-
Flink中的Window计算-增量计算&全量计算
flink是一个流处理引擎,可以实现基于每条消息实时计算,但是在有些业务系统开发中,并不需要按照消息维度的数据计算,更多的是指定时间内的一批消息的计算,比如:过去1分钟内,产生消息个数、消息中的最大值等。
这个时候,就需要对数据流按照时间切分成一个个小的“时间窗口”,然后对这个时间窗口内的数据按照自定义的处理逻辑进行处理。
时间语义
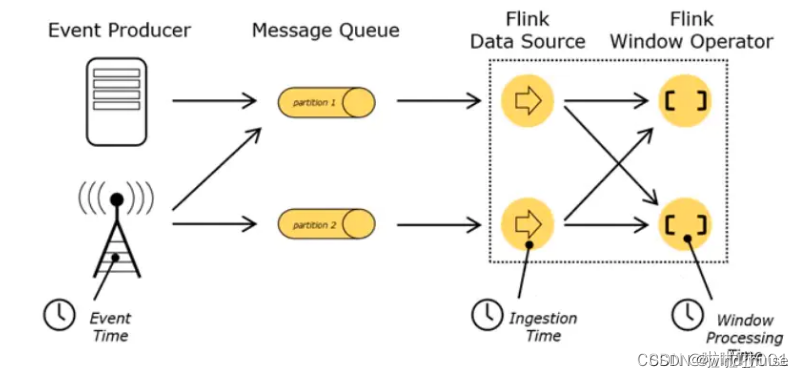
这里需要定义一下:"将数据流按照时间切分成一个个窗口"中的时间,具体是什么时间,因为在flink中,时间的语义有3种,
一个是数据产生的时间,我们把它叫作“事件时间”(Event Time);
一个是数据真正被处理的时刻,叫作“处理时间”(Processing Time);
一个是指数据进入Flink的时间,是 DataSource 拿到数据的时间,叫做“进入Flink的时间”(Ingestion Time);
具体可以参考下图:
处理时间(Processing Time)
处理时间 :就是指执行处理操作的机器的系统时间。
如果我们以它作为衡量标准,那么数据属于哪个窗口,只看这个窗口任务处理这条数据时的系统时间。
事件时间(Event Time)
事件时间:是指每个事件在对应的设备上发生的时间,也就是数据生成的时间。
数据一旦产生,这个时间自然就确定了,所以它可以作为一个属性嵌入到数据中。这其实就是这条数据记录的“时间戳”(Timestamp),那这个数据属于哪个窗口,就取决于时间产生的事件。
举例来说:如果一条消息产生的时间是44分,而在flink中被处理的时间是46分,在一个长度为5分钟时间窗口中,如果按照事件发生时间计算的话,那么这个消息属于40-45分钟的时间窗口,如果按照"处理时间"计算的话,那么这个消息属于45-50的时间窗口。如下图所示:

不过在按照事件发生时间的时间语义中,由于网络传输延迟等客观因素,会存在消息乱序到达的问题:先产生的消息到达系统的时间,晚于后产生消息到达系统的时间,那么属于一个时间窗口中的消息,何时全部到达就成了一个不确定的问题,那么这个窗口何时被触发计算,也就不确定了。如果触发的早了,那么后续到达且属于这个窗口的消息,就无法被计算了,为了解决这个问题,在flink中提出了 Watermarks 的概念,虽然 Watermarks 并没有彻底解决这个问题,但是对使用者提供了一种可配置且能够缓解这个问题的通用解决方案,有兴趣的读者可以深入了解一下。
进入Flink的时间(Ingestion Time)
进入Flink的时间:是指数据进入Flink的时间,是 DataSource 拿到数据的时间;
关于时间语义的设置,在代码中可以使用如下方式进行时间语义的配置
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);- 1
开窗函数
按照窗口函数处理窗口内消息的方式的差异,可以将窗口函数分为增量计算和全量计算。其实在flink中窗口的类型也有三种:滑动窗口,滚动窗口和回话窗口。有兴趣的读者可以深入了解一下,下文介绍中的窗口类型主要以滚动窗口为主。
增量计算
增量计算是指:每来一条数据就立即进行计算,每次计算的中间结果作为一个状态进行存储,不会发送到下游算子,等到窗口结束时间,才会将最终的计算结果记性输出。这样可以大大提高了程序运行的效率和实时性,如ReduceFunction和AggregateFunction等,在代码中使用如下:
sourceStream.keyBy(value -> value) .timeWindow(Time.seconds(5)) .aggregate(new SumAggregateFunction(),new SumWindowProcessFunction())- 1
- 2
- 3
全量计算
与增量计算不同,全量计算函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出所有数据进行计算。
很显然这就是典型的批处理思路了:先攒数据,等一批都到齐了,再正式启动处理流程。这样做毫无疑问是低效的:因为窗口全部的计算任务都积压在了要输出结果的那一瞬间,而在之前收集数据的漫长过程中却什么都不做。这就好比上学的时候,平时不用功,到考试之前通宵抱佛脚,肯定不如把工夫花在日常积累上。
那为什么还需要有全窗口函数呢?这是因为有些场景下,我们需要做的计算需要整个窗口的全局数据,比如:对窗口中的所有数据进行排序后输出,这时做增量聚合就没什么意义了。
在代码中使用如下:
sourceStream.keyBy(value -> value) .timeWindow(Time.seconds(5)) .process(new ProcessWindowFunction<String, String, String, TimeWindow>())- 1
- 2
- 3
案例说明
下面我们用一个wordCount的程序:对一个数据流中的单词的个数进行统计,来演示增量计算和全量计算的差异。
一些工具类代码:
public class StreamExecutionEnvBase { // Flink流处理环境构建 public static StreamExecutionEnvironment getStreamEnv(Integer webUiPort) { Configuration conf = new Configuration(); conf.setString("rest.port",String.valueOf(webUiPort)); StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf); return env; } // Source 数据源 public static SourceFunction<String> getStringSource(int count, Integer sleep) { String[] values = {"hadoop","flink","spark","redis"}; return new SourceFunction<String>() { volatile boolean isRunning = true; int c = count; @Override public void run(SourceContext<String> sourceContext) throws Exception { while (c > 0 && isRunning) { String target = values[ c % values.length]; sourceContext.collect(target); c --; TimeUnit.MILLISECONDS.sleep(sleep); } // 防止主进程提前退出 TimeUnit.SECONDS.sleep(100); } @Override public void cancel() { isRunning = false; System.out.println("cancel ......"); } }; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
增量计算说明
在进行增量计算时,我们使用aggregate方法。
public class IncrementWindowFunction { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvBase.getStreamEnv(9091); DataStreamSource<String> sourceStream = env.addSource(StreamExecutionEnvBase.getStringSource(100, 100)); sourceStream.keyBy(value -> value) .timeWindow(Time.seconds(5)) .aggregate(new SumAggregateFunction(),new SumWindowProcessFunction()) .print("increment"); env.execute("keyed stream"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
主程序:按照每种单词生成一种key,将DataStream转换成KeyedStream,然后每5s生成一个WindowStream进行窗口计算。
增量计算的关键代码:
public class SumAggregateFunction implements AggregateFunction<String,SumAcc,SumAcc> { @Override public SumAcc createAccumulator() { return new SumAcc(); } @Override public SumAcc add(String s, SumAcc sumAcc) { sumAcc.acc(s); return sumAcc; } @Override public SumAcc getResult(SumAcc sumAcc) { return sumAcc; } @Override public SumAcc merge(SumAcc sumAcc, SumAcc acc1) { return null; } } public class SumAcc { private Map<String,Integer> sumMap = new HashMap<>(); // 累计计算 public void acc(String key) { if(sumMap.containsKey(key)) { sumMap.put(key,sumMap.get(key) + 1); } else { sumMap.put(key,1); } } public Map<String, Integer> getSumMap() { return sumMap; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
窗口计算函数:
public class SumWindowProcessFunction extends ProcessWindowFunction<SumAcc, String, String, TimeWindow> { // 每一个key的数据,在window结束的时候,调用该方法 @Override public void process(String s, Context context, Iterable<SumAcc> iterable, Collector<String> collector) throws Exception { for (SumAcc sumAcc : iterable) { for (Map.Entry<String,Integer> entry : sumAcc.getSumMap().entrySet()) { String result = String.format("key:%s,count:%s",entry.getKey(),entry.getValue()); collector.collect(result); } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出结果如下:
increment:7> key:flink,count:7 increment:1> key:redis,count:7 increment:8> key:hadoop,count:8 increment:1> key:spark,count:7 increment:1> key:redis,count:13 increment:8> key:hadoop,count:12 increment:7> key:flink,count:12 increment:1> key:spark,count:12 increment:7> key:flink,count:6 increment:1> key:spark,count:6 increment:8> key:hadoop,count:5 increment:1> key:redis,count:5- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
将所有count加一起刚好是 100,和输入的单词个数是相同的。
全量计算说明
在进行全量计算时,我们使用process方法。具体代码如下:
public class TotalWindowFunctionTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvBase.getStreamEnv(9091); DataStreamSource<String> sourceStream = env.addSource(StreamExecutionEnvBase.getStringSource(100, 100)); sourceStream.keyBy(value -> value) .timeWindow(Time.seconds(5)) .process(new ProcessWindowFunction<String, String, String, TimeWindow>() { Map<String,Integer> map = new HashMap<>(); @Override public void process(String s, Context context, Iterable<String> elements, Collector<String> collector) throws Exception { for (String str : elements) { if(map.containsKey(str)) { map.put(str,map.get(str) + 1); }else { map.put(str,1); } } for (Map.Entry<String,Integer> entry : map.entrySet()) { collector.collect(String.format("key:%s,count:%s",entry.getKey(),entry.getValue())); } } }) .print("total"); env.execute("total stream"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
输出结果如下:
total:8> key:hadoop,count:1 total:1> key:redis,count:1 total:1> key:spark,count:1 total:1> key:redis,count:1 total:8> key:hadoop,count:13 total:7> key:flink,count:13 total:1> key:spark,count:1 total:1> key:redis,count:13 total:1> key:spark,count:13 total:1> key:redis,count:13 total:8> key:hadoop,count:25 total:1> key:spark,count:13 total:7> key:flink,count:25 total:1> key:redis,count:25 total:1> key:spark,count:25 total:1> key:redis,count:25- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
和增量不同的是,全量计算最后一次输出的结果就是之前所有窗口加和,总数也是100。
通过代码我们知道,两者的计算逻辑是相同的,那么为什么最终输出的结果却是不同的的呢?
下面我们从两种计算方式的流程上做一下拆解,来解释以下两者的差异:
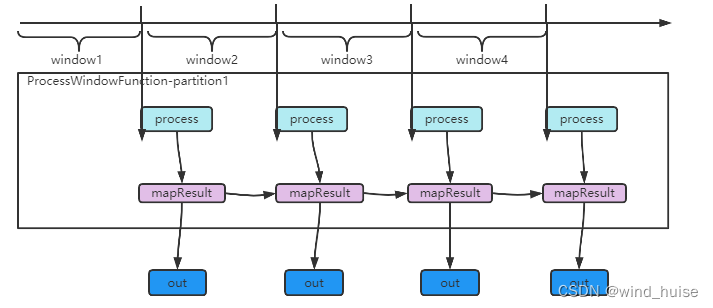
全量计算的执行流程:
上文我们说过,全量计算只有在到达窗口结束时间时,才会触发计算。flink在对KeyedStream进行window计算时,会为KeyedStream中的每个分区创建一个 ProcessWindowFunction 对象,来专门处理该分区内的数据。
因此在ProcessWindowFunction#process方法中的入参 elements 是一个 Iterable 类型,在这个迭代器中,包含了该窗口中的所有元素。
因为在整个应用程序的生命周期中,每个keyedStream分区,只会创建一个 ProcessWindowFunction对象,因此上述的计算逻辑中,每个窗口的计算结果都保存在了“map” 中, 输出的结果就变成了前面所有window计算结果的汇总。
计算流程如下图:
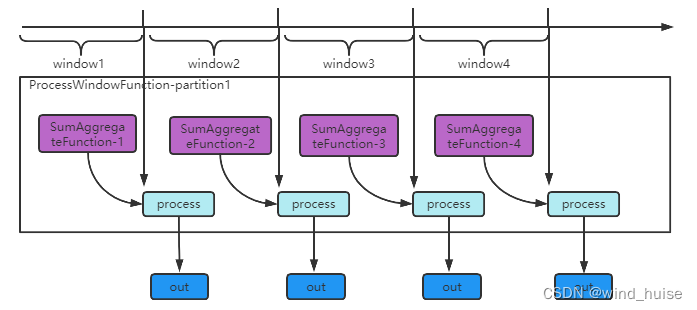
增量计算的流程:
虽然 SumWindowProcessFunction#process方法中的入参 elements 也是一个 Iterable 类型,但是这个迭代器中只有一个元素,因为窗口中的所有消息在进入flink中时,会立即被 SumAggregateFunction 进行聚合处理,所以当到达窗口结束时间时,窗口中的所有消息都被 SumAggregateFunction 聚合一个元素了。
而且,在增量计算中,flink给KeyedStream中的每个分区在一个window内分配一个 SumAggregateFunction 对象,也就是说,同一个分区,在不同的window内,使用的 SumAggregateFunction 对象都是新的,所以 SumAggregateFunction不会累计前面window中的数据。
计算流程如下图:
到这里,对于增量计算和全量计算的差异和对应方法的触发时机,应该就很清楚了,在两者的选择上,如果业务逻辑上不需要窗口中全局数据的话,尽量选择增量计算的方式,因为可以充分利用flink中的计算资源。
-
相关阅读:
Springboot使用Knife4j
With As多表查询
面试官:单核 CPU 支持 Java 多线程吗?为什么?被问懵了!
设计模式-原型模式
Unity的live2dgalgame多语言可配置剧情框架
ubuntu Setforeground 前台应用切换
string模拟实现
【IDEA】在IntelliJ IDEA中导入Eclipse项目:详细指南
Dubbo invoke命令使用
Elasticsearch实战(十八)--ES搜索Doc Values/Fielddata 正排索引 深入解析
- 原文地址:https://blog.csdn.net/weixin_45701550/article/details/126820319
