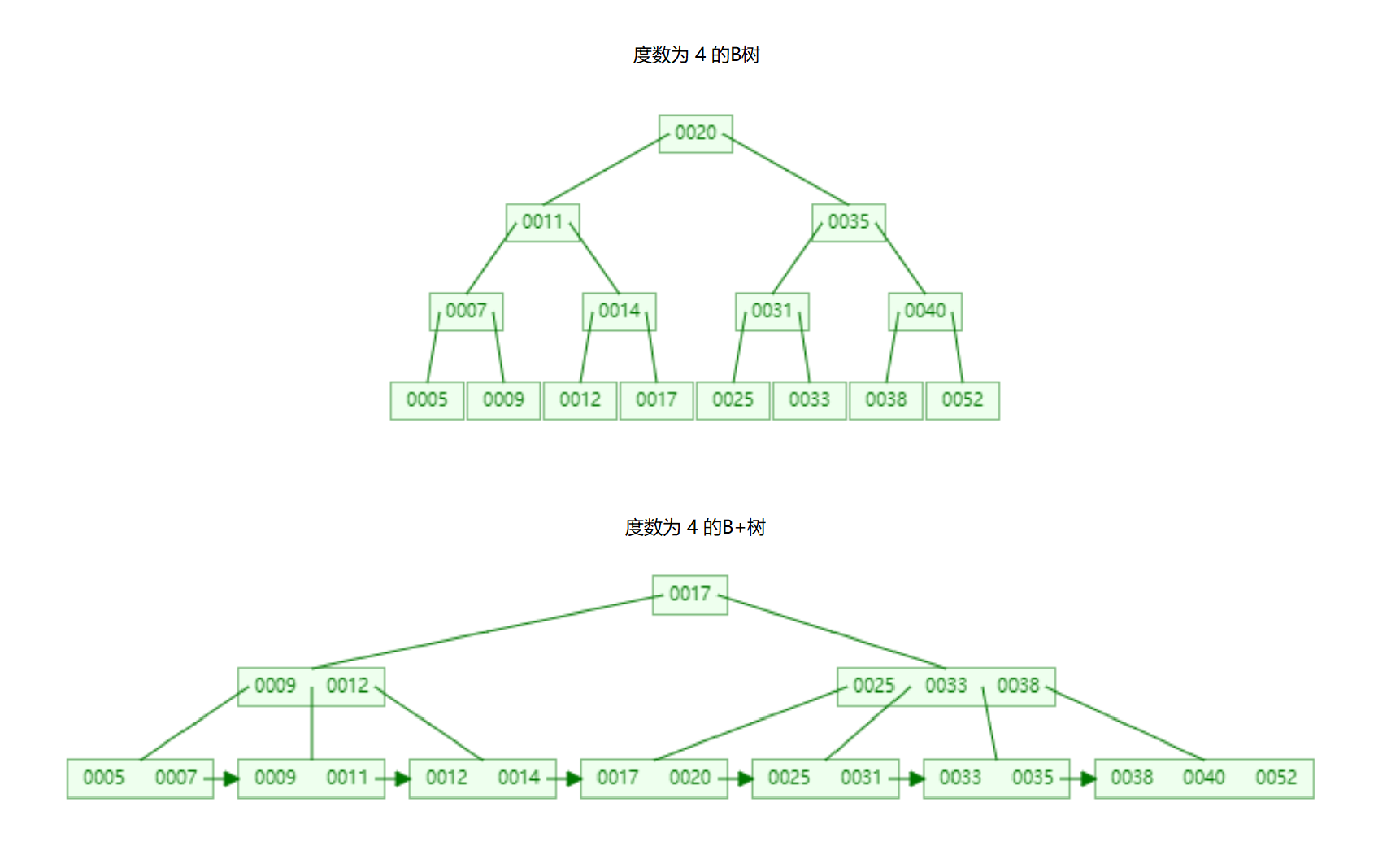
(B树的插入过程可以在这个 链接 查看)上图可以看出插入同样数据,最终得到的树的高度B+树更低,高度为3。
Ⅲ.对比Hash索引
哈希索引的每一列都有一个hash值,查询时,根据hash值可以一次就查到,效率非常高,但是hash索引不支持范围匹配和排序操作,而B+树索引支持。
大多业务需求都需要范围查询和排序,显然这时就需要B+树索引,毕竟B+树的查询效率也是很不错的。综上所述,在开发中我们可以不同表的不同需求,选择合适的存储引擎以及合适的索引结构。
四、索引语法:
1.创建索引
CREATE [UNIQUE|FULLTEXT] INDEX 索引名 ON 表名 (需要创建索引的列)- 1
例如用户表 tb_user有(id, name, age, gender, phone)字段。
我们可以建立:
1.name和gender的联合索引create index idx_name_gender on tb_user (name, gender);- 1
2.phone 的唯一索引(因为每个人的手机号都不同,就可以选择唯一索引)
create unique index idx_phone on tb_user (phone);- 1
我们应根据实际需求,为表建立合适的索引。
2.查看索引
SHOW INDEX FROM 表名;- 1
对刚才的tb_user表查看索引:
显示了 3 个索引,因为有第一条是创建表时,自动为主键创建的聚集索引。3.删除索引
DROP INDEX 索引名 ON 表名;- 1
执行以下语句:
drop index idx_phone on tb_user;- 1
再次查看索引就会发现索引 idx_phone 被删除了

五、索引使用原则
1.最左前缀法则:
* 如果索引了多列(联合索引),要遵循最左前缀法则。最左前缀法则指的是查询从索引最左列开始。
* 如果跳过最左边的列,则不会根据索引查询
* 如果跳跃某一列,索引将部分失效(后面的字段索引失效)假如tb_user表创建了 (name, age, gender) 的索引 idx_name_age_gender,进行以下操作:
select * from tb_user where name = '张三' and age = 18 and gender = '男';//会通过索引查询 select * from tb_user where name = '张三' and gender = '男'; //会通过索引查询,但跳过了age字段,gender就不会通过索引查询 select * from tb_user where name = '张三'; //会通过索引查询 select * from tb_user where age = 18; //不满足最左前缀法则,不通过索引查询- 1
- 2
- 3
- 4
2.范围查询:
联合索引中,出现范围查询(>,<),范围查询后面的列索引失效。以索引 idx_name_age_gender为例:
select * from tb_user where name = '张三' and age > 18 and gender = '男';//会通过索引查询,但只有name生效- 1
3.索引列运算:
不要在列上进行运算操作,否则索引将失效,比如函数运算(subtring等)。以索引 idx_name_age_gender为例:
select * from tb_user where name = substring(name,2);//不会通过索引查询- 1
4.模糊查询:
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。以索引 idx_name_age_gender为例:
select * from tb_user where name like '张三%';//会通过索引查询 select * from tb_user where name like '%张三';//不会通过索引查询- 1
- 2
5.字符串类型字段使用时不加引号,索引将失效
6.or连接的条件:
用or分割开的条件,如果or前的条件列有索引,而后面的没有索引,那么涉及的索引都不会被用到select * from tb_user where name = '张三' or phone = 15;//不会通过索引查询- 1
由于 or 后面的 phone 字段没有建立索引,所以整个SQL语句都不会通过索引查询
7.覆盖索引:
覆盖索引是指需要返回的列,在索引中都能找到。我们在查询时应尽量覆盖索引。
例如我们事先建立了(id, name, gender, phone) 字段的索引 idx_name_gender_phone。在某次查询中,查询的字段为(name,gender),这两个字段在索引idx_name_gender_phone中都能查到。那么我们我们就只需要在索引中查询一次。
若查询的字段为(name, age),那么我们在索引中通过name查到相应记录时,发现并没有age字段(因为索引中的字段为id,name,gender,phone),那么此时我们还需要通过索引中查到的 id,去整个表中二次通过 id 查询才能得到 age 字段,这个过程也叫回表查询。8.前缀索引:
当字段类型为字符串(varchar,text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率。此时可以只将字符串的一部分前缀建立索引,这样可以大大节约索引空间,从而提高索引效率。
语法:create index 索引名 on 表名 ( 列名(n) );//其中n表示提取前几个字符- 1
例如:
create index idx_phone_5 on 表名 ( phone(5) );//索引phone前5个字符作为索引- 1
其中的前缀长度n需要根据实际情况选取,原则是尽量短,尽量使截取后的字段唯一。
如果截取 phone 前 2 个字符,共100条记录,出现了20条 ‘17’ 的话,这是非常不理想的,就需要考虑截取更长的长度。六、索引设计原则
1.针对于数据量较大,且查询比较频繁的表建立索引。
2.针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
3.尽量选择区分度高(数据重复率低)的列作为索引,区分度越高,使用索引的效率越高。
4.如果是字符出类型的字段,且长度较长,可以建立前缀索引
5.尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
6.要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
7.如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器直到每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询
-
相关阅读:
Android App备案获取公钥、签名MD5值
Centos7安装redis详细步骤
2023年最佳研发管理平台评选:哪家表现出色?
opengl学习glBindAttribLocation
Debian12安装.NET7 SDK
初探flask debug生成pin码
P5143 攀爬者(快速排序)
Qt 读写文件(QFile&QTextStream&QDataStream) 详解
计算机网络笔记6应用层
金仓数据库KMonitor使用指南--3. 部署
- 原文地址:https://blog.csdn.net/Easenyang/article/details/126824472