-
HashMap原理
一、HashMap数据结构
ArrayList:查询块,增删慢
LinkedList:查询慢,增删快HashMap是融合了上面两者优点的数据结构
Java1.7:数组+链表
Java1.8:数组+链表+红黑树

二、存放过程:

三、HashMap的几个关键参数:
-
默认初始化数组容量大小是16。
-
数组扩容刚好是2的次幂,即新数组长度都是原数组的2倍,16,32,64,128
-
默认的加载因子是0.75,即大于16*0.75 = 12个时就要扩容
-
链表长度>=8、且Entry[ ]数组长度>=64时,链表转化成红黑树结构,若数组长度<64则会扩容。
-
红黑树节点数<=6的时候退化成链表。
四、HashMap是怎么扩容的?
- 创建一个新数组,长度是原来的2倍,即2的次幂。
- 遍历原数组,
hash &(newlength - 1)重新计算下标。
Java1.7 每个Entry都 rehash
Java 1.8 高低位拆分方式,原位置或者(原位置+oldlength)- 插入
Java1.7 头插法,环形链表,死循环问题
Java1.8 尾插法,不会形成环形链表Java 1.7扩容方法:


Java 1.8扩容方法:
不需要像JDK1.7的实现那样
hash & (newlength - 1)重新计算槽位,只需要看看newlength的最高位,对应hash值的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+原数组长度”


这种方法(hash & oldCap)并不会比HashMap 1.7中的(hash & (newCap - 1))效率高多少,有个几把用啊?
五、进行扩容(resize)时为什么重新哈希(rehash)?
此处”rehash“一般指的是
hash & (length - 1),不是值计算hash值,key的hash在之前已经已经计算出来了,不用重新计算,保存在Entry对象里面。下标 i 的计算是用key的hash值和数组长度进行计算的,resize后数组长度翻倍了,下标值肯定也会不一样。
六、为什么重写equals()方法的时候一般要重写hashCode()方法?
-
hashCode主要是用来计算桶的位置(下标 i),同一个元素只能放到同一个桶中。
-
equals经过重写,返回true就表示是同一个对象,这时也要重写hashCode,返回相同的值。
-
不然会出现put元素到一个桶中后,get取查找,根据key的hashCode返回不同的下标,去到另外的桶中查找,那就完犊子了。
七、什么是Hash碰撞(Hash冲突)?
不同的key用同一个hash函数计算出同样的hash值
八、HashMap是怎么计算数组下标(槽位)的?为什么不是对数组长度取模?
此处hash值和(数组长度-1)进行“位与”是第二次扰动处理。
先计算key的hash指,然后和数组长度减一进行位与运算
hash(key) & (length - 1),等同于取模:hash(key) % length位运算效率更高
九、HashMap是怎么计算hash值的?(hash函数是怎么设计的?)为什么要右移16位?为什么要用异或?
此处“位异或”是第一次扰动处理。
描述:
hash 函数是先拿到通过 key 的 hashcode,是 32 位的 int 值,然后让 hashcode 的高 16 位和低 16 位进行异或操作。

即:h ^ (h >>> 16)
用对象的hashCode无符号右移16位之后和本身进行位异或运算(1)为什么是“位异或”,而不是“位与”或者“位或”?
位异或:看到0和1的概率都为1/2,结果均匀分布
0^1 = 1
1^1 = 0
1^0 = 1
0^0 = 0位与:结果偏向0,结果不均匀
1&1 = 1
1&0 = 0
0&0 = 0
0&1= 0位或:结果偏向1,结果不均匀
1|1 = 1
1|0 = 1
0|0 = 0
0|1 = 1(2)为什么要右移16位?
对象的hashCode是int类型,int类型是4个字节,32位
右移16位,再与本身进行“位异或”,主要是让它的高16位和低16位进行异或
增加结果的随机性,让计算出来的hash值更加均匀分布,减少hash冲突

如果高16位都为0,那就返回key.hashCode() ,不会影响它本身。
(3)为什么要这么设计?
这个也叫扰动函数,这么设计有二点原因
(1)一定要尽可能降低 hash 碰撞,越分散越好;
(2)算法一定要尽可能高效,因为这是高频操作, 因此采用位运算(4)只要hashCode设计得够离散也是很难发生碰撞的,那为什么不能直接用key的hashcode作为数组下标?
key的hashCode返回int类型,-2147483648~2147483647,1<<31-1,前后加起来大概 40 亿的映射空间。而HashMap数组最大范围是1<<30,放不下。
另外内存也不够这么长的数组。
(5)为什么要高低位异或处理?不异或直接拿hashCode和数组长度计算不也行吗?
那样就只有低16位和length进行计算了,异或是让高16也参与进来,增加了结果的随机性。
十、HashMap能否用null值作为key?需要注意什么问题?
可以。
但从hash计算公式中看,当key == null时,hash值为0
hash & (length - 1)计算出的槽位是0,即保存在数组的第一个位置保存值和取值的时候,务必要注意,很可能在存值的时候,key的对象还是null,但到取值的时候,key已经被赋上值,从而导致最终值取不出来
十一、计算数组下标的时候为什么是用hash值与上(length - 1)而不是length?
计算数组下标原理就是hash值对数组长度取模,即
hash % length,为了等价,换成位与运算的时候必须是(length - 1)hash % length == hash & (length - 1)十二、为什么扩容的数组长度是2的次幂?
-
为了满足(length - 1),2的次幂减1,转成二进制所有位都是1
如15,二进制就是:1111
和hash值进行与计算后,结果就是后面4位的值
10111011000010110100 &1111 = 0100,即4
只要hash值本身是均匀分布的,结果就是均匀分布的 -
为了让(length - 1)== 奇数,那么二进制最后一位肯定为1,hash值 & 奇数,就会得到奇数、偶数都有的均匀分布的下标。
如果(length - 1)== 偶数,那么二进制最后一位肯定为0,hash值 & 偶数,所有结果都是偶数,提高了hash冲突,浪费了一半的存储空间。
用取模理解:
对偶数取模:hash % 2,结果有可能是奇数、偶数
对奇数取模:hash % 3,结果只能是偶数十三、HashMap的初始化长度是多少?为什么设置这样?
是 1 << 4 ,即16
- 为什么不直接写成16?
位运算直接操作内存,效率比较高。
- 为什么设置成16,而不是4、8?
经验值,需在效率和内存上做权衡,主要是满足2的次幂即可。
十四、负载因子默认是多少?为什么是这么多?
0.75
当负载因子==1.0时,数组填充满才会发生扩容,这时会发生大量的hash冲突,底下的红黑树变得很复杂,虽然不浪费空间,但会影响查询时间。
当负载因子==0.5时,数组填充到一半就会扩容,虽然hash冲突不多,红黑树并不复杂,查询时间很快,但浪费了一半空间。
取0.75是空间、时间上的一种平衡。
十五、哪些类适合作为HashMap的key?为什么?
String、Integer等包装类
-
final修饰,String类中value[ ],Integer等包装类中的value属性都有final修饰,不可变,由value计算出来的hashCode值也不可变
-
这些类都实现了hashCode和equals方法
十六、如果使用Object作为key,要实现什么方法?
hashCode、equals
保证做到:
- hashCode尽量散列均匀分布
- equals判断为相等的时候,hashCode值相同
十七、HashMap是如何处理hash冲突的(hash值相同)?
- 采用“链式寻址法”
把hash值相同的Entry组成一条链挂在下面(1.7),但随着链越长,查询会越慢,O(n)
到HashMap 1.8,当链长度达到8,并且容量达到64时,会转变成红黑树,查询效率近似折半查找,O(logn)
- 扰动处理
1次是对象的hashCode的高16位和低16位,“位异或”计算hash值
1次是hash值和(数组length - 1),“位与”计算槽位
让记过尽量散列均匀分布,减少哈希冲突。
十八、HashMap 1.7 采用什么插入方式?会有啥问题?为什么?
头插法:
当计算出的槽位上已经有Entry时,直接把新Entry放在该位置,旧的Entry往下挪,链接在新元素的屁股后面。
为什么用头插法?
因为作者认为新插入的元素可能经常被使用,所以放在头部,便于查找。
高并发下扩容容易形成环形链表,当在链表搜索一个不存在的key时就会存在死循环。


十九、HashMap 1.8采用什么插入方式?有什么好处?
尾插法:
在未转化红黑树之前,新元素是追加在链表的尾部,最后一个元素的next指向是null
不会形成环形链表
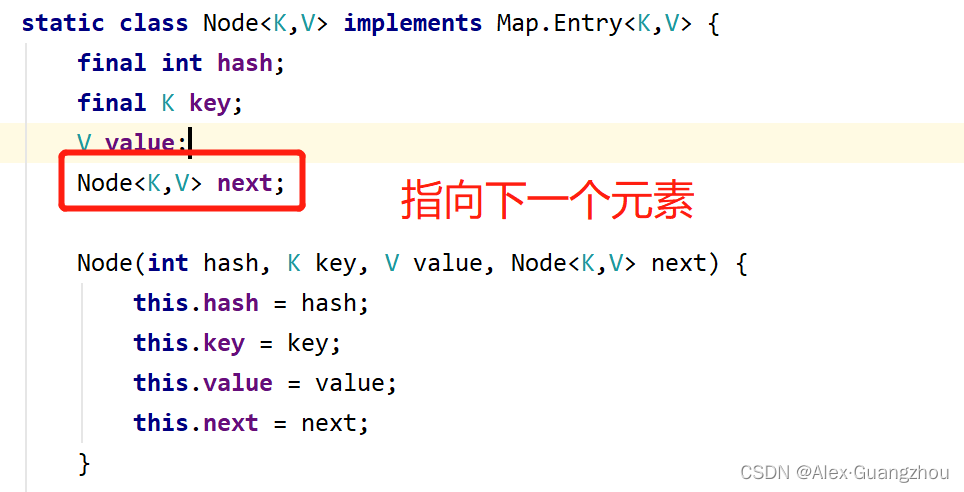

二十、HashMap 1.8中什么时候链表会转化成红黑树?什么时候红黑树又会转化为链表?为什么?
- 当链表长度>=8,且Node[ ]数组长度>=64时会转化为红黑树,如<64,则扩容resize。
选择8是因为,经过计算,在 hash 函数设计合理的情况下,发生 hash 碰撞 8 次的几率为百万分之 6
- 当红黑树节点<=6的时候会自动转化为链表。
选择6是因为,防止一直发生链表和红黑树的转化。
二十一、HashMap 1.8为什么不一开始就使用红黑树?
(1)在空间上:
树节点TreeNode比普通节点Node占用2倍空间。(2)在时间上:
链表:O(n)
红黑树:O(logn)在链表很短的时候并没有什么差别
时间和空间的权衡。

二十二、HashMap线程安全问题
Java 1.7:环形链表死循环、数据覆盖(判断槽位为空,覆盖别的线程的数据)
Java 1.8:数据覆盖解决方案:
(1)HashTable类
key和value都不能为null
Hashtable 是一个线程安全的类,Hashtable 几乎所有的添加、删除、查询方法都加了synchronized同步锁!
相当于给整个哈希表加了一把大锁,多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞等待需要的锁被释放,在竞争激烈的多线程场景中性能就会非常差,所以 Hashtable 不推荐使用!
(2)Collections.synchronizedMap()

传入的是 HashMap 对象,其实也是对 HashMap 做的方法做了一层包装,里面使用对象锁来保证多线程场景下,操作安全,本质也是对 HashMap 进行全表锁!
使用Collections.synchronizedMap方法,在竞争激烈的多线程环境下性能依然也非常差,所以不推荐使用!
(3)ConcurrentHashMap(推荐使用)
分段锁技术。
二十三、HashMap初始化会初始化数组吗?若指定的长度不是2的次幂会怎么样?
1.7和1.8都遵循:
-
在put方法中发现数组为空才会创建Entry数组。
-
若指定长度不是2的次幂,则会选择大于该数的最近的2次幂数作为长度,如传10,则会初始化16的数组。
二十四、总结1.7和1.8HashMap的不同
-
数据结构,1.7是数组+链表,1.8是数组+链表+红黑树
-
元素对象,1.7是Entry,1.8是Node
-
链表插入方式,1.7是头插法,有死循环问题,1.8是尾插法,无死循环
-
初始化方式,1.7是put方法中调用inflateTable(int toSize)创建数组,resize()只负责扩容,1.8是resize()方法不单只负责扩容,在检测到数组为空时也会创建数组,去掉了inflateTable方法。
-
扩容时槽位计算方式,1.7是 hash & (newCap - 1),1.8是原索引或者索引+oldCap,(hash & oldCap)
-
hash函数,1.7是用key的hashcode复杂扰动处理,1.8是key的hashcode的高16位和低16位做”位异或“,扰动简单。
-
链表顺序,1.8rehash时保证原链表的顺序,而1.7中rehash时有可能改变链表的顺序(头插法导致)。
-
-
相关阅读:
Connection详解
maven-plugin-shade 详解1
MyBatisPlus实现分页和查询操作就这么简单
嵌入式软件架构设计-函数调用
JAVA宠物寄存中心计时收费系统计算机毕业设计Mybatis+系统+数据库+调试部署
OS复习笔记ch11-3
VR 在未来也许是一个好风口
Ubuntu系统-FFmpeg安装及环境配置
如何用好Nginx的gzip指令
trivy 获取基础镜像源码分析
- 原文地址:https://blog.csdn.net/weixin_44360895/article/details/126820361