-
python--基础知识点--memray
1 memray 概述
memray 是 Python 的内存分析器。它可以跟踪 Python 代码、本机扩展模块和 Python 解释器本身中的内存分配。它可以生成几种不同类型的报告来帮助您分析捕获的内存使用数据。虽然通常用作 CLI 工具,但它也可以用作库来执行更细粒度的分析任务。
工具的主要特点:
- 跟踪每个函数的调用,能够准确的跟踪调用栈。
- 能跟踪c/c++库的调用。
- 分析速度很快。
- 收集内存数据,输出各种图标。
- 使用python线程。
- 与本地线程一起工作。
可以帮助解决的问题:
- 分析应用程序中内存分配,发现高内存使用率的原因。
- 查找内存泄漏的原因。
- 查找导致内存大量分配的代码热点。
注意:
- 环境要求,python3.7+以上版本,linux系统(仅支持linux系统)。
- 若本文没有能够解答您的疑惑,请到官方文档https://bloomberg.github.io/memray/getting_started.html查找。
2 memray 各命令简介
2.1 memray 使用帮助
python3 -m memray --help # 不要求当前系统环境的python版本,只要使用的python解释器为python3.7以上 或 memray --help # 要求当前系统环境为python3.7以上- 1
- 2
- 3
参数 作用 使用方式 run 运行指定的应用程序并跟踪内存使用情况 python3 -m memray run -o output.bin my_script.py flamegraph 在html报告中,用火焰图方式,显示内存使用情况 python3 -m memray flamegraph output.bin table 在html报告文件中,用表格的方式显示内存分析情况 python3 -m memray table output.bin live 用实时屏幕显示方式,显示各种内存使用情况 python3 -m memray run --live-remote -p [port_num] my_script.py
python3 -m memray live [port_num]tree 在终端中,用树形结构显示内存使用情况 python3 -m memray tree output.bin parse 用debug模式,显示每一行的内存使用情况 python3 -m memray parse output.bin > my_memray.txt summary 在终端中生成一个函数所占用内存的概况报告 python3 -m memray summary output.bin stats 在终端中非常详细的显示内存使用情况 python3 -m memray stats output.bin 2.2 memray run 使用帮助
python3 -m memray run --help- 1
参数 作用 默认是否加该参数 -o OUTPUT --output OUTPUT 指定输出结果到OUTPUT[指定的bin文件] Default: . .bin –live 启动实时跟踪会话模式 Default: False –live-remote 启动实时跟踪会话并等待客户端连接,结合-p指定跟踪会话要使用的端口,否则跟踪会话的端口是随机的 Default: False –live-port LIVE_PORT, -p LIVE_PORT 启动实时跟踪时要使用的端口 Default: False –native 跟踪C/C++堆栈 Default: False –follow-fork 跟踪脚本分叉的子进程中的分配 Default: False –trace-python-allocators 记录pymalloc分配器的分配情况 Default: False -q, --quiet 运行时不显示任何特定于跟踪的输出 Default: False -f, --force 强制覆盖已存在的bin文件 Default: False –compress-on-exit 跟踪完成后使用 lz4 压缩生成的文件 Default: True –no-compress 不使用 lz4 压缩生成的文件,加上该参数生成的bin文件由于经过压缩,大小会比不加时小 Default: False -c 将字符串代码作为脚本运行,例:python3 -m run -c “print(“1111111111111”)” Default: False -m 将库模块作为脚本运行 Default: False 3 memray 各命令详细说明
举例脚本test.py:
import time def a(n): aaa = b(n) time.sleep(10) return aaa def b(n): bbb = "a" * n return [c(n), d(n)] def c(n): return "a" * n def d(n): return "a" * n if __name__ == "__main__": a(10000000)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3.1 memray 各命令详细说明
3.1.1 run
# 生成output.bin python3 -m memray run -o output.bin test.py- 1
- 2
注意:对于web代码,首先需要把test.py换位web的入口文件,比如 “python3 -m memray run -o output.bin runserver.py”,然后想停止捕捉内存分配情况直接 “ctrl+c”3.1.2 flamegraph
3.1.2.1 默认情况,无参
# 生成 火焰图报告 memray-flamegraph-output.html python3 -m memray flamegraph output.bin- 1
- 2
使用浏览器打开memray-flamegraph-output.html如下图3-1,图3-2,图3-3:
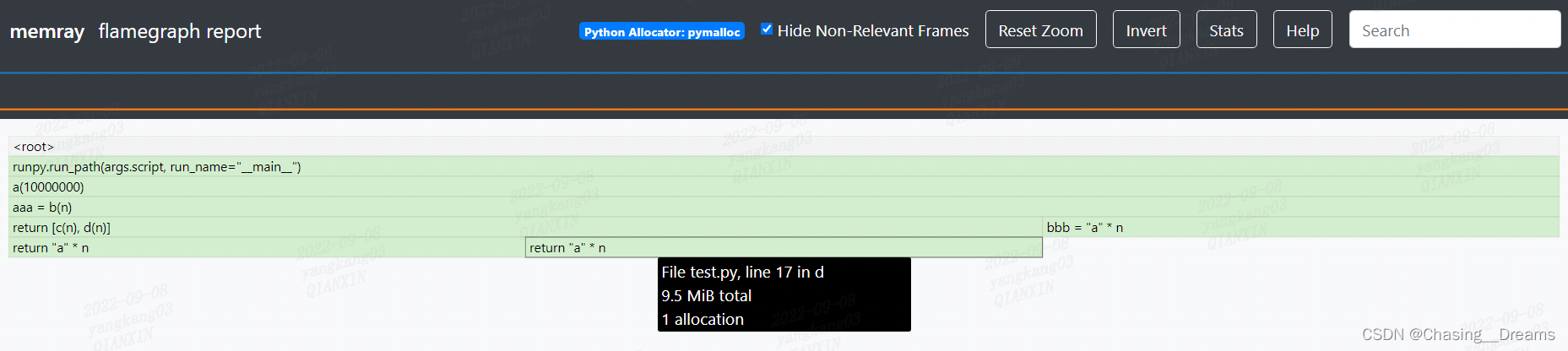
图3-1 火焰图报告 图3-1 该报告可以将内存分配数据可视化展示。从上往下,显示了程序的调用过程[上层调用下层]、宽度代表函数占用内存大小。将 光标 放到每一个绿色块上 可以查看 分配内存的语句所在 文件、函数、行数、分配空间大小、分配次数。
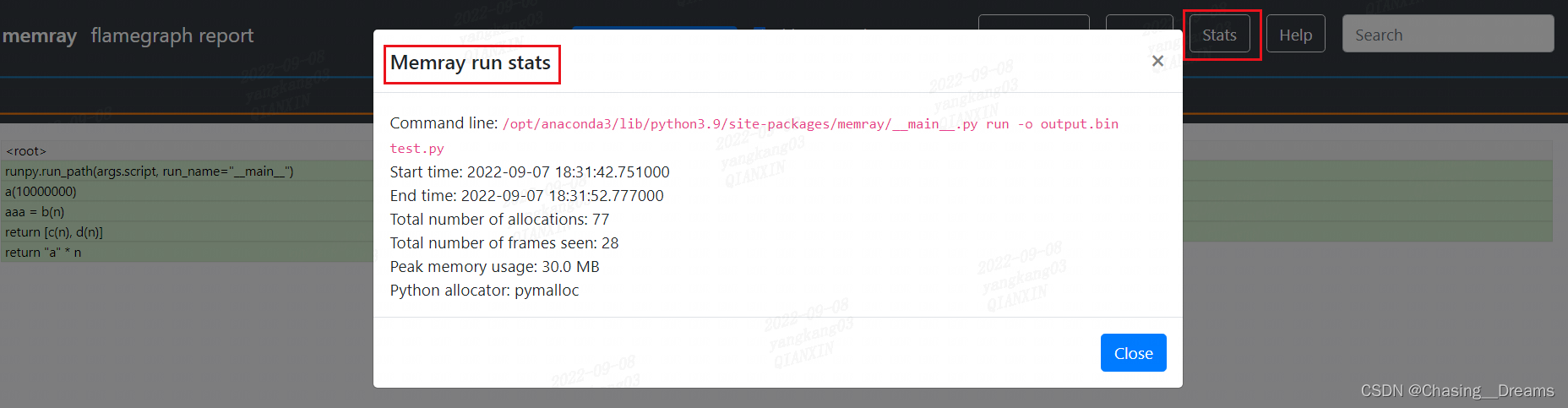
图3-2 
图3-3 3.1.2.2 参数
参数 作用 默认是否加该参数 -o OUTPUT, --output OUTPUT 指定输出结果到OUTPUT[指定的html文件] Default: memray-flamegraph- .html -f, --force 强制覆盖已存在的html文件 Default: False –leaks 显示内存泄漏视图,其中显示未释放的内存,而不是峰值内存使用情况。 Default: False –split-threads 显示各个线程内存的分配情况 Default: False 3.1.2.2.1 --split-threads
测试脚本test7.py
import threading def bbb(n): aa = "a" * n def aaa(n): aa = "a" * n tasks = [threading.Thread(target=bbb, args=(n,), name="bbb")] [task.start() for task in tasks] [task.join() for task in tasks] [print(hex(task.ident)) for task in tasks] if __name__ == "__main__": aaa(10000000)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
图3-3-1 
图3-3-2 主子线程总体内存分配火焰图 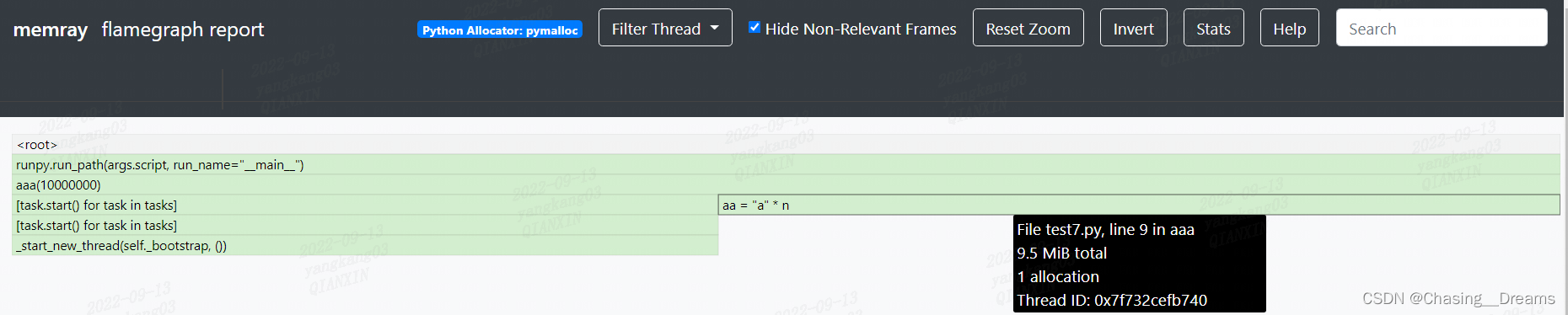
图3-3-3 主线程内存分配火焰图 
图3-3-4 子线程内存分配火焰图 3.1.3 table
3.1.3.1 默认情况,无参
注意:对于参数 --leaks的使用请到官方文档查找。
# 生成表格报告 memray-table-output.html python3 -m memray table output.bin- 1
- 2

图3-4 表格报告 图3-4 以表格的形式展示程序的内存使用情况。 Thread ID 表示对应的线程, Size 表示占用的内存总数, Allocator 表示占用内存的函数, Location 表示函数所在的位置。同时,还可以对每一列的数据进行排序。
3.1.3.2 参数
参数 作用 默认是否加该参数 -o OUTPUT, --output OUTPUT 指定输出结果到OUTPUT[指定的html文件] Default: memray-table- .html -f, --force 强制覆盖已存在的html文件 Default: False –leaks 显示内存泄漏,而不是峰值内存使用 Default: False 3.1.4 tree
3.1.4.1 默认情况,无参
# 生成树形报告 python3 -m memray tree output.bin- 1
- 2
图3-5 图3-5 报告可以清晰的显示出程序的调用层次。树形报告中根节点中的内存总量和所占百分比 只是针对于图中展示的数据,占用内存小的不在图中。
3.1.4.2 参数
参数 作用 默认是否加该参数 -b, --biggest-allocs 显示n个最大分配 Default: 10 3.1.5 parse
# 按代码行说明内存分配情况 python3 -m memray parse output.bin > memory.txt 或 python3 -m memray parse output.bin | cat- 1
- 2
- 3
- 4



图3-6 3.1.6 summary
3.1.6.1 默认情况,无参
# 生成概览表 python3 -m memray summary output.bin- 1
- 2

图3-7 概览表 图3-7 显示了执行脚本所分配内存的总体情况。每个函数占用的空间[Total包括:1 该函数调用其它函数,其它函数所占用空间;2 该函数本身所占用的空间],每个函数本身所占用空间[OWN]。3.1.6.2 参数
参数 作用 默认是否加该参数 -s, --sort-column 按列排序,用来排序的列列名会被"<>"括起来,如 Default: 1; 1[Total Memory] -r, --max-rows 最多显示"n"行 3.1.7 stats
3.1.7.1 默认情况,无参
# 生成统计报告 python3 -m memray stats output.bin- 1
- 2
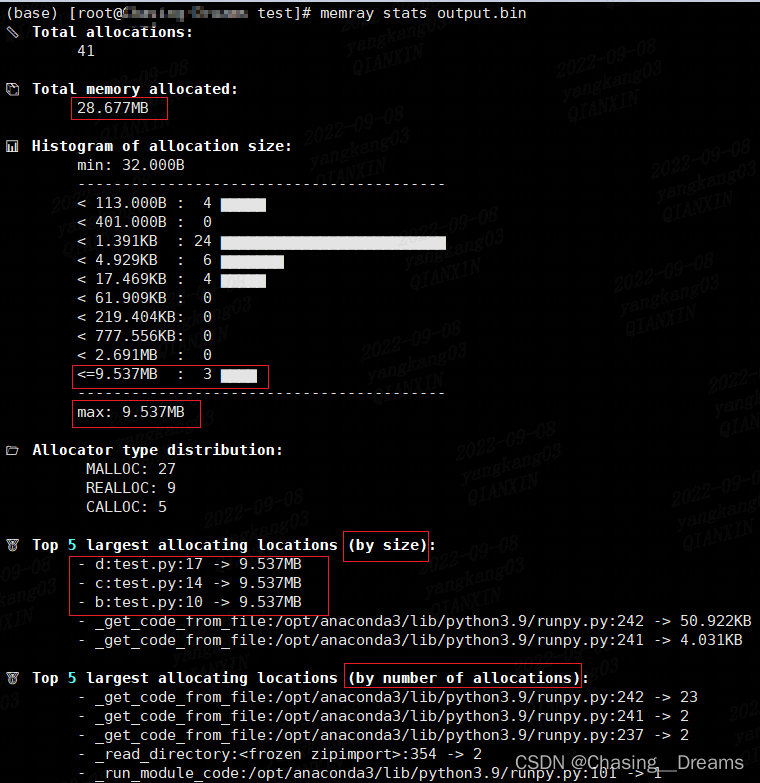
图3-8 统计报告 图3-8 可以显示程序内存使用情况的详细信息,包括分配的内存总量、分配类型(例如 MALLOC,、REALLOC、CALLOC )等。
3.1.7.2 参数
参数 作用 默认是否加该参数 -n, --num-largest 显示分配内存最多的前“n”个函数。 Default: 5 3.1.8 live
测试代码test1.py:
import time def a(n): aaa = b(n) return aaa def b(n): i = 20 while i: aa = "a" * 1000000 * i i-=1 time.sleep(1) time.sleep(10) aa = "a" * n time.sleep(10) aaa = [c(n), d(n)] time.sleep(10) return aaa def c(n): return "a" * n def d(n): return "a" * n if __name__ == "__main__": a(10000000)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
# 用实时屏幕显示方式,显示各种内存使用情况 # 打开终端窗口1执行。 python3 -m memray run --live-remote -p 33000 test1.py # 打开终端窗口2执行 python3 -m memray live 33000- 1
- 2
- 3
- 4
- 5

图3-9 终端窗口1 
图3-10 终端窗口2 3.2 memray run 参数详细说明
3.2.1 --native
python3 -m memray run --native -o output1.bin test.py python3 -m memray flamegraph outpu1.bin- 1
- 2
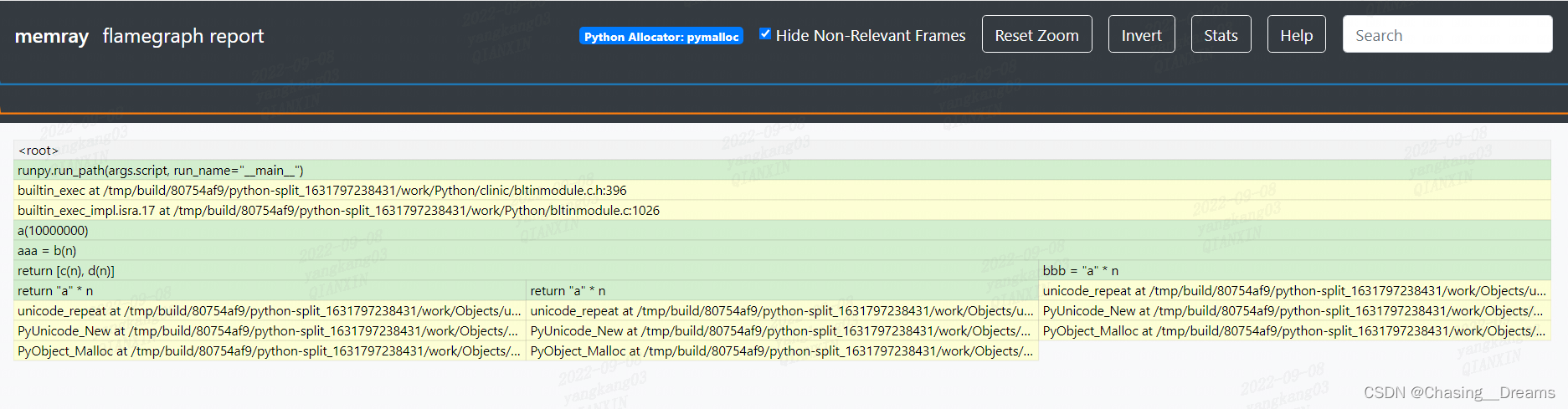
图3-11 图3-11 显示通过添加参数–native,memray对C/C++函数进行了跟踪分析,这就弥补了一些底层使用C语言实现的Python第三方库,只能分析到浅层次的Python函数/方法的缺点。
3.2.2 --follow-fork
跟踪脚本分叉的子进程中的分配。
测试代码test2.py:
import multiprocessing def bbb(n): aa = "a" * n def aaa(n): aa = "a" * n tasks = [multiprocessing.Process(target=bbb, args=(n,), name="bbb")] [task.start() for task in tasks] [task.join() for task in tasks] if __name__ == "__main__": aaa(10000000)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
python3 -m memray -o output2.bin test2.py # 生成了两个文件 output2.bin output2.bin.15583[进程号] python3 -m memray flamegraph output2.bin # 生成火焰图 memray-flamegraph-output2.html python3 -m memray flamegraph output2.bin.15583 # 生成火焰图 memray-flamegraph-output2.bin.html- 1
- 2
- 3
3.2.3 其它参数
其它参数此处不再重复赘述。
4 API
举例如下test3.py:
from memray import Tracker, FileDestination, SocketDestination import time def a(n): aaa = b(n) time.sleep(10) return aaa def b(n): bbb = "a" * n return [c(n), d(n)] def c(n): return "a" * n def d(n): return "a" * n if __name__ == "__main__": file_name = "./output4.bin" socket_dest = SocketDestination(server_port=33000, address="127.0.0.1") file_dest = FileDestination(path="./output4.bin", overwrite=False, # 默认值 False compress_on_exit=False) # 默认值 False native_traces = False # 默认值 False memory_interval_ms = 10 # 默认值 10 follow_fork = False # 默认值 False trace_python_allocators = False # 默认值 False # with Tracker(file_name=file_name) # (1) 正确 # with Tracker(destination=file_name) # (2) 正确 # with Tracker(destination=socket_dest) # (3) 正确 # with Tracker(file_name=file_name, destination=socket_dest) # (4) 错误:file_name与destination不能同时存在 with Tracker(destination=socket_dest, native_traces=native_traces, memory_interval_ms=memory_interval_ms, follow_fork=follow_fork, trace_python_allocators=trace_python_allocators): a(10000000)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
使用方法:
- 当代码中使用(1)(2)两种方式时都会生成output.bin文件,后续各种类型的报告通过执行相应命令来生成[在3.1中已详细说明]。
- 当代码中使用(3)时,然后在另一个终端窗口执行 “python3 memray live 33000” 即可看到实时内存的变化。
-
相关阅读:
Vue 插槽
wpf C# 用USB虚拟串口最高速下载大文件 每包400万字节 平均0.7s/M,支持批量多设备同时下载。自动识别串口。源码示例可自由定制。
维度建模之汇总分析表的设计经验分享
Nginx01-HTTP简介与Nginx简介(安装、命令介绍、目录介绍、配置文件介绍)
一个 WPF + MudBlazor 的项目模板(附:多项目模板制作方法)
机器人制作开源方案 | 智能快递付件机器人
使用说明丨Kamiya艾美捷抗酒石酸酸性磷酸酶TRAP染色试剂盒
Android Kotlin Paging3 Flow完整教程
CHOME、EDGE无法打开网页问题处理方法
Flink 源码解读系列 DataStream 带 Watermark 生成的时间戳分配器
- 原文地址:https://blog.csdn.net/Chasing__Dreams/article/details/126833090
