-
Task08|文本数据|joyfulpandas
一、str对象
1. str对象的设计意图
str对象是定义在Index或Series上的属性,专门用于处理每个元素的文本内容,其内部定义了大量方法,因此对一个序列进行文本处理,首先需要获取其str对象。在Python标准库中也有str模块,为了使用上的便利,有许多函数的用法pandas照搬了它的设计,例如字母转为大写的操作:#python的str对象,str模块 var='abcd' str.upper(var) #Series的str对象 s=pd.Series(['abcd','efg','hi']) s.str s.str.upper()- 1
- 2
- 3
- 4
- 5
- 6
- 7
根据文档
API材料,在pandas的50个str对象方法中,有31个是和标准库中的str模块方法同名且功能一致,这为批量处理序列提供了有力的工具。2. []索引器
对于
str对象而言,可理解为其对字符串进行了序列化的操作,例如在一般的字符串中,通过[]可以取出某个位置的元素:var[0] var[-1:0:-2] s.str[0] s.str[-1:0:-2] s.str[2]- 1
- 2
- 3
- 4
- 5
3. string类型
应当尽量保证每一个序列中的值都是字符串的情况下才使用
str属性
必要条件是序列中至少有一个可迭代(Iterable)对象,包括但不限于字符串、字典、列表。对于一个可迭代对象,string类型的str对象和object类型的str对象返回结果可能是不同的s=pd.Series([{1:'temp_1',2:'temp_2'},['a','b'],0.5,'my_string']) s.str[1] [out]" 0 temp_1 1 b 2 NaN #不可迭代对象 3 y dtype: object s.astype('string').str[1]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
当序列类型为
object时,是对于每一个元素进行[]索引,因此对于字典而言,返回temp_1字符串,对于列表则返回第二个值,而第三个为不可迭代对象,返回缺失值,第四个是对字符串进行[]索引。而string类型的str对象先把整个元素转为字面意义的字符串,例如对于列表而言,第一个元素即 “{”,而对于最后一个字符串元素而言,恰好转化前后的表示方法一致,因此结果和object类型一致。string类型是Nullable类型,但object不是。这意味着string类型的序列,
如果调用的str方法返回值为整数Series和布尔Series时,其分别对应的dtype是Int和boolean的Nullable类型而
object类型则会分别返回int/float和bool/object,取决于缺失值的存在与否。同时,字符串的比较操作,也具有相似的特性,string返回Nullable类型,但object不会s=pd.Series(['a']) s.str.len()#int s.astype('string').str.len()#Int s=='a' s.astype('string')=='a'#bool s=pd.Series(['a',np.nan])#boolean s.str.len() s.astype('string').str.len() s=='a' s.astype('string')=='a'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
最后需要注意的是,对于全体元素为数值类型的序列,即使其类型为
object或者category也不允许直接使用str属性。如果需要把数字当成string类型处理,可以使用astype强制转换为string类型的Series:s=pd.Series([12,345,6789]) s.astype('string').str[1] # 0 2 # 1 4 # 2 7 # dtype: string- 1
- 2
- 3
- 4
- 5
- 6
- 序列化方法不同
- Nullable
str:Int和boolean
object:int/float和bool/object
二、正则表达式基础
2. 元字符基础
元字符 描述 . 匹配除换行符以外的任意字符 [ ] 字符类,匹配方括号中包含的任意字符 [^ ] 否定字符类,匹配方括号中不包含的任意字符 * 匹配前面的子表达式零次或多次 + 匹配前面的子表达式一次或多次 ? 匹配前面的子表达式零次或一次 {n,m} 花括号,匹配前面字符至少 n 次,但是不超过 m 次 (xyz) 字符组,按照确切的顺序匹配字符xyz | 分支结构,匹配符号之前的字符或后面的字符 \ 转义符,它可以还原元字符原来的含义 ^ 匹配行的开始 $ 匹配行的结束 #正则表达式 import re re.findall(r'.','Apple! This is an Apple!') re.findall(r'.','abc') re.findall(r'[ac]','abc') re.findall(r'[^ac]','abc') re.findall(r'[ab]{2}','aaaabbbb') #{n}指匹配n次 aa,ab,bb re.findall(r'aaa|bbb','aaaabbbb') re.findall(r'a\\?|a\*','aa?a*a') re.findall(r'a?.','abaacadaae')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3. 简写字符集
此外,正则表达式中还有一类简写字符集,其等价于一组字符的集合:
简写 描述 \w 匹配所有字母、数字、下划线: [a-zA-Z0-9_] \W 匹配非字母和数字的字符: [^\w] \d 匹配数字: [0-9] \D 匹配非数字: [^\d] \s 匹配空格符: [\t\n\f\r\p{Z}] \S 匹配非空格符: [^\s] \B 匹配一组非空字符开头或结尾的位置,不代表具体字符 re.findall(r'.\s','Apple! This Is an Apple!') #匹配空格符前面的字符 re.findall(r'\s','Apple! This Is an Apple!') #匹配空格符 re.findall(r'\w{2}','09 8? 7w c_ 9q p@') #匹配两次字母数字下划线 #匹配字母|数字|下划线,非字母|数字|下划线,非空字符开头或结尾的位置 re.findall(r'\w\W\B','09 8? 7w c_ 9q p@') #匹配上海市,匹配区至少两次不超过3次 匹配数字加号 re.findall(r'上海市(.{2,3}区)(.{2,3}路)(\d+号)', '上海市黄浦区方浜中路249号 上海市宝山区密山路5号')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
三、文本处理的五类操作
1. 拆分
str.split能够把字符串的列进行拆分,其中第一个参数为正则表达式,可选参数包括从左到右的最大拆分次数n,是否展开为多个列expand。
与其类似的函数是str.rsplit,其区别在于使用n参数的时候是从右到左限制最大拆分次数。但是当前版本下rsplit因为bug而无法使用正则表达式进行分割:s = pd.Series(['上海市黄浦区方浜中路249号', '上海市宝山区密山路5号']) s.str.split('[市区路]') s.str.split('[市区路]', n=2, expand=True) s.str.rsplit('[市区路]',n=2,expand=True)- 1
- 2
- 3
- 4
- 5
2. 合并
关于合并一共有两个函数,分别是
str.join和str.cat。str.join表示用某个连接符把Series中的字符串列表连接起来,如果列表中出现了非字符串元素则返回缺失值str.cat用于合并两个序列,主要参数为连接符sep、连接形式join以及缺失值替代符号na_rep,其中连接形式默认为以索引为键的左连接。s=pd.Series([['a','b'],[1,'a'],[['a','b'],'c']]) s.str.join('-') s.str.cat(s2,sep='-') s2.index=[1,2] s1.str.cat(s2,sep='-',na_rep='?',join='outer')- 1
- 2
- 3
- 4
- 5
- 6
3. 匹配
str.contains返回了每个字符串是否包含正则模式的布尔序列s = pd.Series(['my cat', 'he is fat', 'railway station']) s.str.contains('\s\wat') #匹配空格,字母,at- 1
- 2
- 3
str.startwith和str.endswith返回每个字符串以给定模式为开始和结束的布尔序列
不支持正则表达式s.str.startswith('my') s.str.endswith('t')- 1
- 2
使用正则表达式检测开始和结束字符串的模式,用
str.match(),也可以在str.contains的正则中使用^和$来实现:#从开头开始匹配 s.str.match('m|h') s.str.contains(''^[m|h]') #从末尾开始匹配 s.str[::-1].str.match('ta[f|g]|n') s.str.contains('[f|g]at|n$')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
返回索引的匹配函数
s=pd.Series(['This is an apple.That is not an apple.']) s.str.find('apple') s.str.rfind('apple')- 1
- 2
- 3
- 4
4. 替换
str.replace和replace不是一个函数,在使用字符串替换的时候应当使用前者s=pd.Series(['a_1_b','c_?']) s.str.replace('\d|\?','new',regex=True)- 1
- 2
当需要对不同部分进行有差别的替换时,可以利用子组的方法,并且此时可以通过传入自定义的替换函数来分别进行处理,注意group(k)代表匹配到的第k个子组(圆括号之间的内容)
import numpy as np import pandas as pd s=pd.Series(['上海市黄浦区方滨中路249号','上海市宝山区密山路5号','北京市昌平区北农路2号']) pat='(\w+市)(\w+区)(\w+路)(\w+号)' city={'上海市':'Shanghai','北京市':'Beijing'} district={'昌平区':'CP District','黄浦区':'HP District','宝山区':'BS District'} road={'方滨中路':'Mid Fangbin Road','密山路':'Mishan Road','北农路':'Beinong Road'} #group(k)代表匹配到的第k个子组 def my_func(m): str_city=city[m.group(1)] str_district=district[m.group(2)] str_road=road[m.group(3)] str_no='No'+m.group(4)[:-1] return ' '.join([str_city,str_district,str_road,str_no]) s.str.replace(pat,my_func,regex=True)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5. 提取
str.split例子中会把分隔符去除,这并不是用户想要的效果,这时候就可以用str.extract进行提取pat='(\w+市)(\w+区)(\w+路)(\w+号)' s.str.extract(pat) pat = '(?P<市名>\w+市)(?P<区名>\w+区)(?P<路名>\w+路)(?P<编号>\d+号)' s.str.extract(pat) #extractall: #把所有符合条件的模式全部匹配出来,如果存在多个结果,则以多级索引的方式存储 s=pd.Series(['A135T15,A26S5','B674S2,B25T6'], index = ['my_A','my_B'])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
str.extractall()str.findall的功能类似于str.extractall
str.findall:结果存入列表
str.extractall:处理为多级索引,每个行值对应一组匹配,不是把所有匹配组合构成列表pat_with_name='[A|B](?P\d+)[T|S](?P s.str.extractall(pat_with_name) s.str.findall(pat)\d+)' - 1
- 2
- 3
- 4
- 5
extractall:处理成多级索引
findall:结果存入列表常用字符串函数
1. 字母型函数
upper,lower,title,capitalize,swapcase将字母大小写转化s=pd.Series(['lower','CAPITALS','this is a sentence','SwApCaSe']) s.str.upper() s.str.lower() s.str.title() s.str.capitalize() s.str.swapcase()- 1
- 2
- 3
- 4
- 5
- 6
2. 数值型函数
pd.to_numeric() #对字符格式的数值进行快速转换和筛选 参数:errors:非数值的处理方式 downcast:转换类型 errors:不能转换为数值的有 'raise:直接报错 coerce:设为缺失 ignore:保持原来的字符串' s=pd.Series(['1','2.2','2e','??','-2.1','0']) pd.to_numeric(s,errors='ignore') #忽略错误 pd.to_numeric(s,errors='coerce') #将错误设置成缺失值 #数据清洗的时候可以利用coerce的设定,快速查看非数值的行 s[pd.to_numeric(s,errors='coerce').isna()]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3. 统计型函数 count len
count和len的作用分别是返回出现正则模式的次数和字符串的长度:#count #统计型函数 s=pd.Series(['cat rat fat at','get feed sheet heat']) s.str.count('[r|f]at|ee') s.str.len()#计算长度- 1
- 2
- 3
- 4
- 5
- 6
4. 格式型函数
格式型函数主要分为两类,
第一种是除空型,第二种是填充型。#除空型函数 my_Index=pd.Index([' col1','col2 ',' col3 ']) my_Index.str.strip().str.len() #444 #去除空格之后统计长度 my_Index.str.rstrip().str.len() #545 my_Index.str.lstrip().str.len() #455- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
第一类函数一共有三种,它们分别是
strip, rstrip, lstrip,分别代表去除两侧空格、右侧空格和左侧空格。这些函数在数据清洗时是有用的,特别是列名含有非法空格的时候。除空型函数
填充型函数
#填充型函数 s=pd.Series(['a','b','c']) s.str.pad(5,'left','*') #左边填充使得字符串长度为5 #****a #pad函数可以选定字符串长度,填充的方向,填充的内容 s.str.pad(5,'right','*') #a**** s.str.pad(5,'both','*') #**ab* #*aba* #三种情况可以分别用rjust,ljust,center来等效完成 #ljust是指右侧填充 s.str.rjust(5,'*')#左侧填充 s.str.ljust(5,'*')#右侧填充 s.str.center(5,'*')#中心填充- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
#读取excel文件的时候,经常会出现数字前补零的需求 s=pd.Series([7,155,303000]).astype('string') #在左侧补零 s.str.pad(6,'left','0') s.str.rjust(6,'0') s.str.zfill(6)- 1
- 2
- 3
- 4
- 5
- 6
- 7
五、练习
Ex1:房屋信息数据集
现有一份房屋信息数据集如下:
df = pd.read_excel('../data/house_info.xls', usecols=['floor','year','area','price']) df.head(3)- 1
- 2
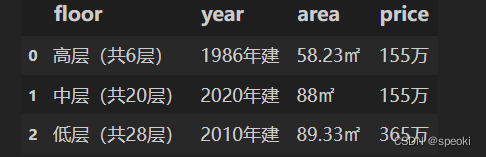
- 将year改为整年存储
df=pd.read_excel('../data/house_info.xls',usecols=['floor','year','area','price']) df.head(3) #问题1.1将year列改为整数年份存储。 a=df.year.head(3) pat_year='([0-9]{4})' print("各列的缺失信息",df.isna().sum()/df.shape[0]) df1=df.fillna(value='0000') #1. 使用提取函数 year_temp=df1.year.str.extract(pat_year).astype('Int64') df.year=year_temp df.head() #2.使用去除函数 df=pd.read_excel('../data/house_info.xls',usecols=['floor','year','area','price']) df.head(3) year=df.year.str.rstrip("年建") year=pd.to_numeric(year,errors='coerce').astype('Int64') year.fillna(value='0000') df.year=year- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 将floor列替换为Level,Highest两列,其中的元素分别为string类型的层类别(高层,中层,低层)与整数类型的最高层数
3.计算房屋每平米的均价avg_price,以
**元/平米的格式存储到表中,其中***为整数#计算房屋每平米的均价avg_price, #以***元/平米的格式存储到表中,其中***为整数。 df1=df.copy() df1['area']=pd.to_numeric(df1['area'].str[:-1],errors='coerce').astype('float64') df1['price']=pd.to_numeric(df1['price'].str[:-1],errors='coerce').astype('float64') df1['avg_price']=((10000*df1['price']/df1['area']).astype('int')).astype('string')+"元/平米" df1.head()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Ex2:《权力的游戏》剧本数据集
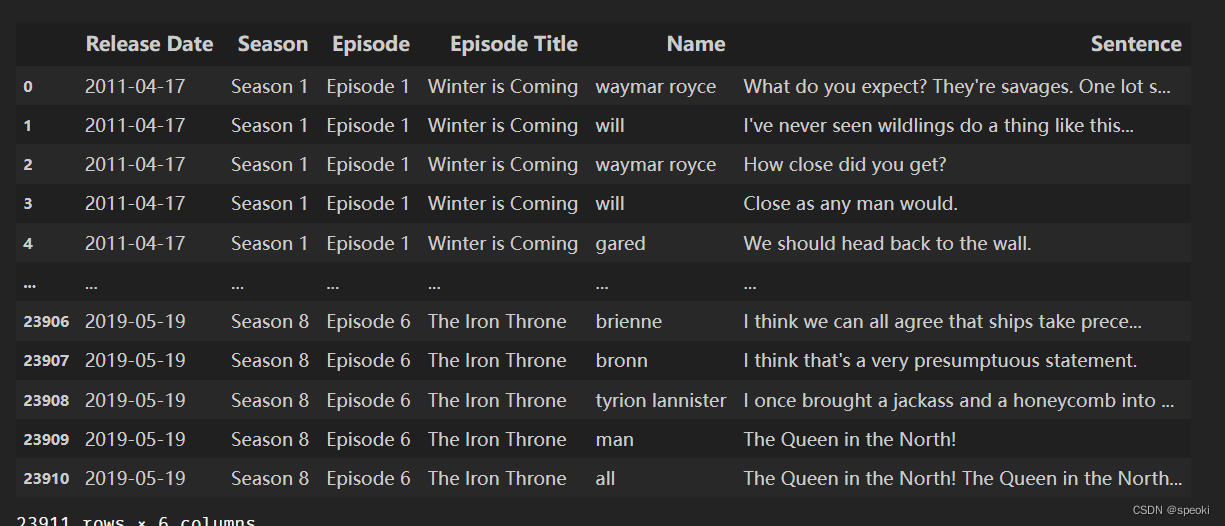
现有一份权力的游戏剧本数据集如下:
df = pd.read_csv('../data/script.csv') df.head(3)- 1
- 2
-
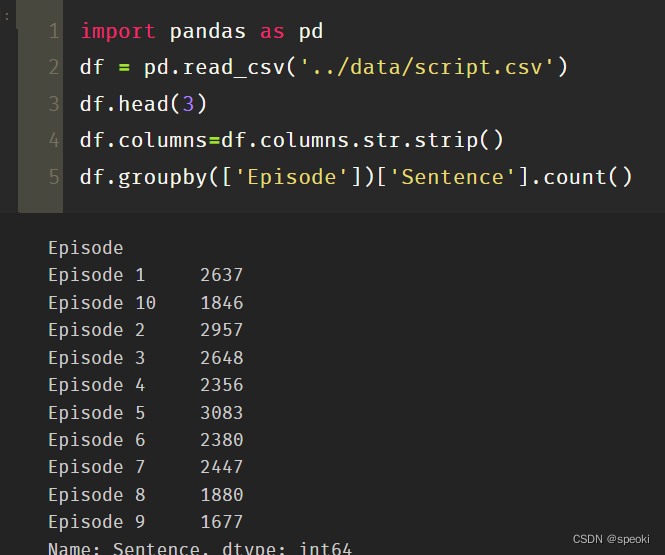
计算每一个
Episode的台词条数。
-
以空格为单词的分割符号,请求出单句台词平均单词量最多的前五个人。
df['word_count']=df['Sentence'].str.count('\s')+1 #句子空格数目+1=句子单词数 actor_word=df.groupby(['Name'])['word_count'].mean().reset_index().sort_values('word_count',ascending=False) actor_word.head(5)- 1
- 2
- 3
- 4
- 5
- 6
- 若某人的台词中含有问号,那么下一个说台词的人即为回答者。若上一人台词中含有 n n n个问号,则认为回答者回答了 n n n个问题,请求出回答最多问题的前五个人。
#构造回答者 #将name列向上移动一位,最后一位用NAN表示 #shift将回答者放到问题上,最后一位没有问题NAN s=pd.Series(df.Sentence.values,index=df.Name.shift(-1)) # periods = -1(默认为1),将Name列向上移动一位,最后一位用NaN填充 s.str.count('\?').groupby('Name').sum().sort_values(ascending=False).head() #数- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
相关阅读:
Java SE 18 新增特性
[附源码]java毕业设计人口老龄化社区服务与管理平台
Redis学习 - 了解Redis(三)
NLP - monocleaner
三秋农忙,自动驾驶农机保驾护航
count(*) 和 count(1) 有什么区别?哪个性能最好?
Vue2+ElementUI 静态首页案例
Go类型嵌入介绍和使用类型嵌入模拟实现“继承”
c++ map/multimap
CSS scroll-behavior
- 原文地址:https://blog.csdn.net/m0_52024881/article/details/126700139
