-
【Hadoop】学习笔记(四)
三、MapReduce
3.1 、 MapReduce概述
MapReduce:是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
3.2 、 MapReduce优缺点
优点:
- 易于编程:用户只关心业务逻辑,调用框架的接口即可
- 良好的扩展性:可以动态增加服务增加计算资源
- 高容错性:任何一台机器挂掉,可以将任务转移到其他节点
- 适合海量数据计算(TB/PB),几千台服务器共同计算
缺点:
- 不擅长实时计算。不能像Mysql一样处理毫秒级的计算
- 不擅长流式计算。可以用Sparkstreamming、Flink
- 不擅长DAG有向无环图计算。可以用Spark
“不擅长”不代表不能执行,只是没有其他专门的框架做的好。
3.3、MapReduce工作流程
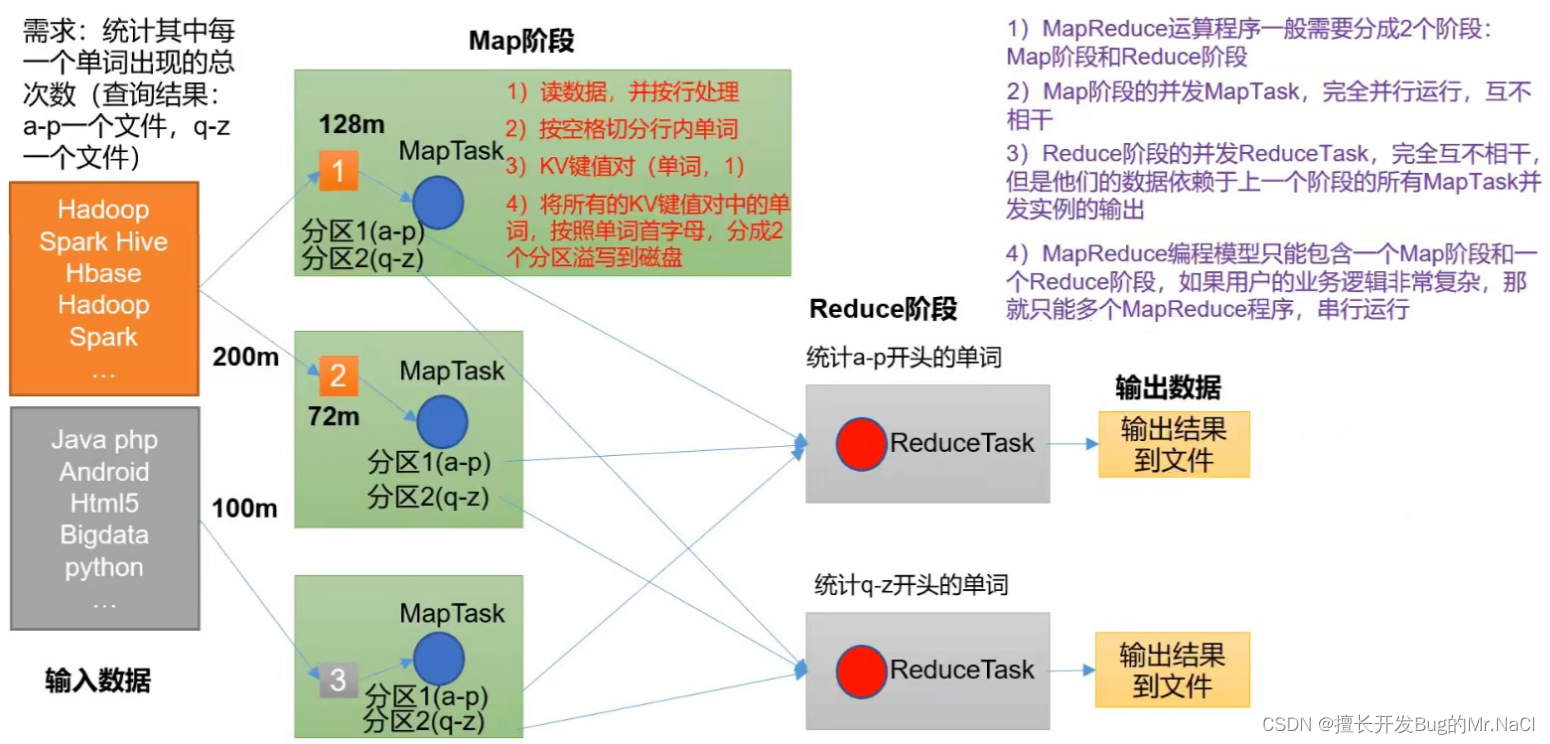
3.3.1、MapReduce进程
一个完整的MapReduce程序在分布式运行时有三类实例进程:
- MRAppMaster:负责整个程序的过程调度及状态协调
- MapTask:负责Map阶段的整个数据处理流程
- ReduceTask:负责Reduce阶段的整个数据处理流程
MRAppMaster是Yarn的ApplicationMaster的子类,管理一个任务(job,也称MR)。
MapTask、ReduceTask在进程列表中查不到,他们都属于查到 YarnChild进程。
3.3.2、MapReduce阶段
阶段组成:
● 一个MapReduce编程模型中,只能包含一个Map阶段和一个Reduce阶段,或者只有Map阶段;
● 不能有多个map阶段、多个reduce阶段的情景出现
● 如果用户的业务逻辑非常复杂,就只能使用多个MapReduce程序串行执行3.4、MapReduce的Java程序编写格式
Hadoop在Java数据类型基础上又封装了新的数据类型,这些类都实现了Hadoop的序列化接口Writable:位于 org.apache.hadoop.io包下
Java类型 Hadoop Writable类型 String Text Boolean BooleanWritable Byte ByteWritable Int IntWritable Float FloatWritable Long LongWtitable Double DoubleWritable Map MapWritable Array ArrayWritable Null NullWritable 3.5、MapReduce编程规范
用户编写的程序分为三个部分:
- Mapper
- Reducer
- Driver
3.5.1、Mapper
Mapper代码编写:
- 用户自定义的Mapper要继承Mapper类,传入的泛型为(<输入数据key的类型, 输入数据value的类型, 输出结果key的类型,输出结果value的类型>)
- Mapper的输入数据时Key-Value形式(key、value的类型可以自定义)
- 用户的实现类中需要重写Mapper类的map()方法,在方法中写业务逻辑
- Mapper的输出数据时key-value的形式(key、value的类型可以自定义)
- map()方法(MapTask进程)对每一个 key-value 调用一次,对输入的数据文件内容默认按行处理
以官方提供的WordCount示例程序中的Mapper为例
// 继承Mapper类,泛型为<输入数据key的类型, 输入数据value的类型, 输出结果key的类型,输出结果value的类型> // Text类型即为Hadoop封装的String类型 // IntWritable类型即为Hadoop封装的Int类型 // 输入数据中:key是偏移量,value是具体内容 public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); // 实现map()方法 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3.5.2、Reducer
Reducer编写:
- 用户自定义的Reducer需要继承Reducer类
- Reducer的输入数据类型对应Mapper的输出数据类型,也是 key-value 形式
- 用户的实现类中需要重写Reducer类的reduce()方法,在方法中写业务逻辑
- ReduceTask进程对每一组相同 key 的 key-value 组调用一次reduce()方法

以官方提供的WordCount实例程序中的Reducer为例:// 需要继承Reducer类,泛型为:<输入数据key的类型, 输入数据value的类型, 输出结果key的类型,输出结果value的类型> // Reducer输入数据的 key-value 即为 Mapper 的输出结果 key-value public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); // 需要重写reduce方法 // key 即为相同key的组的key // values 即为该key的value组的集合 public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3.5.3、Driver
相当于Yarn集群的客户端,用于提交我们整个程序到Yarn集群,提交的是封装了的MapReduce程序相关运行参数的job对象。
以官方提供的WordCount实例程序中的Reducer为例:
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length < 2) { System.err.println("Usage: wordcount[ ); System.exit(2); } Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); for (int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }...] " - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
-
相关阅读:
24-数据结构-内部排序-基数排序
华为OD应聘感受
ThreadFactory 实例创建方式
北极星指标|专家建议如何有效制订NSM以驱动增长
Redis总结:缓存雪崩、缓存击穿、缓存穿透与缓存预热、缓存降级
Word控件Spire.Doc 【表单域】教程(五):如何在 C# 中更新 Ask 字段
深入理解Linux网络笔记(三):内核和用户进程协作之epoll
线性表的链式存储的基本
有来实验室|第一篇:Seata1.5.2版本部署和开源全栈商城订单支付业务实战
滑动谜题 -- BFS
- 原文地址:https://blog.csdn.net/lushixuan12345/article/details/126160070
