-
归并排序详解
前言
在前几篇博客中介绍了插入排序、选择排序、交换排序等内容,本篇博客则主要介绍归并排序,原因无他,其也依然是一种很优秀的排序;

1.归并排序的介绍
归并排序是建立在归并操作的一种有效的排序算法,该算法是采用分治法的一个很典型的应用;将已有序的序列进行合并,得到完全有序的序列;即子序列先有序然后回归合并形成一个新的有序的序列。
将上述意思翻译过来就是,将一个大问题分解成若干个小问题;也就是说将一个待排序的序列分解成两个规模大致相等的子序列,不断向下分解,直至子序列中元素个数为1,此时前面这个过程称之为分解;将分解后的序列进行有序合并到原来的序列中;这种算法就叫做归并排序!
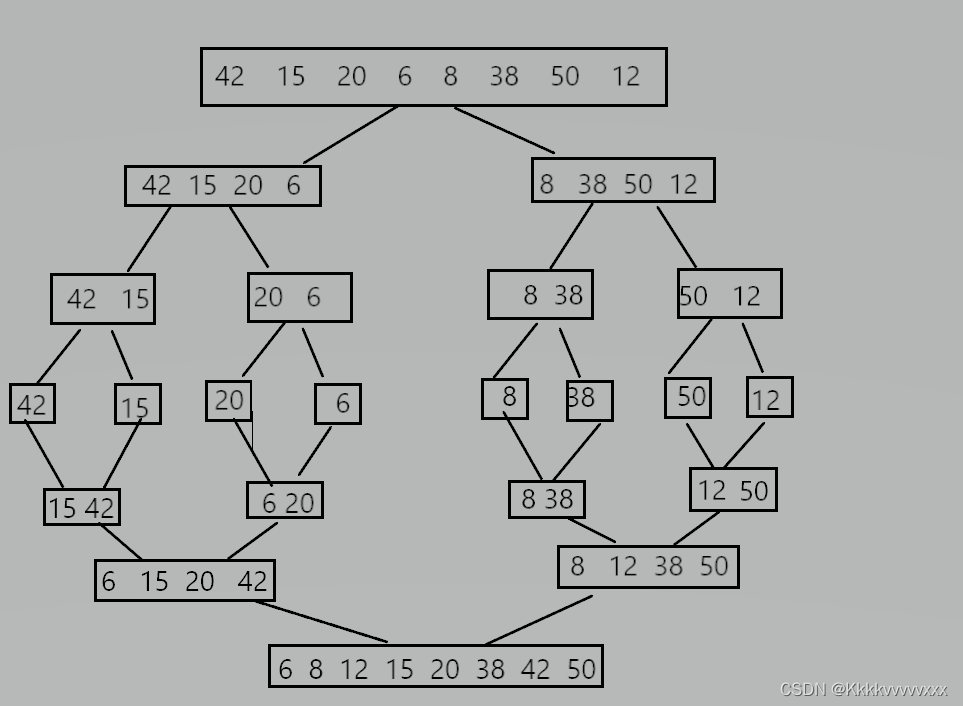
下面给出例子感受归并排序的思路:
2.代码实现及分析
2.1归并
引入一个辅助数组temp[],设置begin1,begin2为两个待排序子序列中的起始位置,end1,end2是两个待排序子序列中的结束位置,设置 i 指向辅助数组==temp[]==中待放置元素的位置。比较arr[begin1]和arr[begin2],将较小值赋给辅助数组temp[],同时相应的位置向后移动即可。
合并的过程相对简单,在此就不进行演示了,不清楚的可以自行画一下流程或者进行调试即可:
int mid = (left + right) / 2; int begin1 = left; int end1 = mid; int begin2 = mid + 1; int end2 = right; int i = left; while (begin1 <= end1 && begin2 <= end2) { if (arr[begin1] <= arr[begin2]) { temp[i++] = arr[begin1++]; } else { temp[i++] = arr[begin2++]; } } while (begin1 <= end1) { temp[i++] = arr[begin1++]; } while (begin2 <= end2) { temp[i++] = arr[begin2++]; } //将排好序的数组temp重新放回arr中 memcpy(arr+left, temp+left, sizeof(int)*(right-left+1));- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2.2递归实现归并排序
那么不断将区间进行分解,如上图给出的例子一样,当分解到序列中只有一个数据的时候开始进行合并操作,因此也就有了下面的递归操作,先分解数组在进行合并。
void _MergeSortRecursion(int* arr, int left, int right, int* temp) { if (left >= right) return; //取中 int mid = (left + right) / 2; //[left,mid]和[mid+1,right] //划分区间进行分解 _MergeSortRecursion(arr, left, mid, temp); _MergeSortRecursion(arr, mid+1, right, temp); int begin1 = left; int end1 = mid; int begin2 = mid + 1; int end2 = right; int i = left; while (begin1 <= end1 && begin2 <= end2) { if (arr[begin1] <= arr[begin2]) { temp[i++] = arr[begin1++]; } else { temp[i++] = arr[begin2++]; } } while (begin1 <= end1) { temp[i++] = arr[begin1++]; } while (begin2 <= end2) { temp[i++] = arr[begin2++]; } //将排好序的数组temp重新放回arr中 memcpy(arr+left, temp+left, sizeof(int)*(right-left+1)); } void MergeSortRecursion(int* arr, int n) { int* temp = (int*)malloc(sizeof(int) * n); if (temp == NULL) { perror("malloc fail"); return; } _MergeSortRecursion(arr, 0, n - 1, temp); free(temp); temp = NULL; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
这就是归并排序的递归版本,要注意mid对于划分区间有着重要的作用;其中memcpy这个库函数在前面的博客字符串相关函数中我介绍过,起作用就是将src空间的数据按提供的字节数拷贝进dst空间,相比于strcpy控制的更加细致,而且可以操控各种数据,在此就不过多介绍了。
2.3非递归实现归并排序
在了解完递归实现归并排序后,继而有非递归的版本,其实在先前的递归中,如果进行过调试或者手动画出过相关的流程的话,不难得出其归并的区间:

上图就可以很好的体现出归并时相关区间的范围,也就是说先两个数据有序的合并到一个区间,此时这个区间就存在2个数据了,依次类推,再将两个这样的区间在此进行有序合并,重复这个过程即可完成数组的排序。而上述区间划分等内容在非递归中则需要进行严格控制!
//非递归实现归并排序 void MergeSortNonRecursion(int* arr, int n) { int* temp = (int*)malloc(sizeof(int) * n); if (temp == NULL) { perror("malloc fail"); return; } int gap = 1; while (gap < n) { for (int j = 0; j < n; j += 2 * gap) { int begin1 = j, end1 = j + gap - 1; int begin2 = j + gap, end2 = j + 2 * gap - 1; int i = j; // if (end1 >= n) { break; } if (begin2 >= n) { break; } if (end2 >= n) { //修正 end2 = n - 1; } // printf("[%d,%d] [%d,%d] ",begin1, end1, begin2, end2); while (begin1 <= end1 && begin2 <= end2) { if (arr[begin1] <= arr[begin2]) { temp[i++] = arr[begin1++]; } else { temp[i++] = arr[begin2++]; } } while (begin1 <= end1) { temp[i++] = arr[begin1++]; } while (begin2 <= end2) { temp[i++] = arr[begin2++]; } //每进行一次for循环就拷贝一次,而每次处理的数据位置是不一样的,所以按照位置拷贝返回 //end2是第二组的最大值,end-j+1就是数据个数 memcpy(arr+j, temp+j, (end2-j+1) * sizeof(int)); } printf("\n"); gap *= 2; } free(temp); temp = NULL; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
下面关于非递归的代码进行解释:
1.为什么设定gap=1开始,gap的含义是什么呢?
gap其实就是划分的子序列中元素的个数,也就是划分左右子区间后这个区间的元素个数;而gap=1则就是上图划分的第一行内容即:
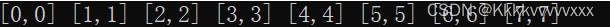
也就是将数据个数为1的序列进行两两合并,之后每次给gap*2也就是前面我们分析的,最后也就会形成一个有序的序列了。2.代码中的if else 等条件是做什么用的呢?
第一个问题当中,gap的大小也代表了序列的数据个数,此时就存在了当划分成2个序列后,这2个序列数据个数相加即2*gap是大于n的,此时第2个序列就存在全部越界和部分越界的问题了,所以需要进行优化修正处理!
3.memcpy在程序中如何进行拷贝?
每进行一次for循环拷贝一次,也就是说只要完成1次for循环temp数组中排序好的部分数据就会拷贝给源数组中,所以拷贝的起始位置也要根据for循环中的 j 的不同而改变,同理拷贝进去的数据个数要随着gap的不同而改变,但是却是借助着end2去实现的,这一点可以结合例子去体会,不清楚的可以私信或者评论🤠
相比较于其他排序,归并排序的效率也很不错:O(n * log n)
;Ending
关于归并排序的介绍也就到此为止了,唯一比较麻烦的就是非递归版本的边界问题;对于递归版本而言最高效的理解就是画出递归的函数调用图,这样就可以很直观的感受到递归时的函数区间边界问题了!

-
相关阅读:
使用Docker部署ElasticSearch与kibana
maven 通过参数动态设置打包方式(jar 或 war)
bootz启动 Linux内核过程总结
找不到mfc110.dll,无法执行代码
谁在抢夺千亿老酒
第一季:7Spring Bean的作用域之间有什么区别【Java面试题】
CRC校验原理及步骤
【高等数学】弧微分、渐近线、曲率和曲率半径
TS中 Interface 与 Type 的区别
[ Windows ] ping IP + Port 测试 ip 和 端口是否通畅
- 原文地址:https://blog.csdn.net/weixin_57248528/article/details/126816095
