-
零拷贝、MMAP、堆外内存
首先我们得明白,不管是零拷贝、MMAP还是堆外内存,实际上解决的都是用户态和内核态数据拷贝问题和上下文切换问题,区别只是在实现方式不同
问题1:为什要把数据从内核空间拷贝到用户空间 ?
-
硬件通常不能直接访问用户空间。
-
磁盘这种基于块存储的硬件设备操作的是固定大小的数据块, 而用户进程请求的可能是任意大小的或非对齐的数据块。
-
在数据往来于用户空间与存储设备的过程中, 内核负责数据的分解、再组合工作, 因此充当着中间人的角色。
下面我们使用一个场景说明一下数据拷贝过程:

从上图中可以看出,从数据读取到发送一共经历了四次数据拷贝,具体流程如下:
-
第一次数据拷贝:当用户进程发起read()调用后,上下文从用户态切换至内核态。DMA引擎从文件中读取数据,并存储到Page Cache(内核态缓冲区)。
-
第二次数据拷贝:请求的数据从内核态缓冲区拷贝到用户态缓冲区,然后返回给用户进程。同时会导致上下文从内核态再次切换到用户态。
-
第三次数据拷贝:用户进程调用send()方法期望将数据发送到网络中,此时用户态会再次切换到内核态,请求的数据从用户态缓冲区被拷贝到Socket缓冲区。
-
第四次数据拷贝:send()系统调用结束返回给用户进程,再次发生上下文切换。此次操作会异步执行,从Socket缓冲区拷贝到协议引擎中。
问题2:为什么需要 Page Cache?
充当缓存的作用,这样就可以实现文件数据的预读,提升 I/O 的性能。可以理解为:批量数据刷盘。
上面已经通过一个程序读取数据发送到网络上的例子说明了数据在用户态和内核态的拷贝过程,下面我们重点来讲讲零拷贝、MMAP、堆外内存怎么减少数据拷贝。
零拷贝
实现原理:在 Linux 中系统调用 sendfile() 可以实现将数据从一个文件描述符传输到另一个文件描述符,从而实现了零拷贝技术。零拷贝技术减少了内核态向用户态拷贝和用户态向内核态的拷贝。通过FileChannel的传输来达到减少数据拷贝目的。
在Java中也可以使用了零拷贝技术,主要是NIO FileChannel类中:
-
transferTo()方法:可以将数据从FileChannel直接传输到另外一个Channel。
-
transferFrom()方法:将数据从Channel传输到FileChannel。
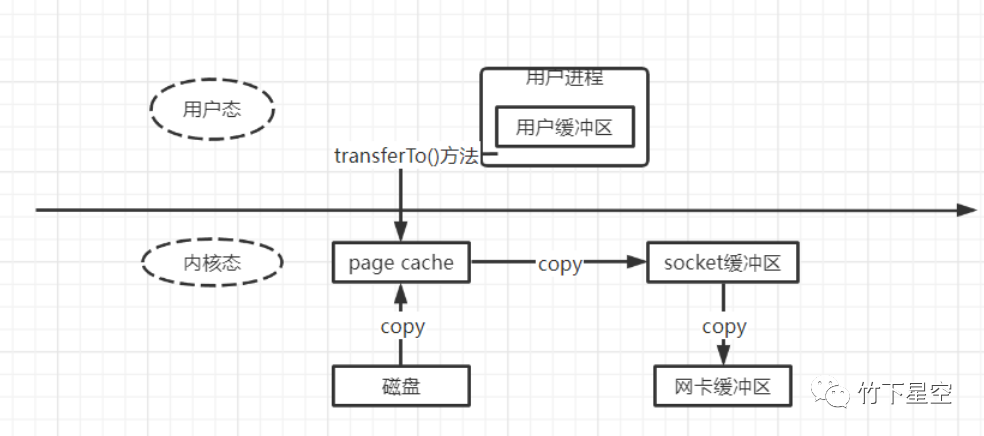
从上图中可以看出,使用transferTo()方法之后,从数据读取到发送一共经历了三次数据拷贝,减少了一次,具体流程如下:
-
用户进程调用FileChannel#transferTo(),上下文从用户态切换至内核态。
-
第一次数据拷贝:DMA从文件中读取数据,并存储到Page Cache。
-
第二次数据拷贝:CPU将Page Cache中的数据拷贝到Socket缓冲区。
-
第三次数据拷贝:DMA将Socket缓冲区数据拷贝到网卡进行数据传输。
实际开发中,我们能发现 Kafka 写入数据时也用到零拷贝技术。
在Kafka源码中MemoryRecords的writeTo方法中可发现:
-
调用了FileChannel的transferTo()方法
- public class FileRecords extends AbstractRecords implements Closeable {
- @Override
- public long writeTo(GatheringByteChannel destChannel, long offset, int length)
- throws IOException {
- long newSize = Math.min(channel.size(), end) - start;
- int oldSize = sizeInBytes();
- if (newSize < oldSize)
- throw new KafkaException(String.format(
- "Size of FileRecords %s has been truncated during " +
- " write: old size %d, new size %d ",
- file.getAbsolutePath(), oldSize, newSize));
- long position = start + offset;
- int count = Math.min(length, oldSize);
- final long bytesTransferred;
- if (destChannel instanceof TransportLayer) {
- TransportLayer tl = (TransportLayer) destChannel;
- bytesTransferred = tl.transferFrom(channel, position, count);
- } else {
- // 重点:
- bytesTransferred = channel.transferTo(position, count, destChannel);
- }
- return bytesTransferred;
- }
- }
MMAP
原理:是一种内存映射文件的方法, 可以将一个文件或者其他对象映射到进程的虚拟地址空间,实现文件磁盘地址和进程虚拟地址空间中某一段地址的一一对应,这样应用程序就可以通过访问进程虚拟内存地址直接访问文件,进而达到操作文件的目的,这样就不用拷贝数据到用户态后再操作了。缺点是对映射文件大小有一定限制,一般是1.5GB ~ 2GB
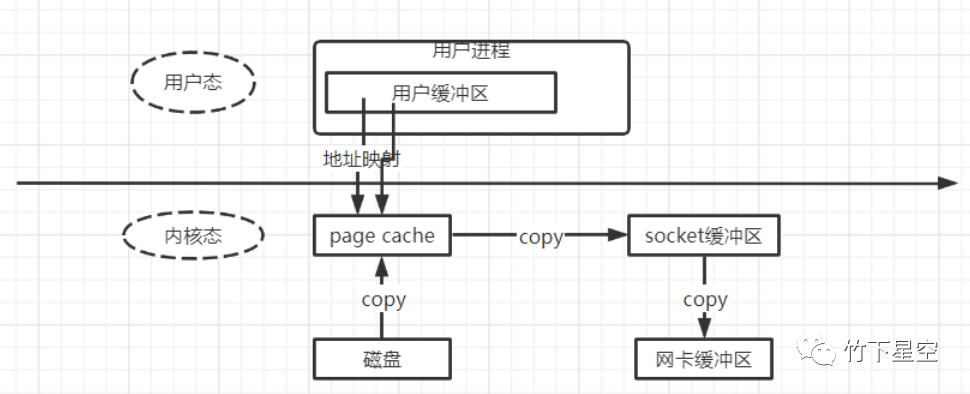
MMAP操作文件:
-
MMAP为用户进程创建新的虚拟内存区域
-
建立文件磁盘地址 和 虚拟内存相关区域的映射 (这期间没有涉及任何的文件拷贝)
-
当用户进程访问数据时, 若无数据则发起缺页异常处理, 根据已经建立好的映射关系进行一次数据拷贝, 将磁盘中的文件数据读取到虚拟地址对应的内存中。
实际开发中,我们能发现RocketMQ持久化消息使用了MMAP
MMAP技术在进行文件映射的时候,一般有大小限制,在 1.5GB ~ 2GB之间。RocketMQ才让CommitLog单个文件在1GB,ConsumeQueue文件在5.72MB,不会太大。
RocketMQ的消息写入支持内存映射与FileChannel两种写入方式:根据tranisentStorePoolEnable参数判断
-
false:先将消息写入到页缓存,然后根据刷盘机制持久化到磁盘。
-
true:数据会先写入到堆外内存,然后批量提交到FileChannel,并最终根据刷盘策略将数据持久化到磁盘。
堆外内存
原理:在内核态申请一块内存来操作数据,这块内存独立于jvm申请的内存,而且java程序可以直接操作,而不用上下文切换和数据拷贝。示例图如下:

平时开发时,会使用NIO的DirectBuffer来创建堆外内存,需要注意的是堆外内存是独立管理的,java的GC不会回收该部分的内存
实际开发过程中,Netty使用到了堆外内存
-
-
相关阅读:
ModuleNotFoundError: No module named ‘torchvision.models.utils‘
日志回滚工作原理剖析及在文件系统的作用
《公路测设技术》课程网课最新作业测验考试
AutoRunner自动化测试工具
Cesium点位弹窗
unity 血条跟随
Sqoop 学习
Unity 颜色查找表&富文本颜色
代码优化工具-测试程序执行时间-IDEAdebug+StopWatch
NeuralODF: Learning Omnidirectional Distance Fields for 3D Shape Representation
- 原文地址:https://blog.csdn.net/shidebin/article/details/126833583
