-
TreeMap和LinkedHashMap
TreeMap
总体特点:(主要是跟linkedHashMap比较)
-
底层是基于红黑树实现,是个有序集合,按照key的compareTo方法或在构造时传入的Comparator比较器进行排序。这里需要注意如果在构造 时没有传入Comparator,那么key必须实现Comparable接口,不然会报错
-
TreeMap是通过Comparator比较器来构建红黑树从而保证key的有序性,而LinkedHashMap是通过双向链表来保证元素插入的有序性,两者有序性的含义不是一样的
-
TreeMap继承于AbstractMap,linkedHashMap继承于HashMap.TreeMap里面只维护红黑树这个数据结构,而LinkedHashMap是数组+单向链表+双向链表结构。TreeMap的所有增删改查的操作都是对红黑树的操作,而LinkedHashMap的增删改查操作是先对数组的操作,再对双向链表的操作,遍历的时候是遍历的双向链表
-
TreeMap主要用在需要排序的场景(还可以实现一致性hash算法),LinkedHashMap主要用在需要加密、签名、jvm缓存场景
LinkedHashMap
总体特点:
-
继承于HashMap,主要一些集合操作方法使用的都是父类HashMap中的方法,然后在创建节点时覆盖了newNode(int hash, K key, V value, Node

-
linkedHashMap内部是一个双向链表,是一个有序集合,他的有序主要是维护元素的插入顺序。主要实现了HashMap中的afterNodeAccess、afterNodeInsertion、afterNodeRemoval方法,afterNodeAccess在集合元素被访问(如put,get时)做一些操作,afterNodeInsertion在新元素插入时做一些操作,afterNodeRemoval在元素被删除时做一些操作,这些方法在LinkedHashMap都会对其维护的链表做相应的处理
-
LinkedHashMap中有一个很重要的变量是accessOrder,默认是false,意思是当LinkedHashMap元素被访问时需不需要调整元素的顺序,默认是不需要调整,如果是true则是需要调整,然后会把每次访问的元素调整到链表的尾部
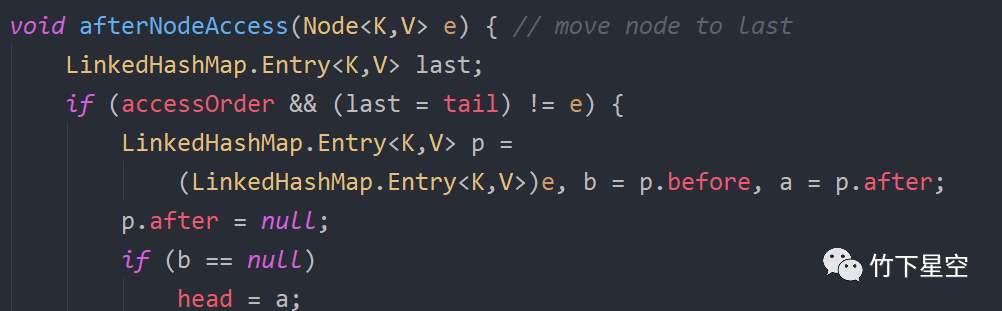
实战经验及使用场景:
-
LinkedHashMap很适合是使用在需要签名或加密的场景,因为他能保证插入元素的顺序性
-
LinkedHashMap也很适合做jvm本地缓存,本地缓存需要考虑是线程安全性和防止内存泄漏。而LinkedHashMap可以完美的实现类似于LRU缓存算法,至于LRU算法是个什么算法这里不详细说了,最经典的就是dubbo中的工具类:org.apache.dubbo.common.utils.LRUCache。LinkedHashMap的链表中越接近head部分是最老最不常用的数据,越接近tail部分是最新最常用的数据,所以在元素需要淘汰时从head开始淘汰.在实现过程中主要通过accessOrder变量和removeEldestEntry(Map.Entry
公众号同名,欢迎关注
-
-
相关阅读:
使用 Amazon Rekognition API 进行文本检测和 OCR
golang升级到1.18.4版本 遇到的问题
Oracle 19c OCP 1Z0-083题库(7-12)
行为型设计模式-状态模式
生命 周期
Webmin--一个用于Linux基于Web的系统管理工具
神经网络中卷积和池化的区别
【JVM深层系列】「云原生时代的Java虚拟机」针对于GraalVM的技术知识脉络的重塑和探究
IntelliJ IDEA 下.properties 中文乱码问题
说一下vue响应式原理?可不只有proxy
- 原文地址:https://blog.csdn.net/shidebin/article/details/126814905