-
【毕业设计】 大数据二手房数据爬取与分析可视化 -python 数据分析 可视化
1 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 基于大数据招聘岗位数据分析与可视化系统
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:5分
🧿 选题指导, 项目分享:
1 课题背景
首先通过爬虫采集链家网上所有二手房的房源数据,并对采集到的数据进行清洗;然后,对清洗后的数据进行可视化分析,探索隐藏在大量数据背后的规律;最后,采用一个聚类算法对所有二手房数据进行聚类分析,并根据聚类分析的结果,将这些房源大致分类,以对所有数据的概括总结。通过上述分析,我们可以了解到目前市面上二手房各项基本特征及房源分布情况,帮助我们进行购房决策。
2 实现效果
整体数据文件词云

各区域二手房房源数量折线图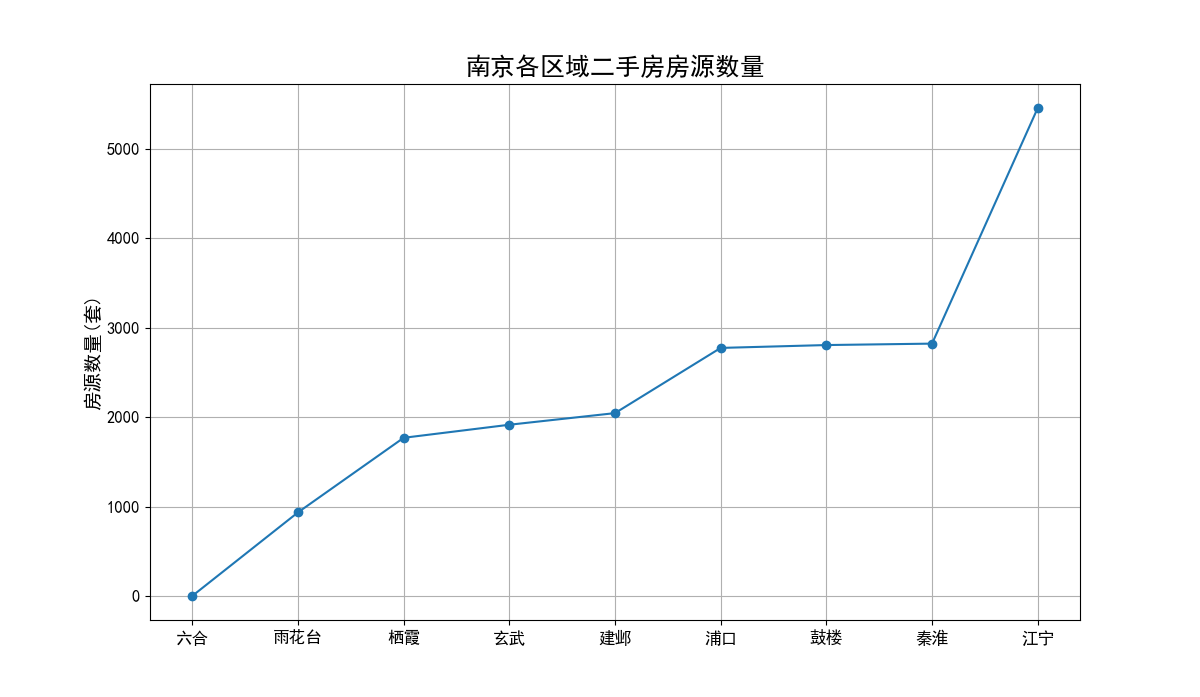
二手房房屋用途水平柱状图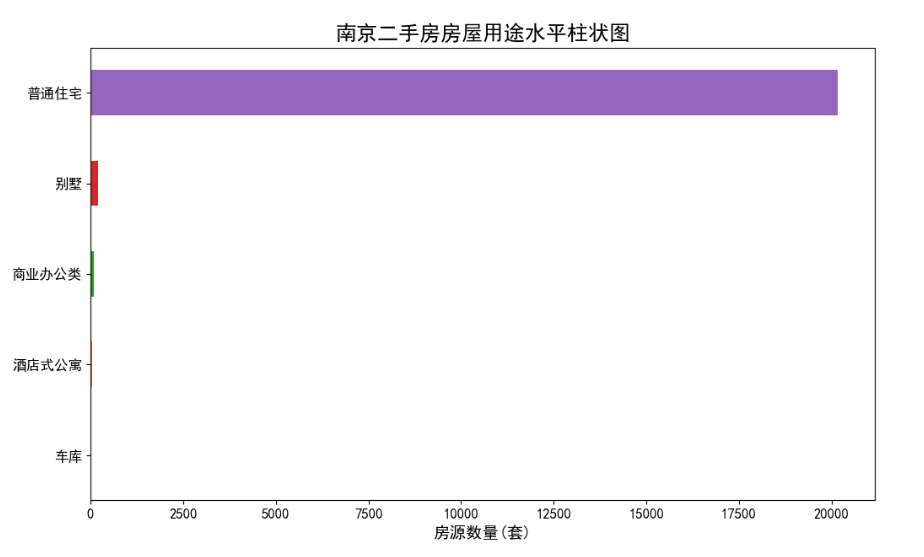
二手房基本信息可视化分析
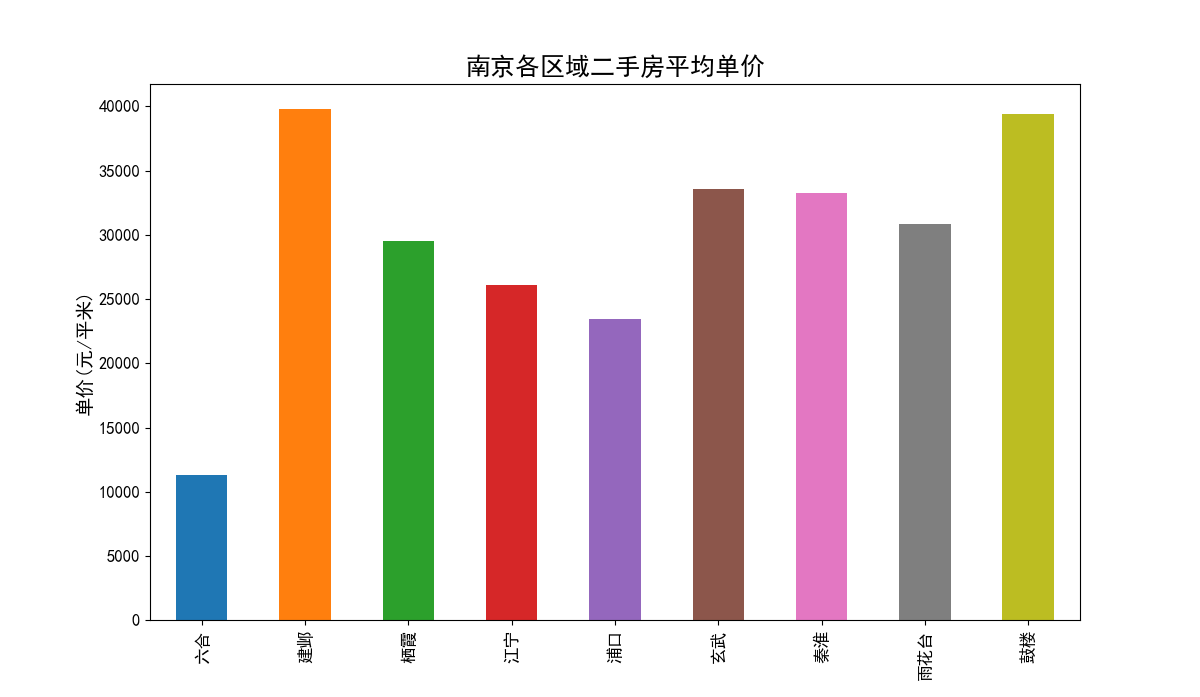
各区域二手房平均单价柱状图
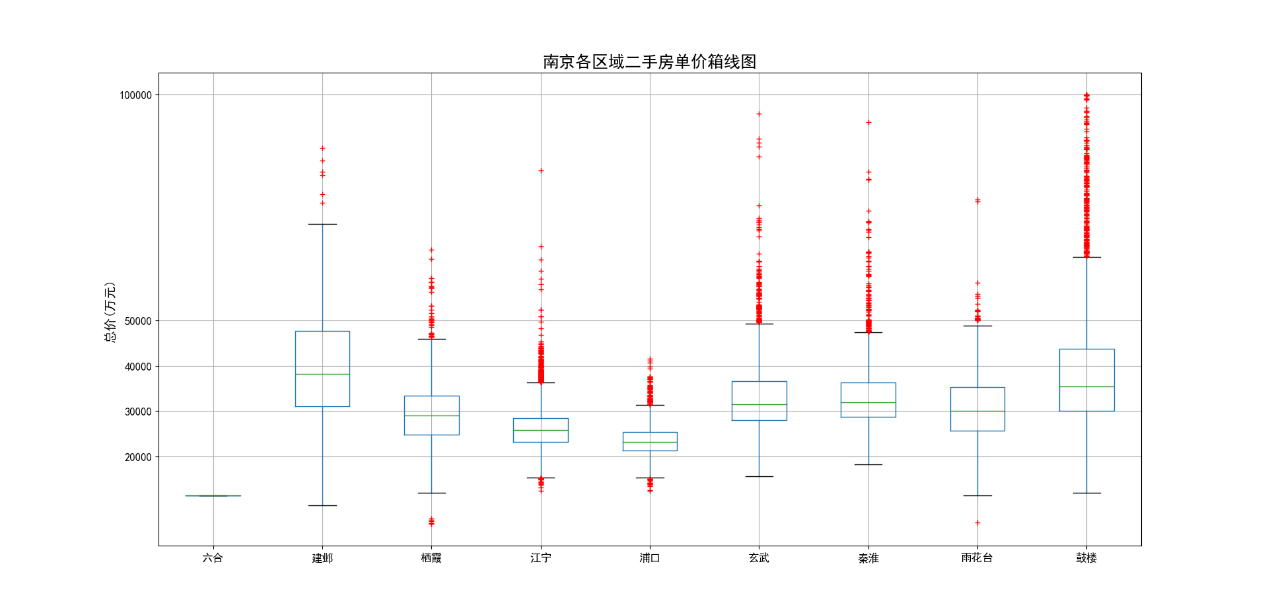
各区域二手房单价和总价箱线图
二手房单价最高Top20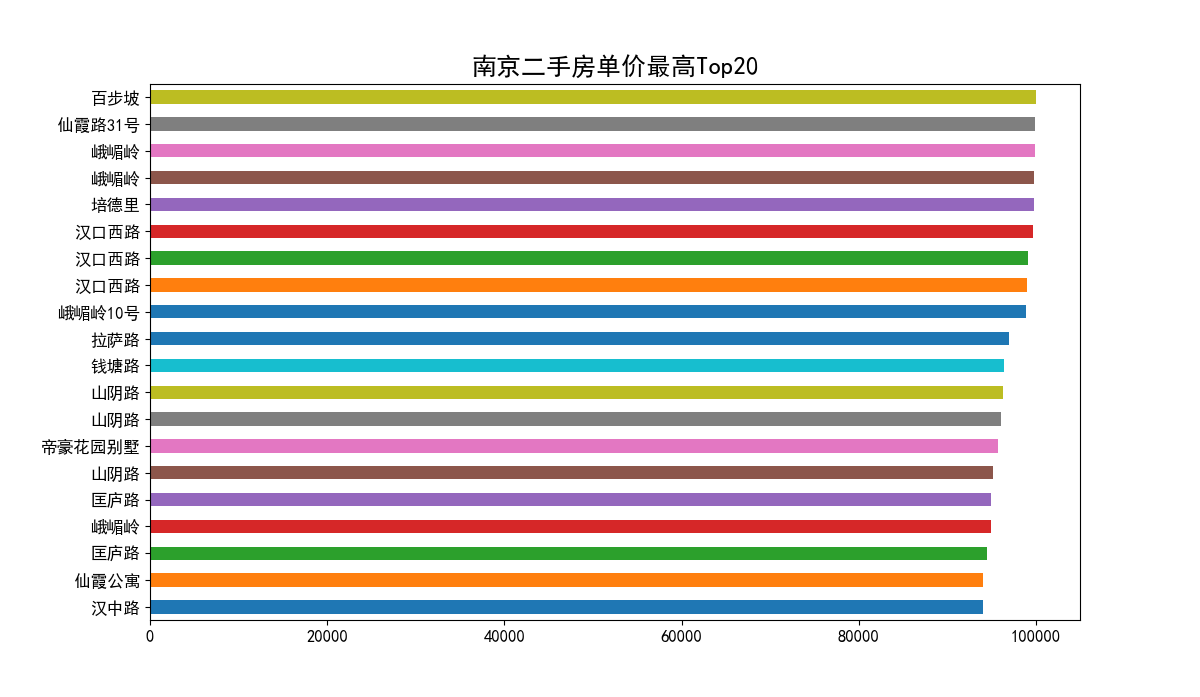
二手房单价和总价热力图

二手房单价热力图
二手房总价小于200万的分布图

二手房建筑面积分析
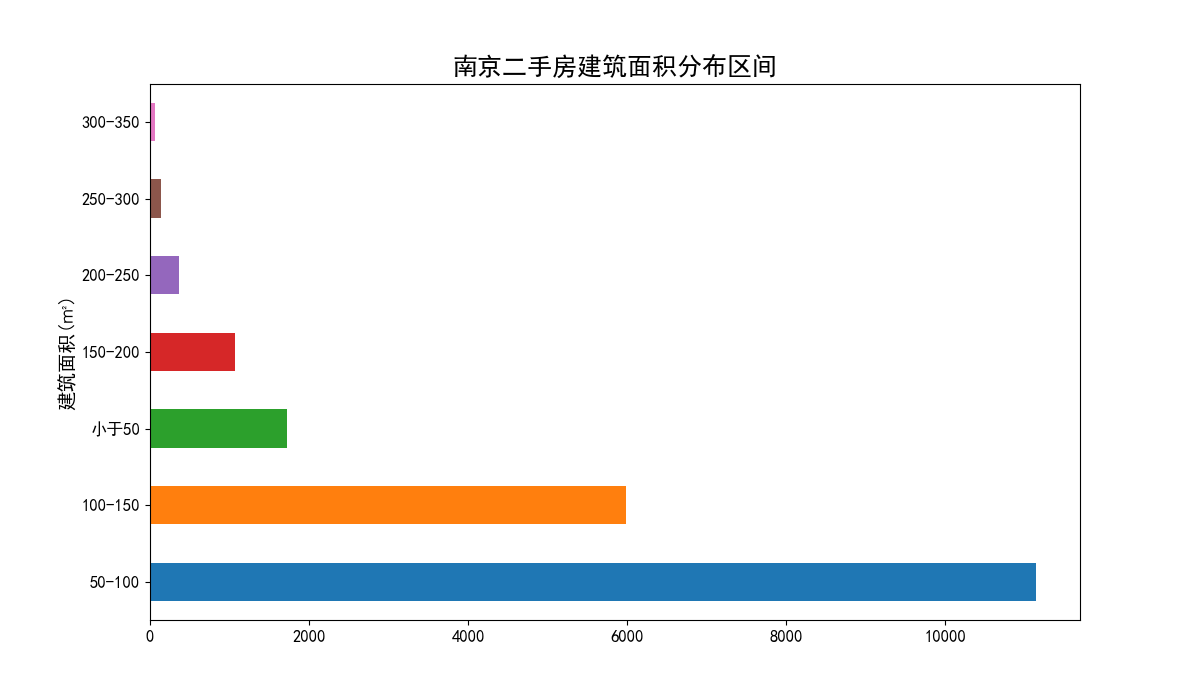
二手房建筑面积分布区间柱状图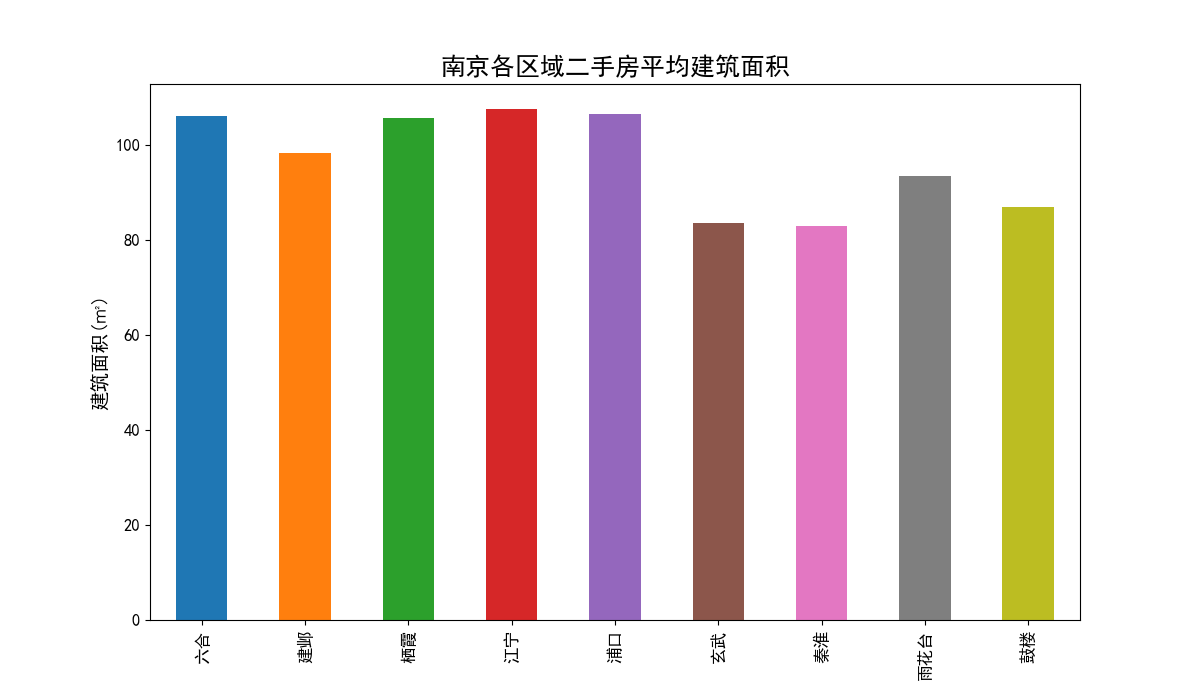
二手房房屋属性可视化分析
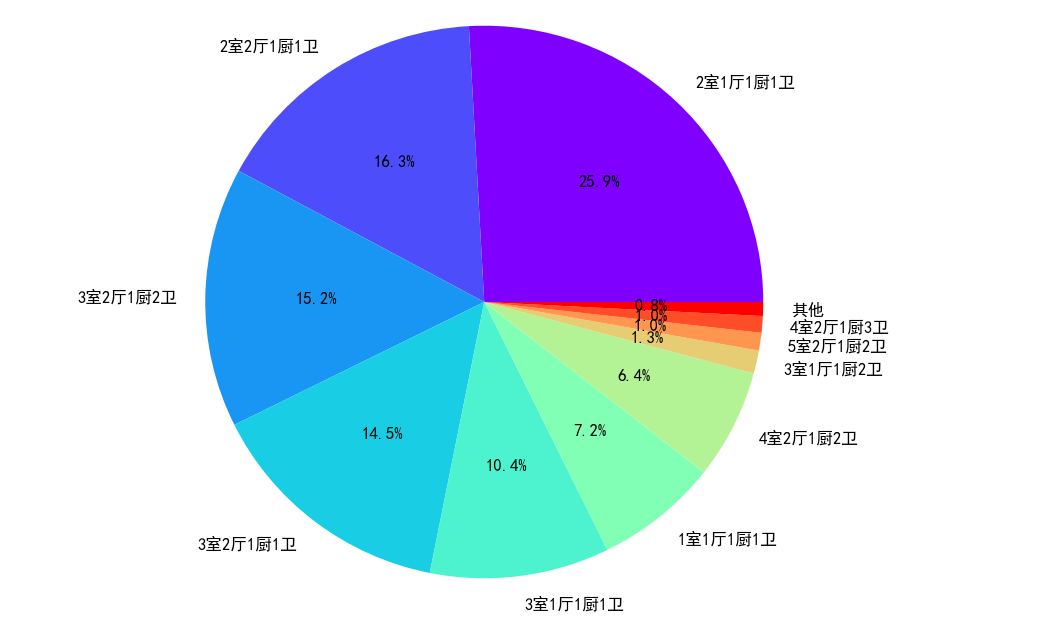
二手房房屋户型占比情况
从二手房房屋户型饼状图中可以看出,2室1厅与2室2厅作为标准配置,一共占比接近一半。其中3室2厅和3室1厅的房源也占比不少,其他房屋户型的房源占比就比较少了。
二手房房屋装修情况
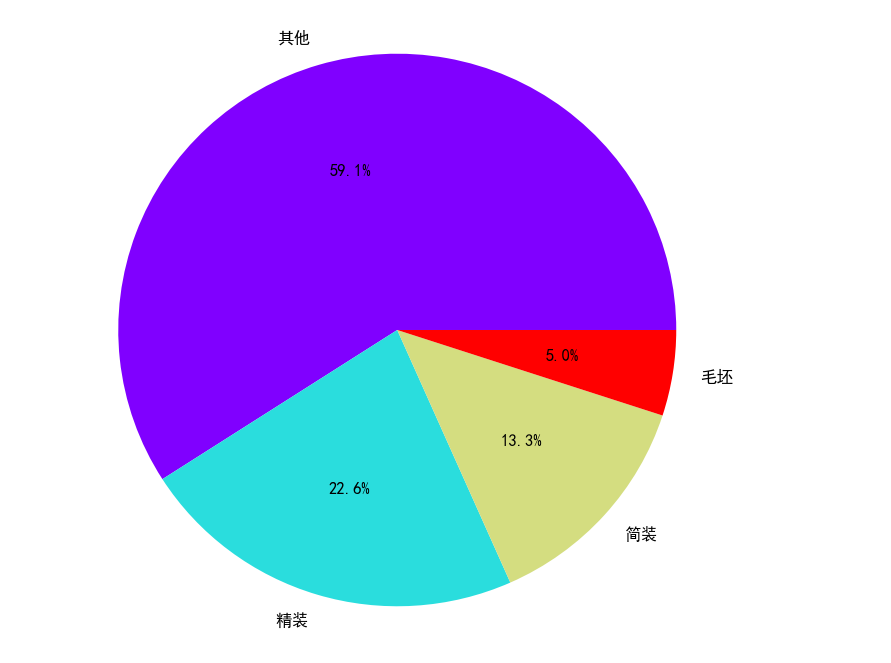
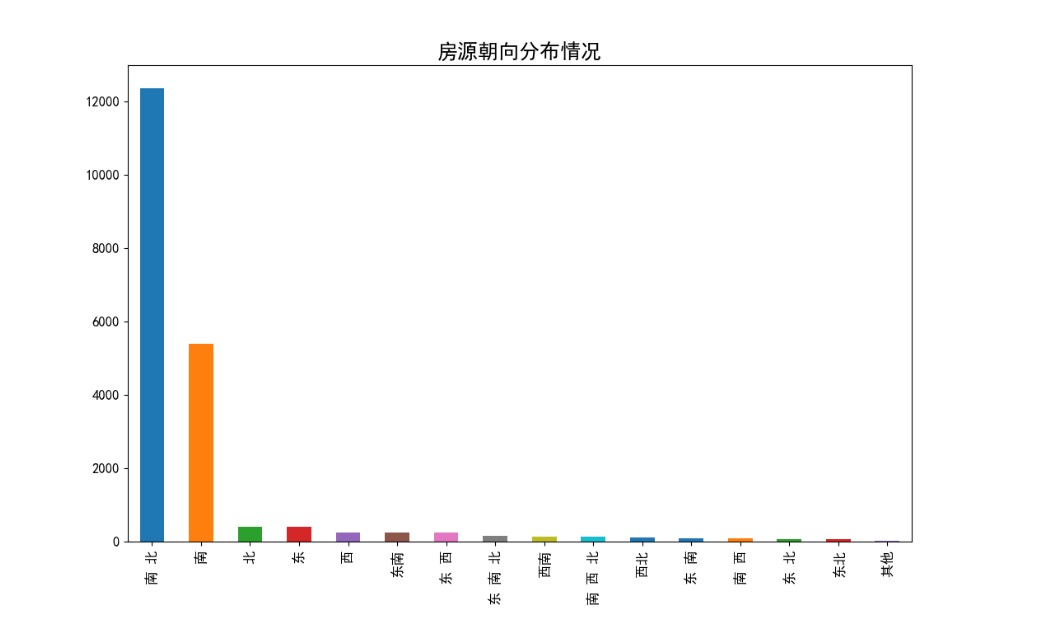
二手房房屋朝向分布情况
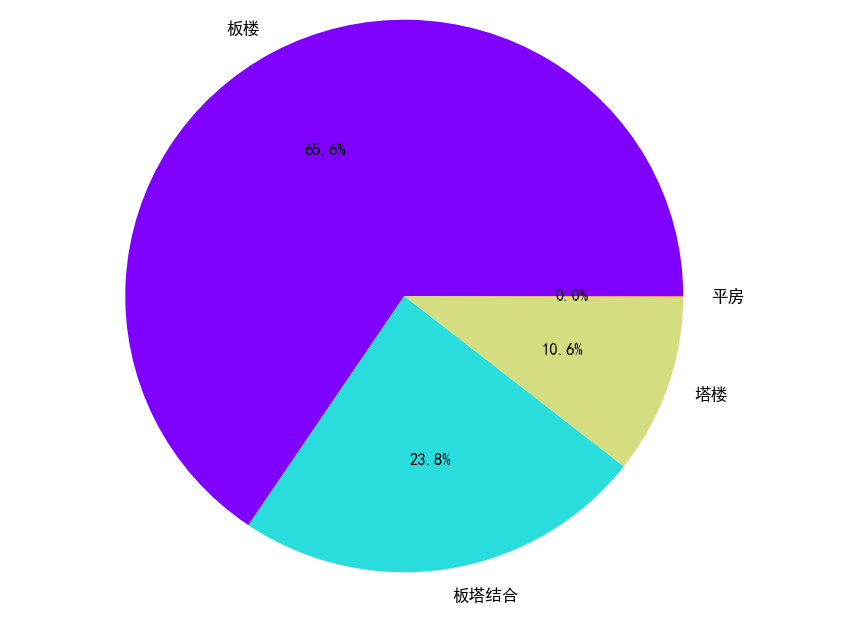
二手房建筑类型占比情况
3 数据采集
该部分通过网络爬虫程序抓取链家网上所有二手房的数据,收集原始数据,作为整个数据分析的基石。
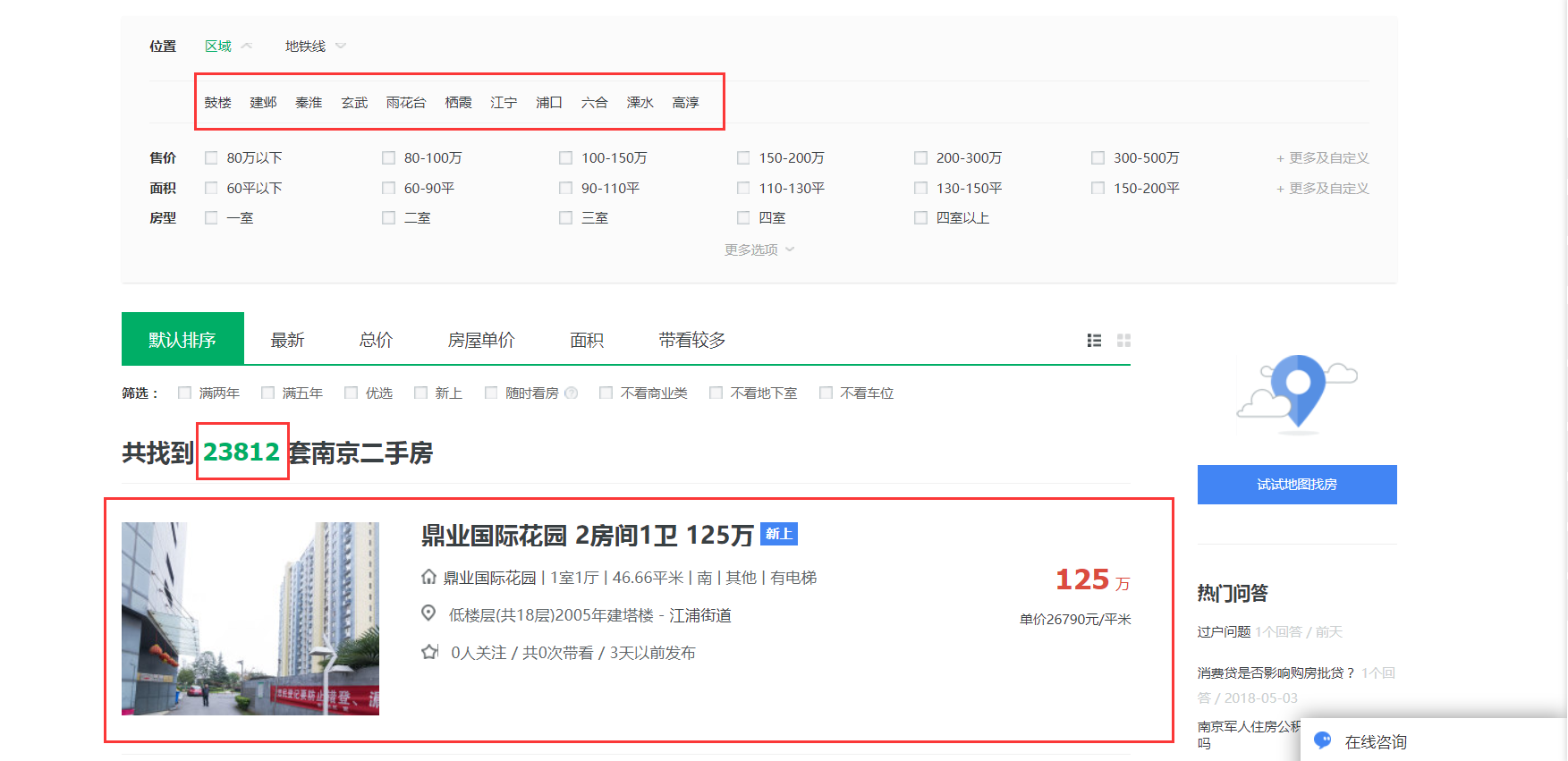
链家网网站结构分析
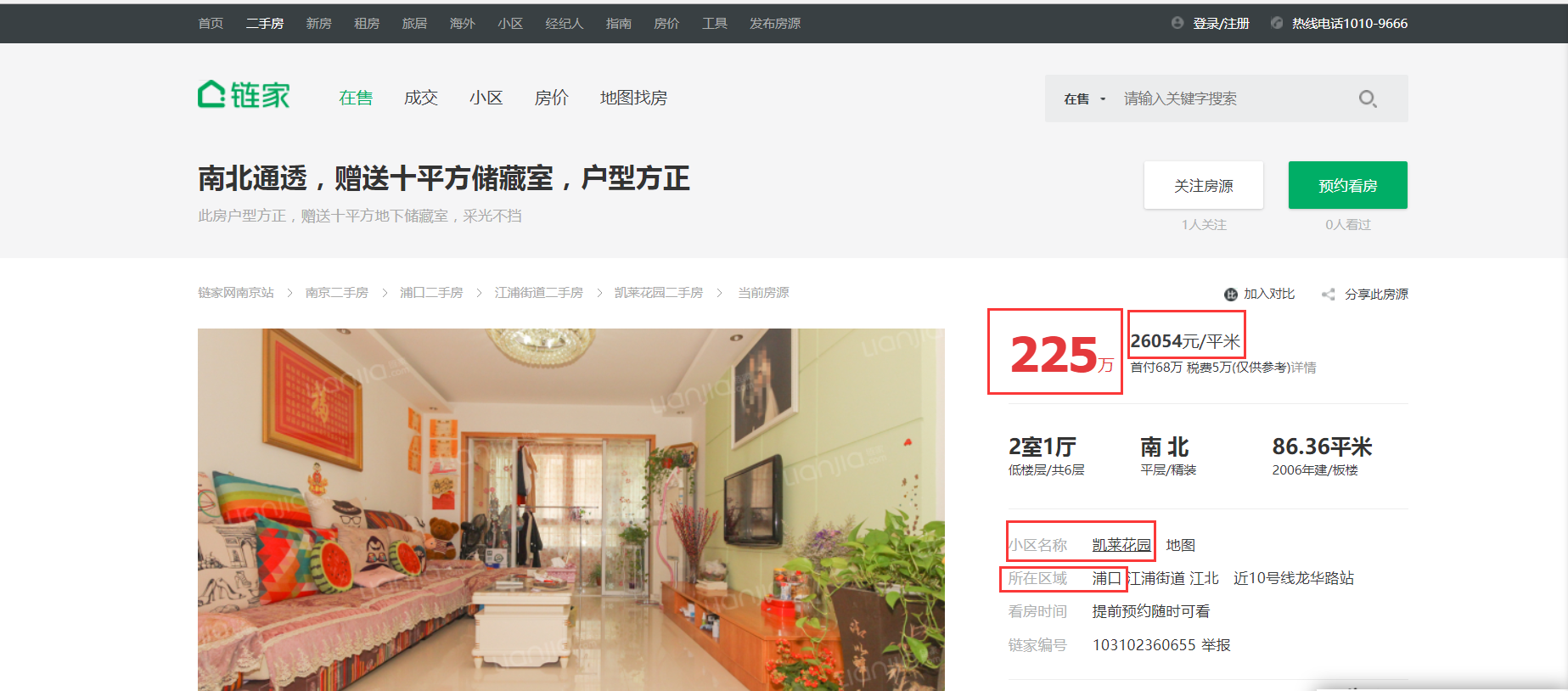
链家网二手房主页界面如下图,主页上面红色方框位置显示目前二手房在售房源的各区域位置名称,中间红色方框位置显示了房源的总数量,下面红色方框显示了二手房房源信息缩略图,该红色方框区域包含了二手房房源页面的URL地址标签。图2下面红色方框显示了二手房主页上房源的页数。
链家网二手房主页截图上半部分:
二手房房源信息页面如下图。我们需要采集的目标数据就在该页面,包括基本信息、房屋属性和交易属性三大类。各类信息包括的数据项如下:
1)基本信息:小区名称、所在区域、总价、单价。
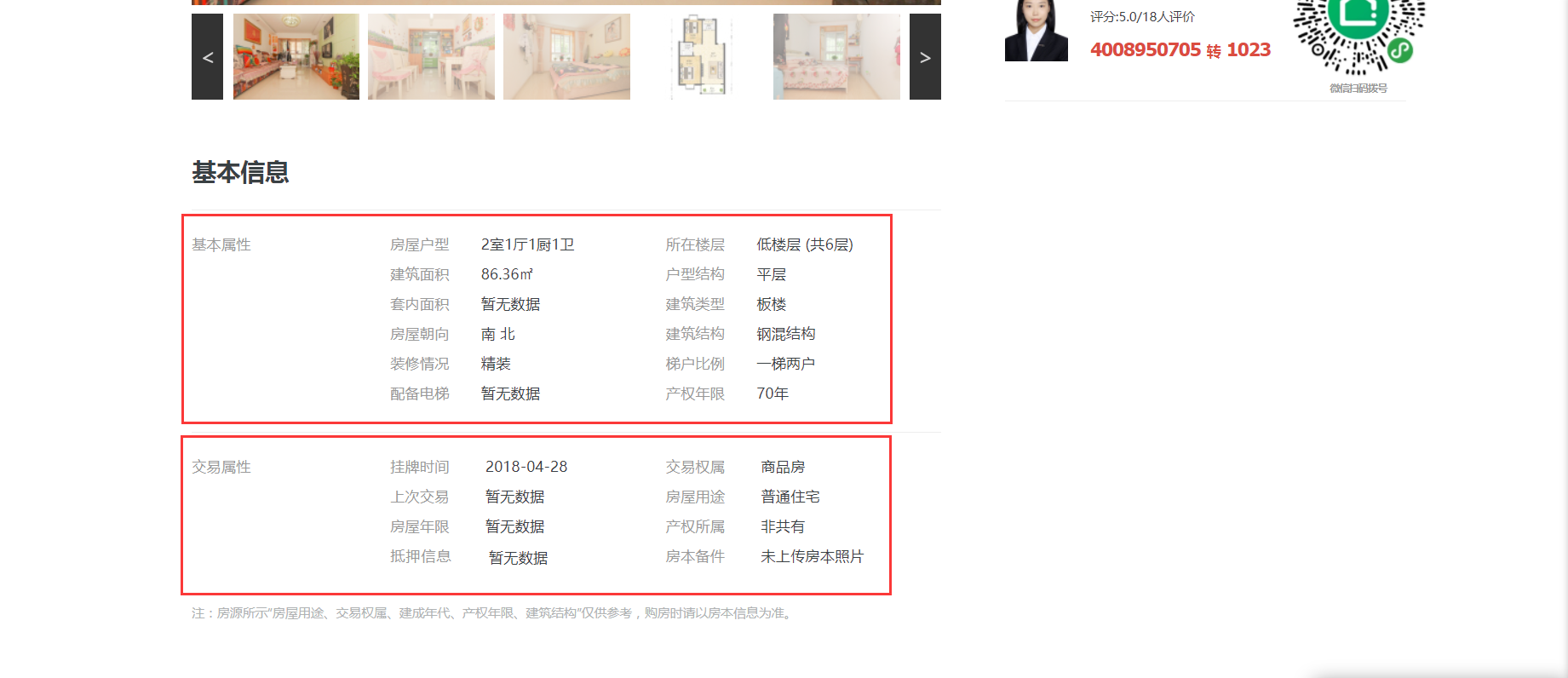
2)房屋属性:房屋户型、所在楼层、建筑面积、户型结构、套内面积、建筑类型、房屋朝向、建筑结构、装修情况、梯户比例、配备电梯、产权年限。
3)交易属性:挂牌时间、交易权属、上次交易、房屋用途、房屋年限、产权所属、抵押信息、房本备件。
网络爬虫程序关键问题说明
1)问题1:链家网二手房主页最多只显示100页的房源数据,所以在收集二手房房源信息页面URL地址时会收集不全,导致最后只能采集到部分数据。
解决措施:将所有二手房数据分区域地进行爬取,100页最多能够显示3000套房,该区域房源少于3000套时可以直接爬取,如果该区域房源超过3000套可以再分成更小的区域。
2)问题2:爬虫程序如果运行过快,会在采集到两、三千条数据时触发链家网的反爬虫机制,所有的请求会被重定向到链家的人机鉴定页面,从而会导致后面的爬取失败。
解决措施:①为程序中每次http请求构造header并且每次变换http请求header信息头中USER_AGENTS数据项的值,让请求信息看起来像是从不同浏览器发出的访问请求。②爬虫程序每处理完一次http请求和响应后,随机睡眠1-3秒,每请求2500次后,程序睡眠20分钟,控制程序的请求速度。
4 数据清洗
对于爬虫程序采集得到的数据并不能直接分析,需要先去掉一些“脏”数据,修正一些错误数据,统一所有数据字段的格式,将这些零散的数据规整成统一的结构化数据。
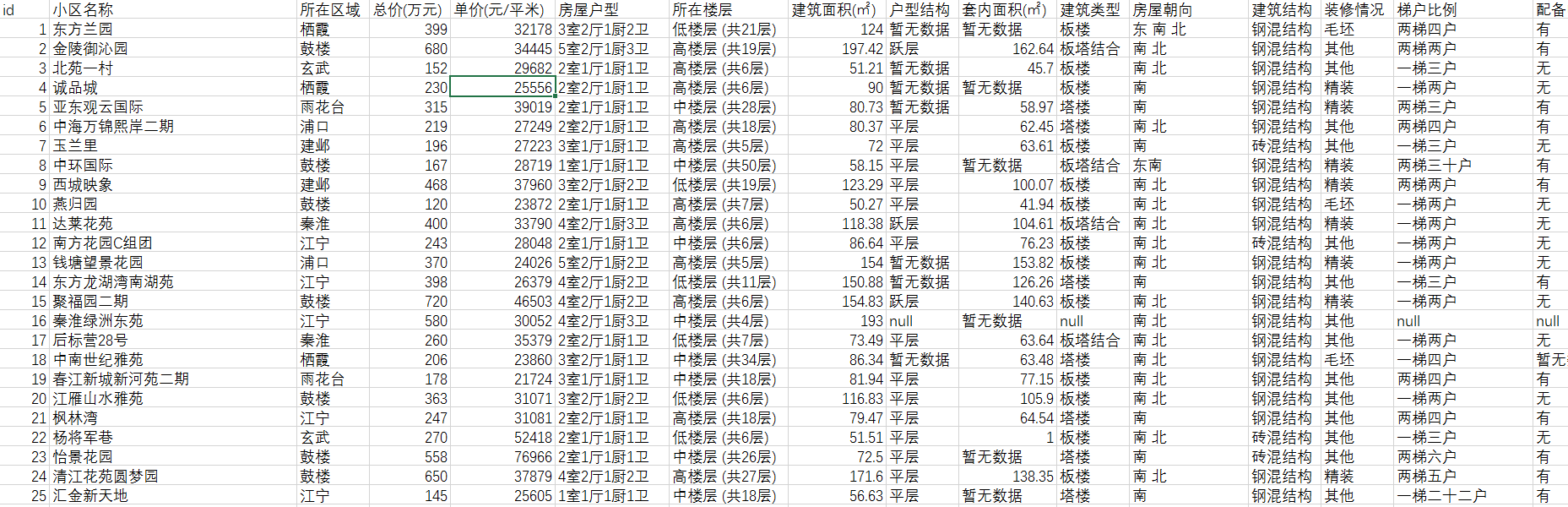
原始数据主要需要清洗的部分
主要需要清洗的数据部分如下:
1)将杂乱的记录的数据项对齐
2)清洗一些数据项格式
3)缺失值处理
3.2.3 数据清洗结果
数据清洗前原始数据如下图,

清洗后的数据如下图,可以看出清洗后数据已经规整了许多。
5 数据聚类分析
该阶段采用聚类算法中的k-means算法对所有二手房数据进行聚类分析,根据聚类的结果和经验,将这些房源大致分类,已达到对数据概括总结的目的。在聚类过程中,我们选择了面积、总价和单价这三个数值型变量作为样本点的聚类属性。
k-means算法原理
基本原理
k-Means算法是一种使用最普遍的聚类算法,它是一种无监督学习算法,目的是将相似的对象归到同一个簇中。簇内的对象越相似,聚类的效果就越好。该算法不适合处理离散型属性,但对于连续型属性具有较好的聚类效果。
聚类效果判定标准
使各个样本点与所在簇的质心的误差平方和达到最小,这是评价k-means算法最后聚类效果的评价标准。
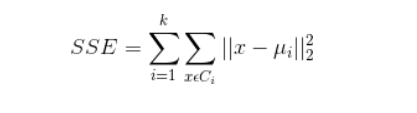
算法实现步骤
1)选定k值
2)创建k个点作为k个簇的起始质心。
3)分别计算剩下的元素到k个簇的质心的距离,将这些元素分别划归到距离最小的簇。
4)根据聚类结果,重新计算k个簇各自的新的质心,即取簇中全部元素各自维度下的算术平均值。
5)将全部元素按照新的质心重新聚类。
6)重复第5步,直到聚类结果不再变化。
7)最后,输出聚类结果。
算法缺点
虽然K-Means算法原理简单,但是有自身的缺陷:
1)聚类的簇数k值需在聚类前给出,但在很多时候中k值的选定是十分难以估计的,很多情况我们聚类前并不清楚给出的数据集应当分成多少类才最恰当。
2)k-means需要人为地确定初始质心,不一样的初始质心可能会得出差别很大的聚类结果,无法保证k-means算法收敛于全局最优解。
3)对离群点敏感。
4)结果不稳定(受输入顺序影响)。
5)时间复杂度高O(nkt),其中n是对象总数,k是簇数,t是迭代次数。
算法实现关键问题说明
K值的选定说明
根据聚类原则:组内差距要小,组间差距要大。我们先算出不同k值下各个SSE(Sum of
squared
errors)值,然后绘制出折线图来比较,从中选定最优解。从图中,我们可以看出k值到达5以后,SSE变化趋于平缓,所以我们选定5作为k值。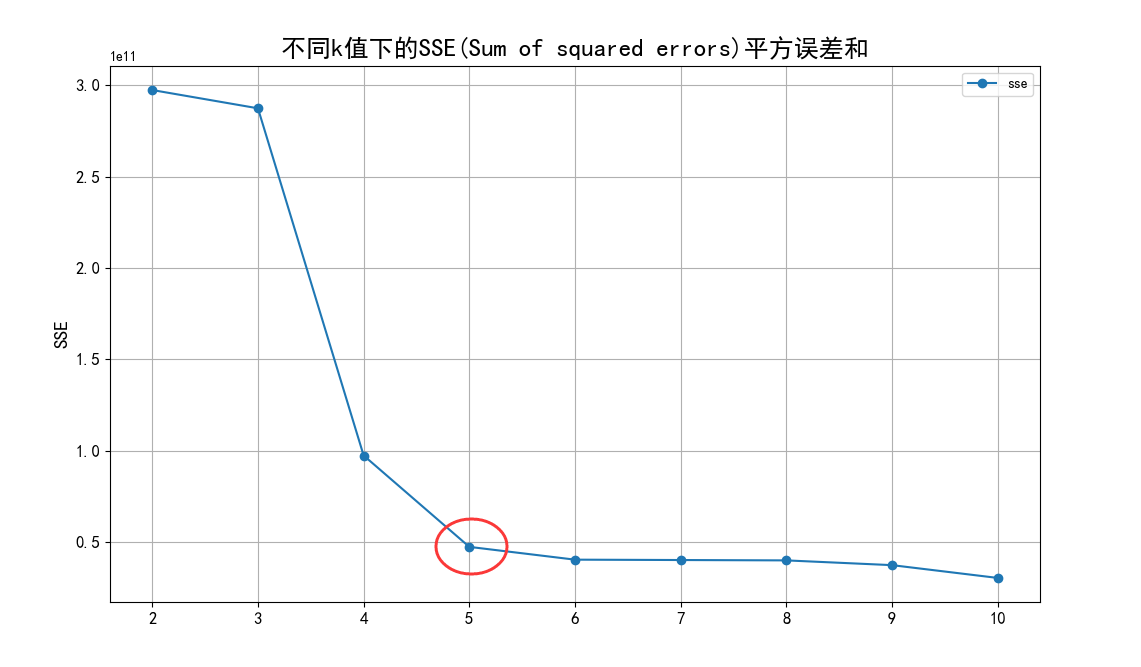
初始的K个质心选定说明
初始的k个质心选定是采用的随机法。从各列数值最大值和最小值中间按正太分布随机选取k个质心。
关于离群点
离群点就是远离整体的,非常异常、非常特殊的数据点。因为k-means算法对离群点十分敏感,所以在聚类之前应该将这些“极大”、“极小”之类的离群数据都去掉,否则会对于聚类的结果有影响。离群点的判定标准是根据前面数据可视化分析过程的散点图和箱线图进行判定。根据散点图和箱线图,需要去除离散值的范围如下:
1)单价:基本都在100000以内,没有特别的异常值。
2)总价:基本都集中在3000以内,这里我们需要去除3000外的异常值。
3)建筑面积:基本都集中在500以内,这里我们需要去除500外的异常值。
数据的标准化
因为总价的单位为万元,单价的单位为元/平米,建筑面积的单位为平米,所以数据点计算出欧几里德距离的单位是没有意义的。同时,总价都是3000以内的数,建筑面积都是500以内的数,但单价基本都是20000以上的数,在计算距离时单价起到的作用就比总价大,总价和单价的作用都远大于建筑面积,这样聚类出来的结果是有问题的。这样的情况下,我们需要将数据标准化,即将数据按比例缩放,使之都落入一个特定区间内。去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行计算和比较。
我们将单价、总价和面积都映射到500,因为面积本身就都在500以内,不要特别处理。单价在计算距离时,需要先乘以映射比例0.005,总价需要乘以映射比例0.16。进行数据标准化前和进行数据标准化后的聚类效果对比如下:图32、图33是没有数据标准化前的聚类效果散点图;图34、图35是数据标准化后的聚类效果散点图。
数据标准化前的单价与建筑面积聚类效果散点图:
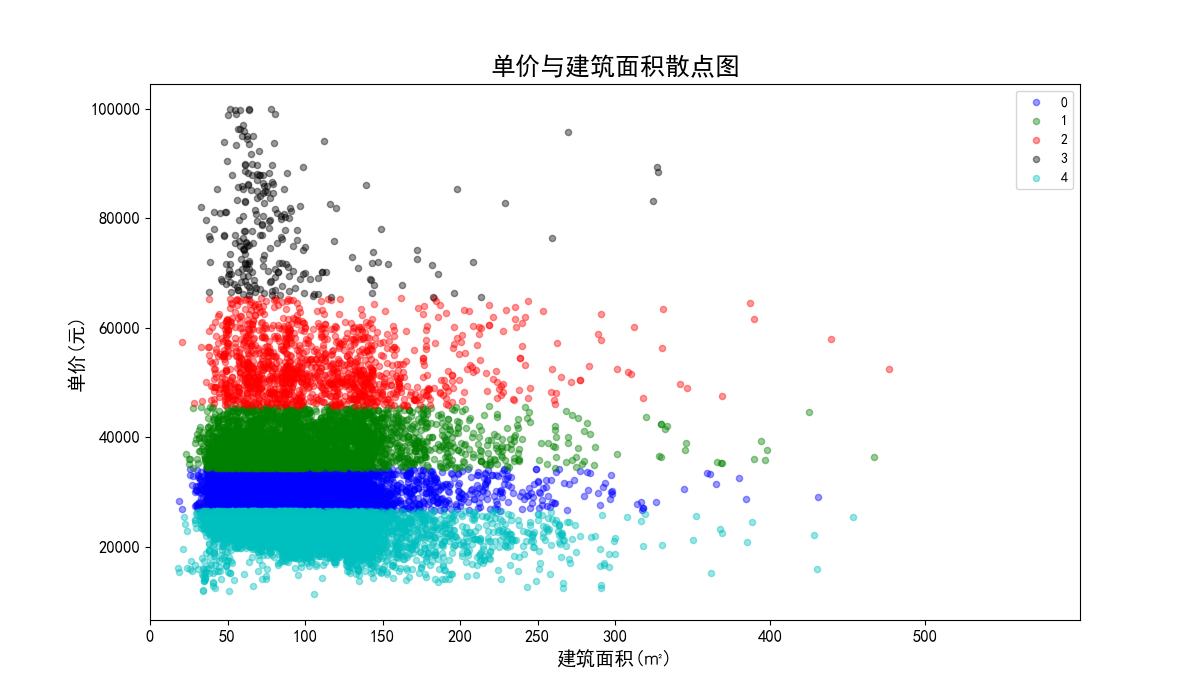
聚类结果分析
聚类结果如下
1)聚类结果统计信息如下:
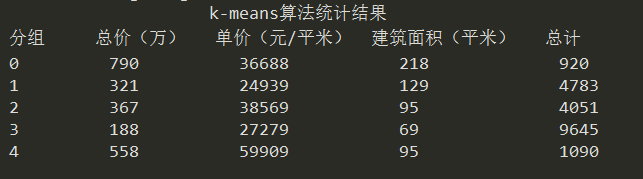
2)聚类后的单价与建筑面积散点图和总价与建筑面积散点图。
3)聚类结果分组0、1、2、3、4的区域分布图如下实例。
聚类结果分组0的区域分布图如下:

6 部分核心代码
# -*- coding: utf-8 -*- """ Created on Tue Feb 23 10:09:15 2016 K-means cluster @author: liudiwei """ import numpy as np class KMeansClassifier(): "this is a k-means classifier" def __init__(self, k=3, initCent='random', max_iter=5000): """构造函数,初始化相关属性""" self._k = k self._initCent = initCent#初始中心 self._max_iter = max_iter#最大迭代 #一个m*2的二维矩阵,矩阵第一列存储样本点所属的族的索引值, #第二列存储该点与所属族的质心的平方误差 self._clusterAssment = None#样本点聚类结结构矩阵 self._labels = None self._sse = None#SSE(Sum of squared errors)平方误差和 def _calEDist(self, arrA, arrB): """ 功能:欧拉距离距离计算 输入:两个一维数组 """ arrA_temp = arrA.copy() arrB_temp = arrB.copy() arrA_temp[0] = arrA_temp[0]*0.16 arrA_temp[1] = arrA_temp[1]*0.005 arrB_temp[0] = arrB_temp[0]*0.16 arrB_temp[1] = arrB_temp[1]*0.005 return np.math.sqrt(sum(np.power(arrA_temp - arrB_temp, 2))) def _calMDist(self, arrA, arrB): """ 功能:曼哈顿距离距离计算 输入:两个一维数组 """ return sum(np.abs(arrA-arrB)) def _randCent(self, data_X, k): """ 功能:随机选取k个质心 输出:centroids #返回一个m*n的质心矩阵 """ n = data_X.shape[1] - 3 #获取特征值的维数(要删除一个用于标记的id列和经纬度值) centroids = np.empty((k,n)) #使用numpy生成一个k*n的矩阵,用于存储质心 for j in range(n): minJ = min(data_X[:,j+1]) rangeJ = max(data_X[:,j+1] - minJ) #使用flatten拉平嵌套列表(nested list) centroids[:, j] = (minJ + rangeJ * np.random.rand(k, 1)).flatten() return centroids def fit(self, data_X): """ 输入:一个m*n维的矩阵 """ if not isinstance(data_X, np.ndarray) or \ isinstance(data_X, np.matrixlib.defmatrix.matrix): try: data_X = np.asarray(data_X) except: raise TypeError("numpy.ndarray resuired for data_X") m = data_X.shape[0] #获取样本的个数 #一个m*2的二维矩阵,矩阵第一列存储样本点所属的族的编号, #第二列存储该点与所属族的质心的平方误差 self._clusterAssment = np.zeros((m,2)) #创建k个点,作为起始质心 if self._initCent == 'random': self._centroids = self._randCent(data_X, self._k) clusterChanged = True #循环最大迭代次数 for _ in range(self._max_iter): #使用"_"主要是因为后面没有用到这个值 clusterChanged = False for i in range(m): #将每个样本点分配到离它最近的质心所属的族 minDist = np.inf #首先将minDist置为一个无穷大的数 minIndex = -1 #将最近质心的下标置为-1 for j in range(self._k): #次迭代用于寻找元素最近的质心 arrA = self._centroids[j,:] arrB = data_X[i,1:4] distJI = self._calEDist(arrA, arrB) #计算距离 if distJI < minDist: minDist = distJI minIndex = j if self._clusterAssment[i, 0] != minIndex or self._clusterAssment[i, 1] > minDist**2: clusterChanged = True self._clusterAssment[i,:] = minIndex, minDist**2 if not clusterChanged:#若所有样本点所属的族都不改变,则已收敛,结束迭代 break for i in range(self._k):#更新质心,将每个族中的点的均值作为质心 index_all = self._clusterAssment[:,0] #取出样本所属簇的编号 value = np.nonzero(index_all==i) #取出所有属于第i个簇的索引值 ptsInClust = data_X[value[0]] #取出属于第i个簇的所有样本点 self._centroids[i,:] = np.mean(ptsInClust[:,1:4], axis=0) #计算均值,赋予新的质心 self._labels = self._clusterAssment[:,0] self._sse = sum(self._clusterAssment[:,1]) def predict(self, X):#根据聚类结果,预测新输入数据所属的族 #类型检查 if not isinstance(X,np.ndarray): try: X = np.asarray(X) except: raise TypeError("numpy.ndarray required for X") m = X.shape[0]#m代表样本数量 preds = np.empty((m,)) for i in range(m):#将每个样本点分配到离它最近的质心所属的族 minDist = np.inf for j in range(self._k): distJI = self._calEDist(self._centroids[j,:], X[i,:]) if distJI < minDist: minDist = distJI preds[i] = j return preds class biKMeansClassifier(): "this is a binary k-means classifier" def __init__(self, k=3): self._k = k self._centroids = None self._clusterAssment = None self._labels = None self._sse = None def _calEDist(self, arrA, arrB): """ 功能:欧拉距离距离计算 输入:两个一维数组 """ return np.math.sqrt(sum(np.power(arrA-arrB, 2))) def fit(self, X): m = X.shape[0] self._clusterAssment = np.zeros((m,2)) centroid0 = np.mean(X, axis=0).tolist() centList =[centroid0] for j in range(m):#计算每个样本点与质心之间初始的平方误差 self._clusterAssment[j,1] = self._calEDist(np.asarray(centroid0), \ X[j,:])**2 while (len(centList) < self._k): lowestSSE = np.inf #尝试划分每一族,选取使得误差最小的那个族进行划分 for i in range(len(centList)): index_all = self._clusterAssment[:,0] #取出样本所属簇的索引值 value = np.nonzero(index_all==i) #取出所有属于第i个簇的索引值 ptsInCurrCluster = X[value[0],:] #取出属于第i个簇的所有样本点 clf = KMeansClassifier(k=2) clf.fit(ptsInCurrCluster) #划分该族后,所得到的质心、分配结果及误差矩阵 centroidMat, splitClustAss = clf._centroids, clf._clusterAssment sseSplit = sum(splitClustAss[:,1]) index_all = self._clusterAssment[:,0] value = np.nonzero(index_all==i) sseNotSplit = sum(self._clusterAssment[value[0],1]) if (sseSplit + sseNotSplit) < lowestSSE: bestCentToSplit = i bestNewCents = centroidMat bestClustAss = splitClustAss.copy() lowestSSE = sseSplit + sseNotSplit #该族被划分成两个子族后,其中一个子族的索引变为原族的索引 #另一个子族的索引变为len(centList),然后存入centList bestClustAss[np.nonzero(bestClustAss[:,0]==1)[0],0]=len(centList) bestClustAss[np.nonzero(bestClustAss[:,0]==0)[0],0]=bestCentToSplit centList[bestCentToSplit] = bestNewCents[0,:].tolist() centList.append(bestNewCents[1,:].tolist()) self._clusterAssment[np.nonzero(self._clusterAssment[:,0] == \ bestCentToSplit)[0],:]= bestClustAss self._labels = self._clusterAssment[:,0] self._sse = sum(self._clusterAssment[:,1]) self._centroids = np.asarray(centList) def predict(self, X):#根据聚类结果,预测新输入数据所属的族 #类型检查 if not isinstance(X,np.ndarray): try: X = np.asarray(X) except: raise TypeError("numpy.ndarray required for X") m = X.shape[0]#m代表样本数量 preds = np.empty((m,)) for i in range(m):#将每个样本点分配到离它最近的质心所属的族 minDist = np.inf for j in range(self._k): distJI = self._calEDist(self._centroids[j,:],X[i,:]) if distJI < minDist: minDist = distJI preds[i] = j return preds- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
7 最后
-
相关阅读:
基于emp的mysql查询
Banana Pi BPI-W3之RK3588安装Qt+opencv+采集摄像头画面.
使用微信小程序播放视频直播
JS 模块化- 04 CMD 规范与 Sea JS
java 转换word doc docx 等office文档 为pdf,无需破解 aspose ,无水印
【Python】从入门到上头—mysql数据库操作模块mysql-connector和PyMySQL应用场景 (15)
Ubuntu22.04 部署Mqtt服务器
汽车自适应巡航系统控制策略研究
Linux下,使用nm命令输出可执行文件的符号表
C/C++中的协程
- 原文地址:https://blog.csdn.net/HUXINY/article/details/126815146
