-
python机器学习之门之sklearn的使用(使用鸢尾花数据集)
sklearn全称为scikit learn 专门提供了python机器学习的模块 是一个高效的数据分析算法工具 建议在numpy scipy matplotlib上
对于大多数机器学习 通常有以下四个数据集
1:train_data 训练数据集
2:train_target 训练数据的真是结果集
3:test_data 测试数据集
4:test_target 测试数据对应的真是结果 用来检测预测的正确性
sklearn模块提供了一个强大的数据库 包括鸢尾花 波士顿房价等等 下面用鸢尾花数据集做演示
鸢尾花(iris)数据集 是常用的分类实验数据集 由fisher在1936年收集整理,包含150个数据集 分为三类 每类五十条数据 每条数据包含4个属性。
效果图如下
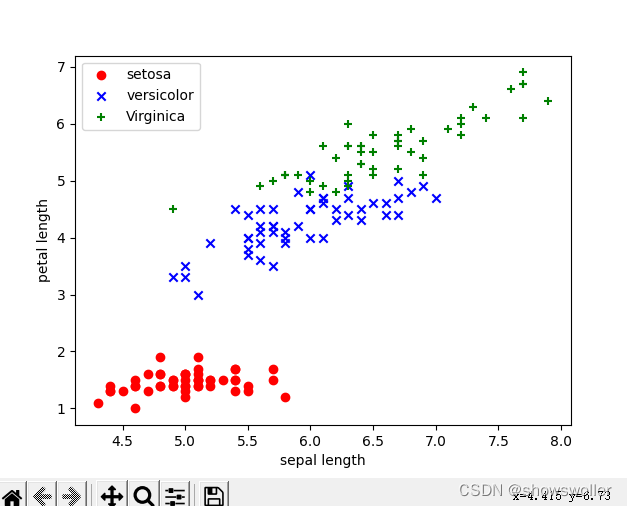
代码如下
- from sklearn.datasets import load_iris
- from sklearn.datasets import load_boston
- import matplotlib; matplotlib.use('TkAgg')
- import pandas as pd
- import matplotlib.pyplot as plt
- data=load_iris()
- print("以下是鸢尾花数据集")
- data =pd.DataFrame(data=load_iris().data,columns=load_iris().feature_names)#转换为dataframe对象
- print(data)
- x=data.iloc[:,[0,2]].values
- plt.scatter(x[:50,0],x[:50,1],color='red',marker='o',label='setosa')
- plt.scatter(x[50:100,0],x[50:100,1],color='blue',marker='x',label='versicolor')
- plt.scatter(x[100:,0],x[100:,1],color='green',marker='+',label='Virginica')
- plt.xlabel('sepal length')
- plt.ylabel('petal length')
- plt.legend(loc=2)
- plt.show()
觉得有帮助请点赞收藏
-
相关阅读:
mysql的服启动以及用户登录
记录:Unity脚本的编写5.0
基于pytorch的BP神经网络实现
div内文字水平居中+垂直居中
(七)C++中实现argmin与argmax
Windows电脑高颜值桌面便利贴,便签怎么设置
第一章 - Windows安装VMware Workstation Pro
内边距(padding会影响盒子内边距大小)
源码学习:AtomicInteger类代码内部逻辑
字体设计软件 Glyphs 2 mac中文版软件特点
- 原文地址:https://blog.csdn.net/jiebaoshayebuhui/article/details/126817921
