-
c++inline关键字详解
前言
今天认识的一个学长,面试c++相关岗位,问到了一个inline的问题,感觉答的不是很好,后来在群里讨论下这问题,于是决定把inline知识点完完全全的梳理一遍。
问的问题是:
关于使用inline导致缓存命中率下降,进而使程序性能下降的问题
一、函数的调用
在学习inline关键字之前,我们还是有必要了解下函数的调用,明白函数调用的时间和空间开销,才能更好地理解inline关键字对效率的提高。
在了解函数的调用时,我们首先补充下栈的概念,毕竟函数的内部数据都是在栈中存放的。栈的概念和栈溢出
程序的虚拟地址空间分为多个区域,栈(Stack)是其中地址较高的一个区域。栈(Stack)可以存放函数参数、局部变量、局部数组等作用范围在函数内部的数据,它的用途就是完成函数的调用。 并且栈内存由系统自动分配和释放:发生函数调用时就为函数运行时用到的数据分配内存,函数调用结束后就将之前分配的内存全部销毁。所以局部变量、参数只在当前函数中有效,不能传递到函数外部。
从本质上来讲,栈是一段连续的内存,需要同时记录栈底和栈顶,才能对当前的栈进行定位。在现代计算机中,通常使用ebp寄存器指向栈底,而使用esp寄存器指向栈顶。随着数据的进栈出栈,esp 的值会不断变化,进栈时 esp 的值减小,出栈时 esp 的值增大。
对每个程序来说,栈能使用的内存是有限的,一般是 1M~8M,这在编译时就已经决定了,程序运行期间不能再改变。如果程序使用的栈内存超出最大值,就会发生栈溢出(Stack Overflow)错误。栈内存的大小和编译器有关,编译器会为栈内存指定一个最大值,在 VC/VS 下,默认是 1M,在 C-Free 下,默认是 2M,在 Linux GCC 下,默认是 8M。函数的调用过程
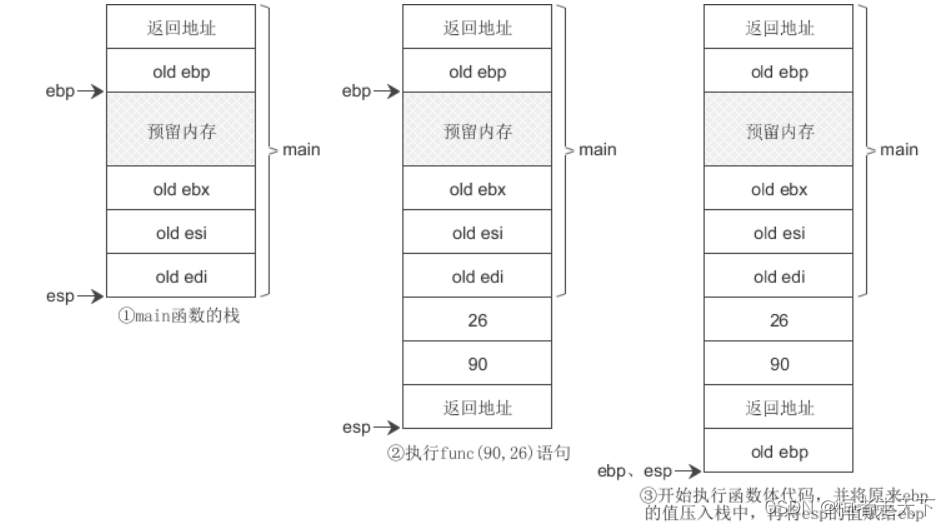
以下面代码为例,来进行阐述函数的调用过程
void func(int a, int b){ int p =12, q = 345; } int main(){ func(90, 26); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
函数使用默认的调用惯例 cdecl,即参数从右到左入栈。
函数调用过程如下图所示:
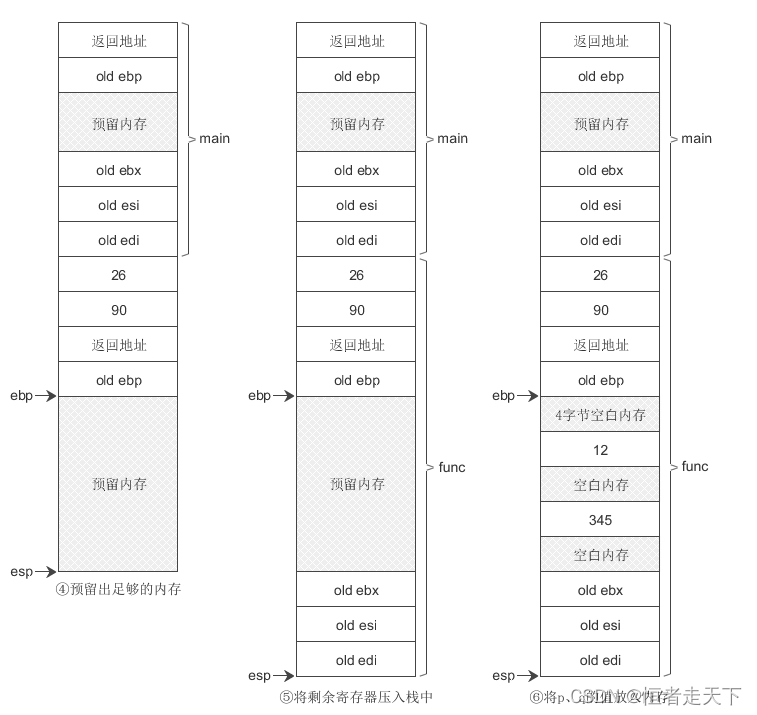
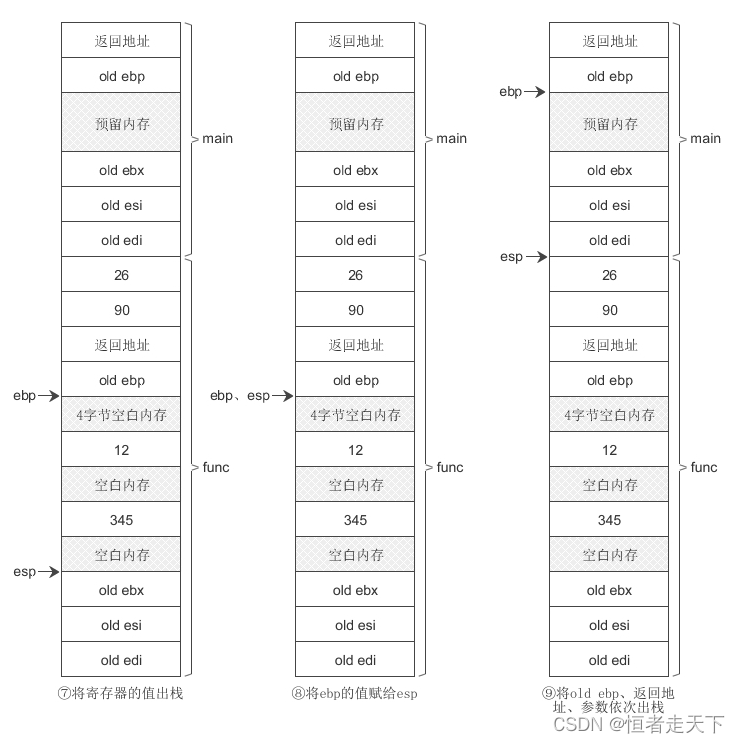
明白了函数调用是在栈上进行的,这里再补充一个常见的错误,栈溢出错误(栈攻击)栈溢出攻击
以如下代码为例:
#includeint main(){ char str[10] = {0}; gets(str); printf("str: %s\n", str); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
局部数组也是在栈上分配内存,当输入"12345678901234567890" 时,会发生数组溢出,占用“4字节空白内存”、“old ebp”和“返回地址”所在的内存,并将原有的数据覆盖掉,这样当 main() 函数执行完成后,会取得一个错误的返回地址,该地址上的指令是不确定的,或者根本就没有指令,所以程序在返回时出错。
二、为什么使用inline关键字
函数调用是有时间和空间开销的。 程序在执行一个函数之前需要做一些准备工作,要将实参、局部变量、返回地址以及若干寄存器都压入栈中,然后才能执行函数体中的代码;函数体中的代码执行完毕后还要清理现场,将之前压入栈中的数据都出栈,才能接着执行函数调用位置以后的代码。如果函数体代码比较多,需要较长的执行时间,那么函数调用机制占用的时间可以忽略;如果函数只有一两条语句,那么大部分的时间都会花费在函数调用机制上,这种时间开销就就不容忽视。
为了消除函数调用的时空开销, C++ 提供一种提高效率的方法,即在编译时将函数调用处用函数体替换,(解决一些频繁调用的小函数大量消耗栈空间(栈内存)的问题) 类似于C语言中的宏展开。这种在函数调用处直接嵌入函数体的函数称为内联函数(Inline Function),又称内嵌函数或者内置函数。三、内联函数原理
内联函数(inline function与一般的函数不同,它不是在调用时发生控制转移,而是在编译阶段将函数体嵌入到每一个调用该函数的语句块中。 内联函数(inline function) 与编译器的工作息息相关 。编译器会将程序中出现内联函数的 调用表达式用内联函数的函数体来替换。
即总之就是,内联是以代码膨胀(复制)为代价,仅仅省去了函数调用的开销,从而提高函数的执行效率。如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。四、内联函数的使用
要在函数定义处添加 inline 关键字,在函数声明处添加 inline 关键字虽然没有错,但这种做法是无效的,编译器会忽略函数声明处的 inline 关键字。
和宏一样,内联函数可以定义在头文件中(不用加 static 关键字),并且头文件被多次#include后也不会引发重复定义错误。这一点和非内联函数不同,非内联函数是禁止定义在头文件中的,它所在的头文件被多次#include后会引发重复定义错误。内联函数在编译时会将函数调用处用函数体替换,编译完成后函数就不存在了,所以在链接时不会引发重复定义错误。 这一点和宏很像,宏在预处理时被展开,编译时就不存在了。从这个角度讲,内联函数更像是编译期间的宏。因此可以用内联函数取代带参数的宏。还有在类体中定义的成员函数的规模一般都很小,而系统调用函数的过程所花费的时间开销相对是比较大的。调用一个函数的时间开销远远大于小规模函数体中全部语句的执行时间。为了减少时间开销,如果在类体中定义的成员函数中不包括循环等控制结构,C++系统会自动将它们作为内置(inline)函数来处理。
定义在类中的成员函数缺省都是内联的。如果在类中未给出成员函数定义,而又想内联该函数的话,需要在类外加上inline。如:class myclass { public: int Add(int x, int y ){ return x+y; }; //自动成为内联函数 }- 1
- 2
- 3
- 4
- 5
- 6
将成员函数的定义放在类声明之中,虽然书写方便,但不是一种良好的编程风格,上面可改为:
class myclass { public: int Add(int x, int y); }; //实现文件 inline int A::Foo(int x, int y ){ return x+y; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
虽然理论是这样的,但是在VS中使用这样的类成员函数,链接器会报错。所以最好还是写在头文件中。
virtual函数不能是inline的,virtual意味着知道运行期才确定调用哪个函数,而inline意味着执行前,先将调用动作替换为被调用函数的本体。虽然inline如此之好,但是使用,也是有条件的,如果滥用内联函数,会占用更多的内存空间或者占用更多的指令缓存,导致cpu 的指令缓存不够用的,这会导致 cpu 缓存命中率降低,反而可能会降低整个C语言程序的效率。
推荐一个零声学院免费公开课程,个人觉得老师讲得不错,
分享给大家:[Linux,Nginx,ZeroMQ,MySQL,Redis,
fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,
TCP/IP,协程,DPDK等技术内容,点击立即学习:服务器课程 -
相关阅读:
Go语言中结构体struct与字节数组[]byte的相互转换
罗丹明PEG羟基,RB-PEG-OH,Rhodamine-PEG-OH
第二章-H3C-网络设备操作入门
HbuilderX uniapp项目转cli项目全过程记录
基于Spring Boot的网上租贸系统设计与实现(源码+lw+部署文档+讲解等)
CSP-J/S 报名全攻略(含考纲)
golang - 实现并发数控制的方法
Life-long Mapping
数据结构——单链表(基本操作 一)
智能票据系统:颠覆性创新,开启新时代
- 原文地址:https://blog.csdn.net/weixin_52259848/article/details/126736174