-
注意力机制 - 注意力评分函数
注意力评分函数
在上一节中,我们使用高斯核来对查询和键之间的关系建模。我们看将高斯核指数部分视为注意力评分函数(attention scoring function),简称评分函数(scoring function),然后把这个函数的输出结果输入到softmax函数中进行运算。通过上述步骤,我们将得到与键对应的值的概率分布(即注意力权重)。最后,注意力汇聚的输出就是基于这些注意力权重的值的加权和
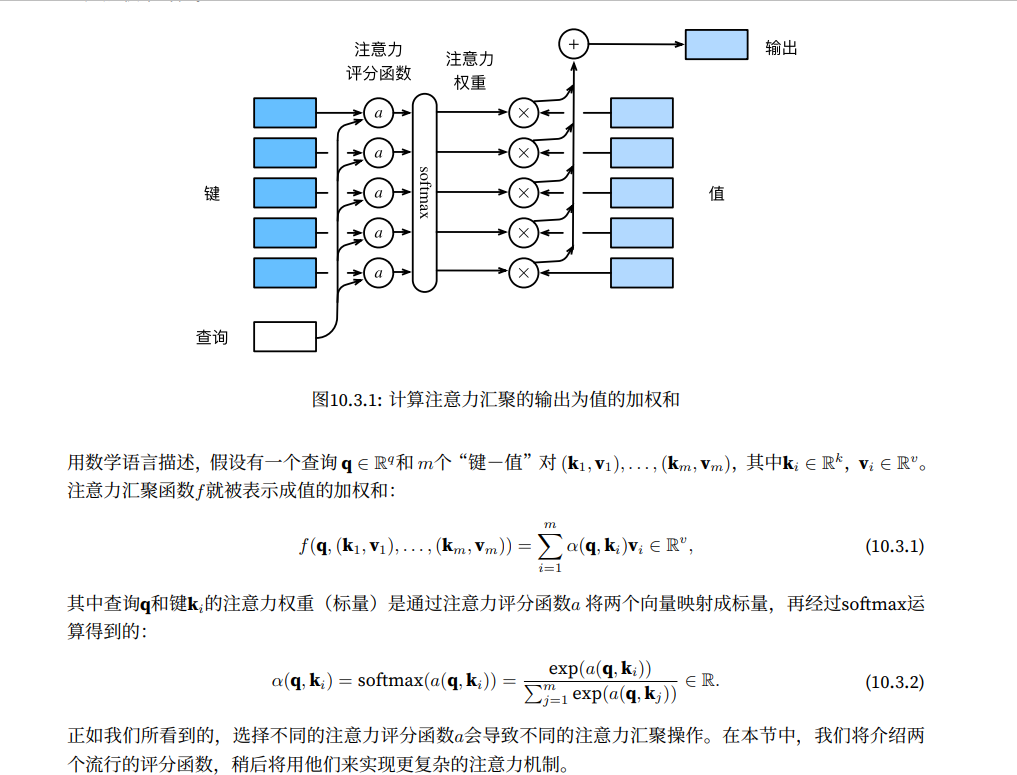
从宏观上来看,我们可以使用上述算法来实现图10.1.3中的注意力机制框架。图10.3.1说明了如何将注意力汇聚的输出计算成为值的加权和,其中a表示注意力评分函数。由于注意力权重时概率分布,因此加权和其本质上加权平均值
import math import torch from torch import nn from d2l import torch as d2l- 1
- 2
- 3
- 4
1 - 掩蔽softmax操作
正如上面提到的,softmax操作用于输出一个概率分布作为注意力权重。在某些情况下,并非所有的值都应该被纳入到注意力汇聚中。例如,为了在9.5节中高效处理小批量数据集,某些稳步序列被填充了没有意义的特殊词元。为了仅将有意义的词元作为值来获取注意力汇聚,我们可以指定一个有效序列长度(即词元个数),以便在计算softmax时过滤掉超出指定范围的位置。通过这种方式,我们可以在下面的masked_softmax函数中实现这样的掩蔽softmax(masked softmax operation),其中任何超出有效长度的位置都比掩蔽并置为0
def masked_softmax(X,valid_lens): """通过在最后一个轴上掩蔽元素来指向softmax操作""" # X:3D张量,valid_lens:1D或2D张量 if valid_lens is None: return nn.functional.softmax(X,dim=-1) else: shape = X.shape if valid_lens.dim() == 1: valid_lens = torch.repeat_interleave(valid_lens,shape[1]) else: valid_lens = valid_lens.reshape(-1) # 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0 X = d2l.sequence_mask(X.reshape(-1,shape[-1]),valid_lens,value=-1e6) return nn.functional.softmax(X.reshape(shape),dim=-1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
演示此函数工作,考虑两个2 * 4矩阵的样本,这两个样本的有效长度分别为2和3。经过掩蔽softmax操作,超出有效长度的值都被掩蔽为0
masked_softmax(torch.rand(2,2,4),torch.tensor([2,3]))- 1
tensor([[[0.3705, 0.6295, 0.0000, 0.0000], [0.3973, 0.6027, 0.0000, 0.0000]], [[0.2554, 0.4588, 0.2858, 0.0000], [0.2614, 0.3880, 0.3506, 0.0000]]])- 1
- 2
- 3
- 4
- 5
同样,我们也可以使用二维张量,为矩阵样本中的每一行指定有效长度
masked_softmax(torch.rand(2,2,4),torch.tensor([[1,3],[2,4]]))- 1
tensor([[[1.0000, 0.0000, 0.0000, 0.0000], [0.4917, 0.2622, 0.2461, 0.0000]], [[0.5529, 0.4471, 0.0000, 0.0000], [0.2014, 0.2771, 0.2170, 0.3045]]])- 1
- 2
- 3
- 4
- 5
2 - 加性注意力

class AdditiveAttention(nn.Module): """加性注意⼒""" def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs): super(AdditiveAttention, self).__init__(**kwargs) self.W_k = nn.Linear(key_size, num_hiddens, bias=False) self.W_q = nn.Linear(query_size, num_hiddens, bias=False) self.w_v = nn.Linear(num_hiddens, 1, bias=False) self.dropout = nn.Dropout(dropout) def forward(self, queries, keys, values, valid_lens): queries, keys = self.W_q(queries), self.W_k(keys) # 在维度扩展后, # queries的形状:(batch_size,查询的个数,1,num_hidden) # key的形状:(batch_size,1,“键-值”对的个数,num_hiddens) # 使⽤⼴播⽅式进⾏求和 features = queries.unsqueeze(2) + keys.unsqueeze(1) features = torch.tanh(features) # self.w_v仅有⼀个输出,因此从形状中移除最后那个维度。 # scores的形状:(batch_size,查询的个数,“键-值”对的个数) scores = self.w_v(features).squeeze(-1) self.attention_weights = masked_softmax(scores, valid_lens) # values的形状:(batch_size,“键-值”对的个数,值的维度) return torch.bmm(self.dropout(self.attention_weights), values)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
查询、键和值的形状为(批量大小,步数或词元序列长度,特征大小),实际输出为(2,1,20)、(2,10,2)和(2,10,4)
注意力汇聚输出的形状为:(批量大小,查询的步数,值的维度)
queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2)) # values的⼩批量,两个值矩阵是相同的 values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1) valid_lens = torch.tensor([2, 6]) attention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8, dropout=0.1) attention.eval() attention(queries, keys, values, valid_lens)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]], [[10.0000, 11.0000, 12.0000, 13.0000]]], grad_fn=) - 1
- 2
- 3
尽管加性注意力包含了可学习的参数,但由于本例子中每个键都是相同的,所以注意力权重是均匀的,由指定的有效长度决定
d2l.show_heatmaps(attention.attention_weights.reshape((1,1,2,10)),xlabel='Keys',ylabel='Queries')- 1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YzJo1nsL-1662988414484)(https://yingziimage.oss-cn-beijing.aliyuncs.com/img/202209122107123.svg)]
3 - 缩放点积注意力

class DotProductAttention(nn.Module): """缩放点积注意力""" def __init__(self,dropout,**kwargs): super(DotProductAttention,self).__init__(**kwargs) self.dropout = nn.Dropout(dropout) # queries的形状为:(batch_size,查询的个数,d) # keys的形状:(batch_size,“键-值”对的个数,d) # values的形状:(batch_size,“键-值”对的个数,值的维度) # valid_lens的形状:(batch_size,)或者(batch_size,查询的个数) def forward(self,queries,keys,values,valid_lens=None): d = queries.shape[-1] # 设置transpose_b = True为了交换keys的最后两个维度 scores = torch.bmm(queries,keys.transpose(1,2)) / math.sqrt(d) self.attention_weights = masked_softmax(scores,valid_lens) return torch.bmm(self.dropout(self.attention_weights),values)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
我们使用与先前加性注意力例子中相同的键、值和有效长度
对于点积操作,我们令查询的特征维度与键的特征维度大小相同
queries = torch.normal(0,1,(2,1,2)) attention = DotProductAttention(dropout=0.5) attention.eval() attention(queries,keys,values,valid_lens)- 1
- 2
- 3
- 4
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]], [[10.0000, 11.0000, 12.0000, 13.0000]]])- 1
- 2
- 3
与加性注意力演示相同,由于键包含的是相同的元素,而这些元素无法通过任何查询进行区分,因此获得了均匀的注意力权重
d2l.show_heatmaps(attention.attention_weights.reshape((1,1,2,10)),xlabel='Keys',ylabel='Queries')- 1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jZGITb0X-1662988414484)(https://yingziimage.oss-cn-beijing.aliyuncs.com/img/202209122107124.svg)]
4 - 小结
- 将注意力汇聚的输出计算可以作为值的加权平均,选择不同的注意力评分函数会带来不同的注意力汇聚操作
- 当查询和键是不同长度的矢量时,可以使用可加性注意力评分函数。当它们的长度相同时,使用缩放的“点-积”注意力评分函数的计算效率更高
-
相关阅读:
SSM框架-Spring(二)
C语言中关于#include的一些小知识
英集芯IP5566带TYPE-C口3A充放快充移动电源5w无线充二合一方案SOC
MySQL基础运维知识点大全
SystemVerilog——过程语句和子程序
Docker搭建Redis集群
mysql redo 日志 、 undo 日志 、binlog
聚焦新一代技术平台,智能低代码平台成为新趋势
(蓝桥杯第十四届c解法,部分题目)一、冶炼金属二、飞机降落
FFmpeg源代码:av_read_frame
- 原文地址:https://blog.csdn.net/mynameisgt/article/details/126822984