-
ES_深度分页概念与解决方案
ES_深度分页概念与解决方案
一.深度分页问题
假如现在要查询990~1000的数据,查询逻辑要这么写:
GET /hotel/_search { "query": { "match_all": {} }, "from": 990, # 分页开始的位置,默认为0 "size": 10, # 期望获取的文档总数 "sort": [ {"price": "asc"} ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这里是查询990开始的数据,也就是 第990~第1000条 数据。
单节点es的分页查询逻辑
elasticsearch内部分页时,必须先查询 0~1000条,然后截取其中的990 ~ 1000的这10条:

查询TOP1000,如果es是单点模式,这并无太大影响。
es集群的分页查询逻辑
但是elasticsearch将来一定是集群,例如我集群有5个节点,我要查询TOP1000的数据,并不是每个节点查询200条就可以了:因为节点A的TOP200,在另一个节点可能排到10000名以外了。
因此要想获取整个集群的TOP1000,必须先查询出每个节点的TOP1000,汇总结果后,重新排名,重新截取TOP1000。

那如果我要查询9900~10000的数据呢?是不是要先查询TOP10000呢?那每个节点都要查询10000条?汇总到内存中?
当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力,因此elasticsearch会禁止from+ size 超过10000的请求。
二.深度分页解决方案
1、限制请求
Es进行限制的10000+的数据.而淘宝则对深度分页处理则很直接,限制分页页数.超过100页后面的数据,基本认为是无效数据.则会丢弃这些数据.
2、scroll:
原理 :
将排序后的文档id形成快照,保存在内存。官方已经不推荐使用。使用scroll滚动搜索,一次性查出一部分数据,降低服务器的压力. 第一次查询需要设置超时时间, 在第一次查询后生成
_scroll_id下次查询会携带这个值. 把它作为起始只查询对应size个数据.3、search after:
原理
分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。第一次查询
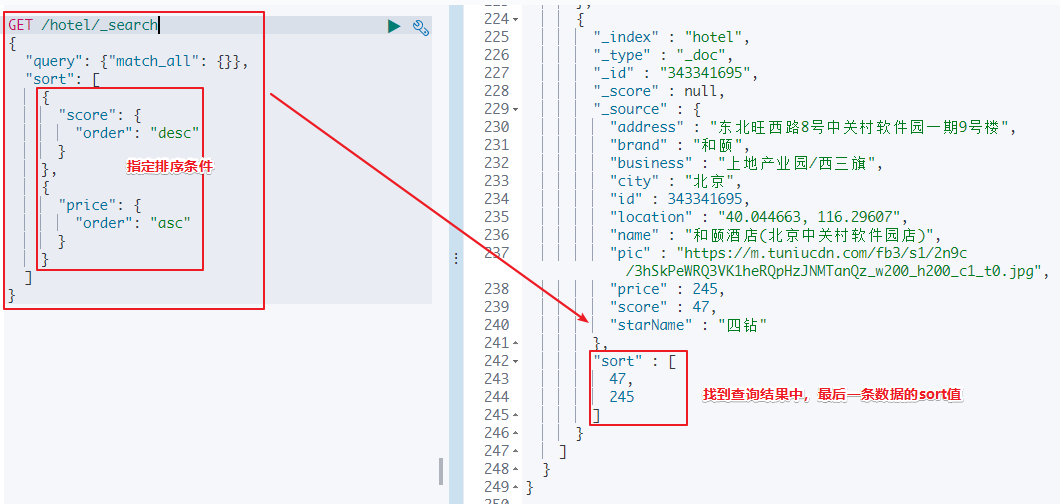
下一次查询
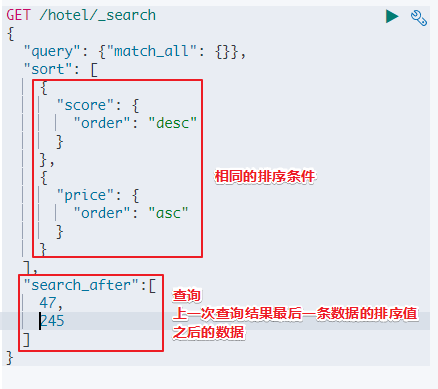
注意
要保证排序值是唯一不重复的,否则分页时可能会漏掉数据。
期望结果:
- 第一次查询:最后一条数据的排序值是 score=47,price=245。 score=47,price=245的数据只有一条
- 下一次查询:查询 score=47,price=245之后的数据,没有任何问题
但是如果:
- score=45,price=245的数据有多条,假定为doc1、doc2
- 第一次查询第一页时,顺序是doc1、doc2,这一页刚好查询到了doc1
- 查询下一页时,顺序是doc2、doc1,从第2条开始,查询到了doc1
- 最终就漏掉了doc2
解决方案:
- 建议保证排序条件值不重复,就不会出现上面的问题了
- 例如:以score降序、price升序、
_id降序。_id是文档的唯一标识,是不重复的
-
相关阅读:
docker入门加实战—Docker镜像和Dockerfile语法
集群中增加数据节点与退役数据节点
Python(1)——如何配置pip私有源
【操作系统】32进制小数转10进制
单向链表·初识【c语言】
尚硅谷大数据项目《在线教育之实时数仓》笔记003
ChatGPT是否可以协助人们提高公共演讲和表达能力?
1462. 课程表 IV-深度优先遍历
MyBatis学习:MyBatis框架下执行SQL语句传递实体类参数
宝塔反代openai官方API接口详细教程,502 Bad Gateway问题解决
- 原文地址:https://blog.csdn.net/weixin_49904442/article/details/126817815